Chapter 9
Streams
1. CUDA Stream
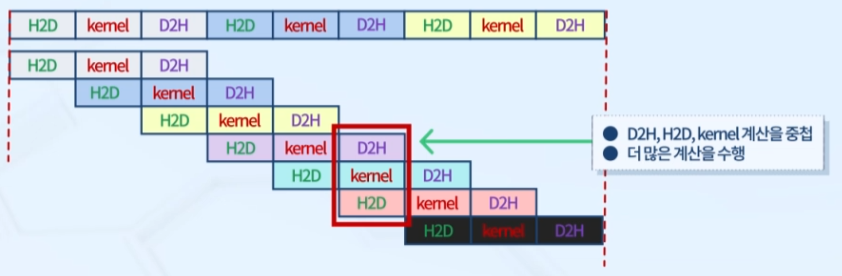
비동기 시퀀스
- 호스트 코드에서 기술된 순서대로 디바이스에서 실행되는 비동기 CUDA 연산의 시퀀스
- 디바이스 연산을 기능별로 겹쳐 실행되도록 함
- 스트림에서 연산의 실행은 항상 호스트에 대해서 비동기적으로 동작
- 유효 자원을 최대한 활용하는 방안 (≒ CPU pipelining)
- Marker 함수를 통한 동기화와 상태 측정 가능
동일/비동일 스트림
- 동일한 스트림 내에서의 연산은 순차 실행이 보장됨
- 다른 스트림에 있는 연산은 실행 순서에 제한 X
One Device Multiple Streams
- 하나의 디바이스는 여러 개의 스트림을 가질 수 있음
- CUDA 스트림에 큐잉된 모든 연산들은 비동기 연산 -> 호스트-디바이스 시스템의 다른 연산과 중첩 가능
- 커널 실행과 데이터 전달을 다른 스트림에 배치
2. NULL/non-NULL stream
NULL stream
- 명시적으로 지정하지 않으면 커널 실행과 데이터 전달이 사용하는 default stream
- 모든 CUDA 연산은 스트림에서 명시적 혹은 묵시적으로 실행됨
- CUDA 연산이 중첩되지 않도록 작동 -> 안정성 확보
non-NULL stream
- 명시적으로 생성되고 관리됨
- 다른 CUDA 연산들과 중첩을 원하면 non-NULL stream을 사용해야 함
3. 비동기 스트림 생성/해제
cudaStreamCreate() : 비동기 스트림 생성
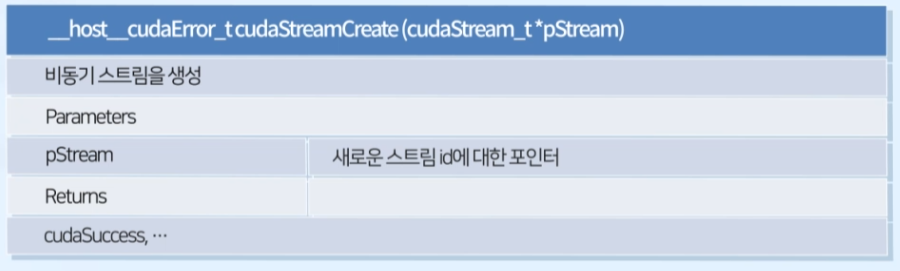
- 생성된 스트림은
cudaMemcpyAsync()와 다른 비동기 CUDA API 함수에서 사용
cudaStreamDestroy() : 비동기 스트림 해제

- 실행 즉시 반환되고 스트림에 남아있는 연산이 있다면 연산이 끝난 후 자원 반납
cudaMemcpyAsync() : 호스트와 디바이스 사이에서 데이터를 복사 (비동기 연산)

- 이 다음에 오는 연산은 중첩 실행이 가능해짐
- 복사가 완료되기 전에 return (다음으로 넘어감)
- 비동기 데이터 전달 시 반드시 pinned memory 사용
cudaMallocHost(),cudaHostAlloc()
커널 런칭
Kernel_name<<<grid, block, sharedMemsize, stream>>>(argument list);cudaStreamSynchronize(): 스트림 동기화

- 해당 스트림에 있는 작업이 완료될 때까지 대기

올해는 진짜 갓생 산다