Chapter 11
공통 작업 흐름
- 많은 CUDA 라이브러리들은 호스트 application에서 호출될 때 개념, 특성, 공통 작업 흐름을 공유
① handle 생성
② 메모리 관련 설정
③ 변수 할당
④ 커널 통해 라이브러리 실행
⑤ 계산 완료
⑥ 관련 자원 반환
cuRAND
1. Host / Device side
Host-side CPU Library
- 다른 CPU 라이브러리와 동일하게 취급
- 헤더 파일 포함 (include/curand.h)
- 라이브러리 링크 (-lcurand)
Device(GPU) header file
#include <curand_kernel.h>- 정의된 함수를 사용하여 난수 생성 후 즉시 사용 가능
난수 생성: device
- 라이브러리는 호스트에서 호출
- 난수 생성이 디바이스에서 이루어지고 디바이스 메모리에 저장
난수 생성: host
- 모든 작업은 호스트에서 이루어짐
- 난수는 호스트 메모리에 저장됨
2. 연산 순서
① generator 생성
- 다른 라이브러리의 handle에 해당
curandCreateGenerator()사용
② generator 옵션 설정
- ex.
curandSetPseudoRandomGeneratorSeed()를 이용하여 seed 설정 - seed 값이 없다면 정해진 순서대로 Random Number 생성
③ 디바이스 메모리 할당
④ 난수 생성
curandGenerate()혹은 다른 생성 함수 이용
⑤ 결과 이용
⑥ Clean Up
curandDestroyGenerator()사용
호스트에서의 난수 생성
- ①에서 cudarandCreateGeneratorHost() 호출
- ③에서 결과를 받을 호스트 메모리 버퍼를 할당
- 모든 다른 작업은 동일
3. Host API
Return Values
- 모든 cuRAND host library는
curandStatus_t의 반환값을 가짐 - 에러 없이 성공적으로 호출되었다면
CURAND_STATUS_SUCCESS를 반환
Generation Functions

curandGenerateUniform(): 범위 내의 모든 난수들이 동일한 확률을 가짐

-
curandGenerateNormal(): 범위 내의 난수들이 정규 분포 형태의 확률을 가짐 -
Generation Function 뒤에 'Double'을 붙이면 Single-precision이 아닌 Double-precision의 정밀도로 난수 생성 가능
cuBLAS
개요
#include <cublas_v2.h>- NVIDIA CUDA runtime 위에서 실행되는 BLAS implementation
- Legacy API에 추가적인 새로운 API 제공
- 선형대수학에서 기본이 되는 루틴들 포함 (matrix, vector)
Error Status
- 모든 cuBLAS 함수 호출은 error status
cublasStatus_t를 return CUBLAS_STATUS_SUCCESS
cuBLAS context
cublasCreate()함수를 이용하여 cuBLAS library context에 대한 handle을 초기화cublasDestroy()를 이용하여 리소스 해제
cuSPARSE
1. Vector Format

