Chapter 2
GPU Architecture
1. NVIDIA GPU
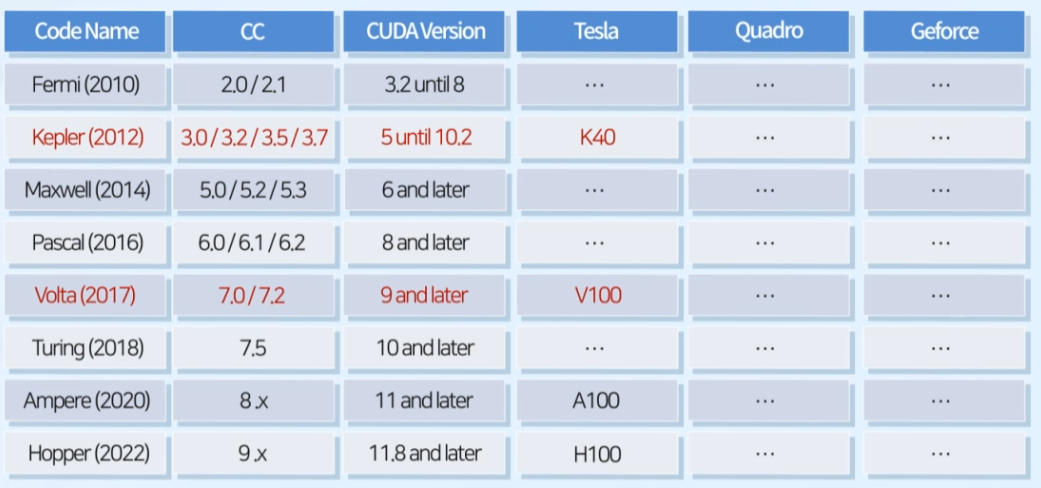
- Tesla: for Supercomputer (GPGPU)
- Quadro: for Workstation (rendering, CAD)
- GeForce: for Desktop (gaming)
2. GPU Architecture Overview
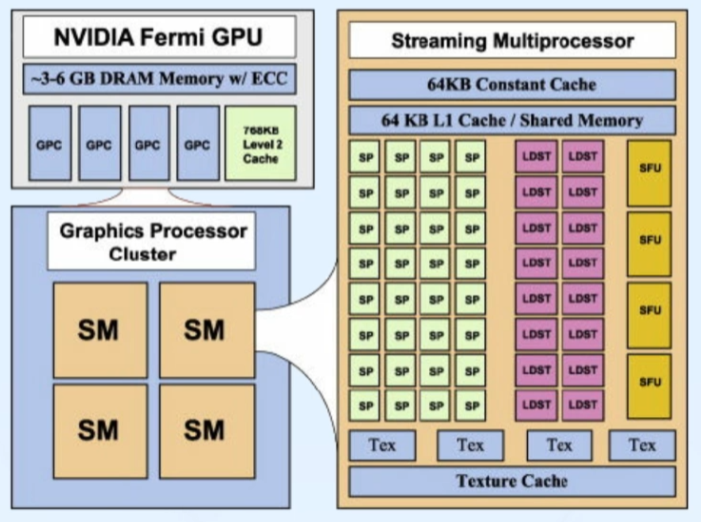
계층적 구조
- GPU: Streaming Multiprocessors(SM)으로 구성
- SM: Streaming Processor(SP) 코어로 구성
- SP: Streaming Processor
CUDA core와 같은 개념 - 효율적인 프로그램 구동을 위해 제품에 명시된 스펙을 참고하여 그루핑 등 노력을 할 필요가 있음
3. CUDA Programming Model
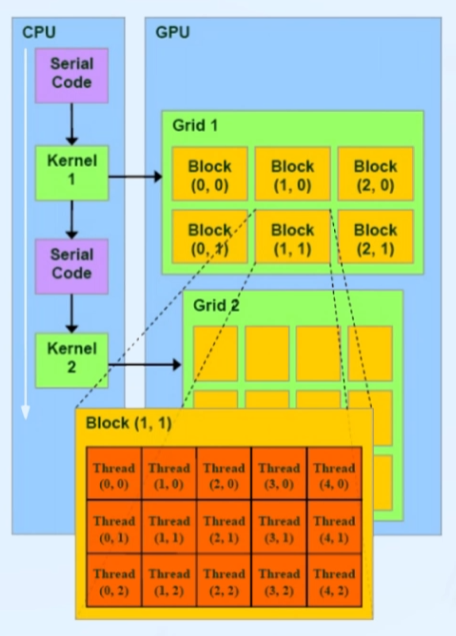
커널(Kernel)
- GPU에서 실행되는 병렬 코드 부분
- 스레드 블록의 그리드로 실행
그리드(Grid)
- 스레드 블록 모음(최대 3차원)
블록(Blocks)
- 스레드 모음(최대 3차원)
- 블록들 사이 동기화 없음
스레드(Threads)
- 공유 메모리 통해 데이터 공유
- 블록 내에서 실행 동기화
4. CUDA Execution Model
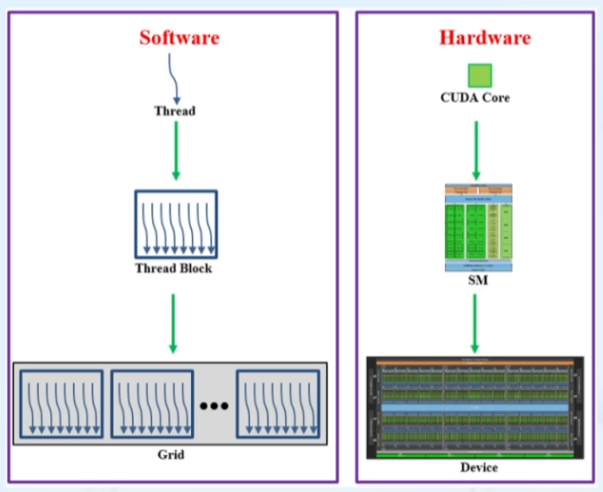
커널 실행 -> 그리드의 스레드 블록이 가용 SM에 분배되어 실행
- 스레드 블록 단위 SM에 분배
- SM = Streaming Multiprocessors
하나의 SM에 여러 블록 대응
블록 수(or 스레드 수) > 디바이스 자원(CUDA cores)
- 제한: Max # of Thread Blocks per SM,... -> Compute Capability
1 Warp = 32 Threads
- SM에서 32개 스레드 단위로 동시에 같은 명령 실행 (SIMT: Single Instruction Multi Threads)
- Data를 Warp 단위로 스케줄링 해서 최종적으로는 디바이스 자원(core) 전체에서 실행이 되도록 함
