Chapter 1
Parallel Programming Models
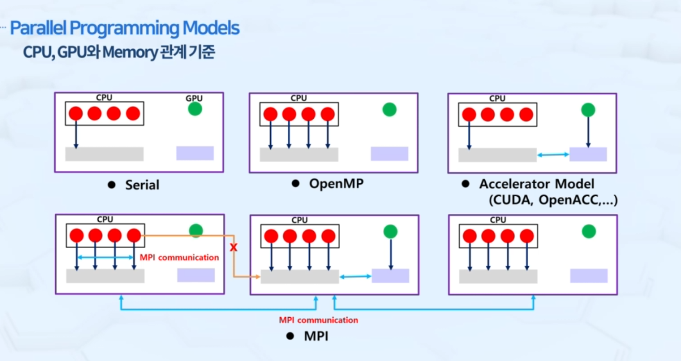
1. Serial
코어 하나가 순차적으로 프로그램 순서에 따라서만 계산 수행
2. OpenMP
코어 각각이 독립적인 계산 동시 수행
3. Accelerator Model(CUDA, OpenACC..)
CPU쪽에서 계산을 하다가 loop 또는 hotspot 같은 부분을 가속기(GPU)가 할당을 받아 독립적으로 수행 후 결과값을 return
4. MPI
여러 개의 노드(여러 대의 본체)로 구성된 슈퍼컴퓨터 혹은 클러스터에서 사용. 노드 간의 데이터를 주고받는 통신 담당.
Programming Model for Heterogeneous System: CUDA
1. 특징
가속기 == 보조적 계산 장치
- GPU로만 구성된 장치는 없음
- GPU를 사용하더라도 CPU가 있는 시스템에서 CPU로 사용하는 방법만 쓸 수 있음
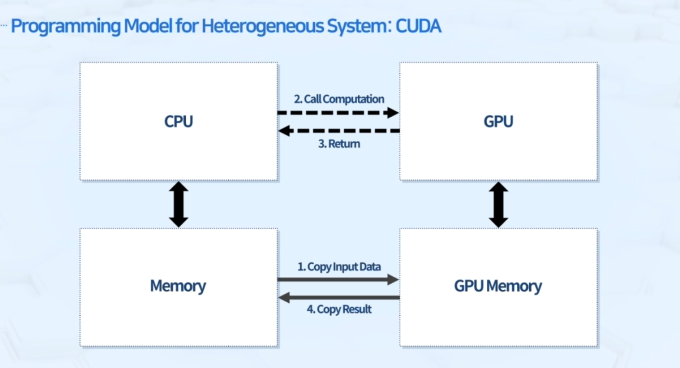
오프로드 방식
- 메인 프로그램은 CPU에서 진행하되, 계산 자원이 많이 필요한 부분을 GPU에 할당해줌
메모리 구조
- CPU 코어끼리는 한 노드안에서는 메모리 공유
- GPU는 독립적인 메모리가 내장되어 있어 작업 할당 시 CPU와 GPU 메모리 간의 데이터 copy와 저장공간 할당이 필요함
2. Hello World (CUDA)

helloFromGPU<<<1,10>>>();-
10개의 코어가
printf("Hello World From GPU\n");문을 동시에 수행 -
OpenMP, MPI는 수행 주체가 CPU 코어인 반면, CUDA의 kerenl 함수는 GPU 장치에서 실행 (Heterogeneous Programming)
3. 구조
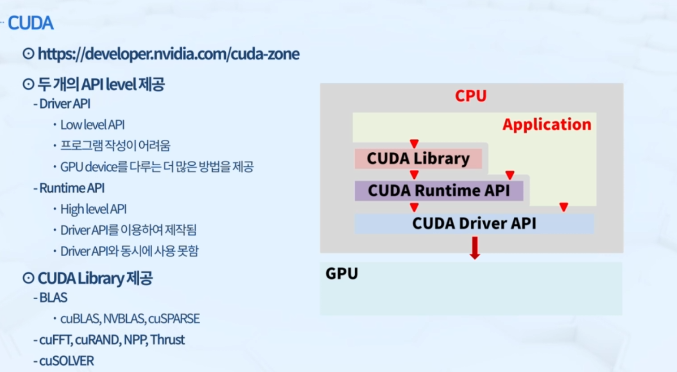
- API 레벨에서 Driver와 Runtime 필요
GPU 구동을 위해 Driver가 필요함 - Library는 필요에 따라서 활용
4. CUDA Programming Model
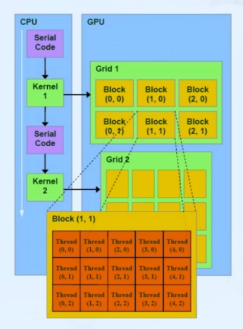
host: CPU & 시스템 메모리
- 제어 집약적인 작업 담당
device: GPU & GPU 메모리
- kernel: 디바이스에서 실행되는 병렬 코드
- 데이터 병렬 계산 작업 담당
GPU
1. CPU vs GPU
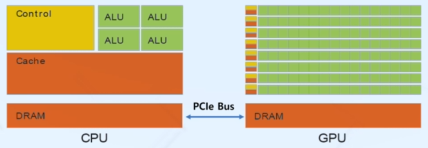
CPU: Low Latency, Low Throughput
- Low latency 위한 큰 cache 필요
low latency = 반응 속도가 빠르다, 지연시간이 작다 = 어떤 일을 시켰을 때 즉각적으로 답을 낼 수 있다 - Tens of ALUs(ILP가 제한적)
서버용 CPU라 해도 100개 이내의 코어를 가지게 됨 - 복잡한 분기처리, 비 순차(out-of-order), Speculative 실행 등 범용 목적
GPU: High Latency, High Throughput
- latency 영향 적게 받는 작업을 위해 디자인 -> 큰 cache 불필요
그래픽 랜더링을 위한 전문장치로 개발됨 - 더 많은 ALUs -> 계산 위해 더 많은 스레드 실행
몇 천개, 몇 만개의 코어를 가짐 - 데이터 병렬성을 갖는 단순 계산 실행에 최적
2. Data Parallelism in GPU
CPU: SIMD
- Single Instruction Multiple Data
- Data를 CPU 코어에 static하게 처리
ex. 1만개의 data를 10개의 코어가 처리 -> 한 코어 당 1000개의 data 처리
GPU: SIMT
- Single Instruction Multiple Threads
- 서로 다른 데이터에 동일한 연산 수행
- Data를 Thread 하나에 1대1로 매칭
- 하드웨어에 의한 스레드 스케줄 및 관리
스레드 묶음(batch of threads) 기준 프로그래밍

올해는 진짜 갓생 산다