CUDA Compiler
1. nvcc
- Cuda Compiler
- 확장자 .cu를 가진 CUDA 소스 코드를 컴파일 하기 위해 사용
2. Options
대부분의 옵션은 일반 컴파일러 옵션과 동일
ex. -, -c, -o, -l, -L, -D
- -x{c | c++ | cu}: 소스 파일의 language를 명시적으로 지정
- -G: device code에 대한 debug 정보 생성
- -arch: NVIDIA GPU architecture를 지정
ex. -arch=sm_70 - -maxrregcount: 커널이 사용 가능한 레지스터 개수 지정
ex. -maxrregcount=10 - -fmad: multiply-add의 기능을 활성/비활성화
ex. -fmad={true | false}
Default: true - -dlcm: L1 cache 사용 여부를 지정
ex. -Xptxas=dlcm={cg | ca}
Default: ca(L1+L2 cache), cg(L2 cache) - -ptxas-options=-v (or -Xptxas = -v): 컴파일 시 간략한 정보를 보여줌
사용된 global memory, shared memory, register 개수 등의 정보를 알려줌 - -Xcompiler: 컴파일러/ preprocessor에 직접 옵션 지정
ex. -Xcompiler-fopenmp - -Xlinker: 호스트 링커에 직접 옵션 지정
$ nvcc -g -G -arch=sm_70 -maxrregcount=10 -fmad=true -Xptxas -v
-Xptxas -dlcm=ca -Xcompiler -fopenmp AddVecBlockSize.cu -o AddVecBlockSize3. Error Handling

- 'cudaSuccess': 연산의 성공을 나타냄
Device Query
1. cudaGetDeviceProperties
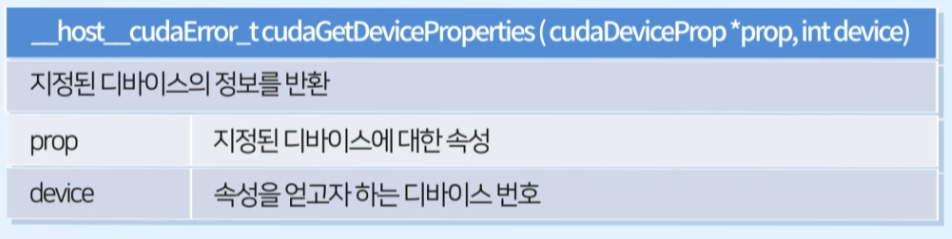
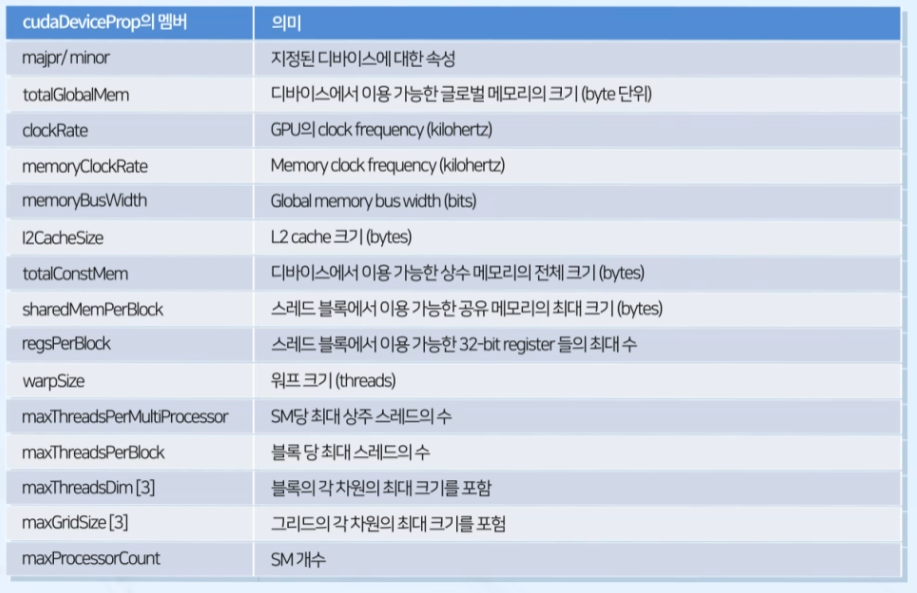
2. cudaDeviceProp: 디바이스에 대한 속성들 포함

올해는 진짜 갓생 산다