두 개의 배열
- Data Array (D): nonzero 값들을 저장
- Integer index Array (I): nonzero의 위치를 저장
2. Matrix Format
여러 표현 방식
- COO, CSR, CSC, BSR(Block compressed Sparse Row), Extended BSR(BSRX)
- 일반적으로 CSR과 COO를 많이 사용
cusparseXcoo2csr,cusparseXcsr2coo로 상호 변환
COO
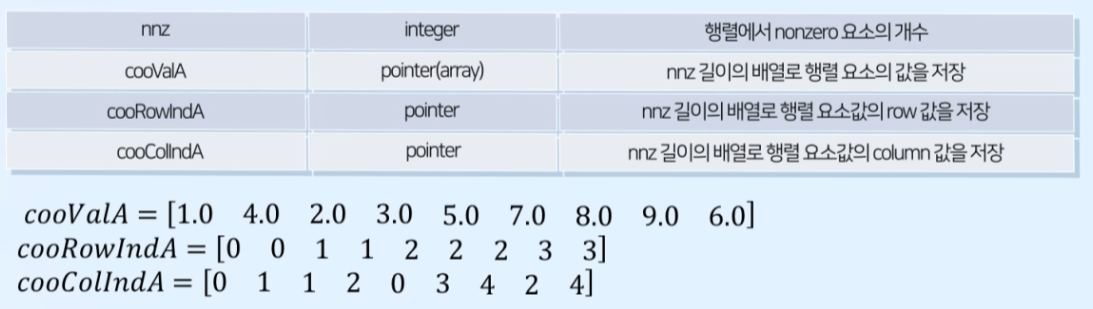
- nonzero 요소 값을 저장하는 배열
- nonzero 요소의 row/column을 저장하는 배열
CSR
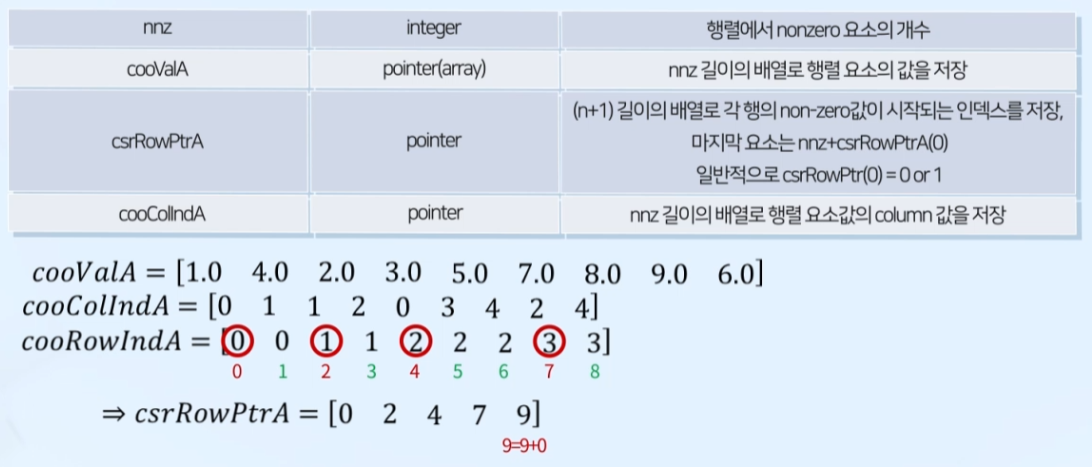
- nonzero 요소 값을 저장하는 배열
- nonzero 요소의 column을 저장하는 배열
- 각 행의 nonzero 값이 시작되는 인덱스를 저장하는 배열
3. 실행
cusparseHandle_t
-
cuSPARSE context에 대한 포인터 타임
-
cusparseCreate()/cusparseDestroy()- 다른 함수 사용 전
cusparseCreate()로 미리 초기화 cusparseCreate()에서 return된 handle은 다른 함수에서 사용됨cusparseDestroy()로 handle 해제 필수
- 다른 함수 사용 전
cusparseMatDescr_t
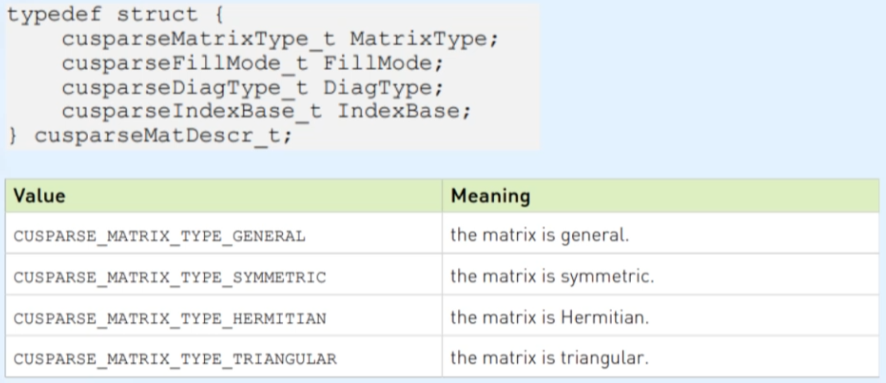
- Matrix shape과 속성을 기술하기 위해 사용되는 구조체
ex. symmetric matrix의 경우, 계산량을 절반으로 줄일 수 있음 cusparseCreateMatDescr(),cudasparseDestroyMatDescr()을 사용하여 matrix descriptor를 초기화 및 해제cusparseSetMatType(),cusparseSetMatIndexBase()를 사용하여 descriptor의 값을 변경
cuSOLVER
1. Intro
고수준 패키지
- cuBLAS, cuSPARSE 기반
- BLAS, SPARSE의 루틴을 조합하여 실제 문제 해결
- LAPACK: cuBLAS 루틴을 조합하여 만든 루틴
cuSolver API
- 단일 GPU
- cuSolverDN(dense LAPACK), cuSolverSP(sparse LAPACK), cuSolverRF(sparse re-factorization package)
cuSolverMG API
- 단일 노드 multi GPU
- GPU-accelerated ScaLAPACK(MPI 기능 제공)
2. cuSolverSP
Naming Conventions
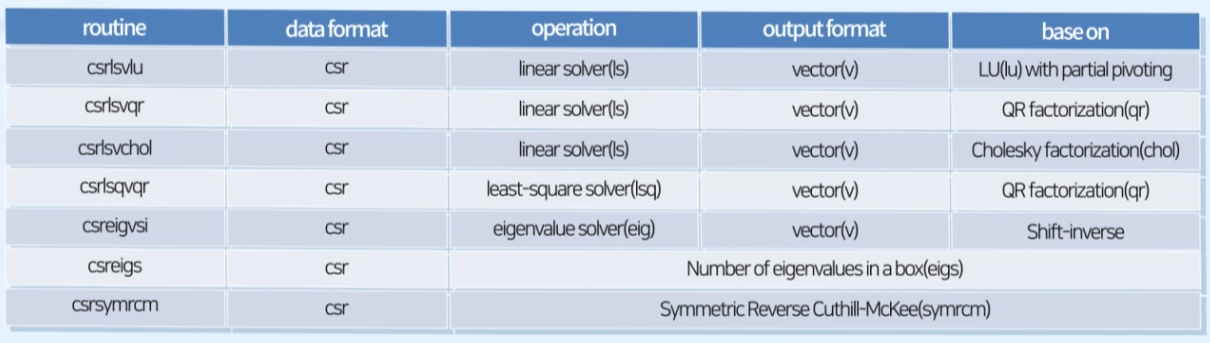
- routine, data format, operation, output format, base on 지정
- 문제에 맞추어 해당 값들을 알맞게 naming해주어야 함
비동기 실행
- Default가 비동기 실행이며, 비동기 실행 유지가 권장됨
- 결과값 추출 시
cudaDeviceSynchronize()로 강제 동기화
Chapter 12
Thrust
1. Intro
CUDA version of STL
- STL: Standard Template Library (C++ 기반)
- Thrust = STL에 기반한 CUDA를 위한 C++ Template Library
기능
- CUDA C와 완전히 호환되는 high-level interface를 통해 최소한의 프로그래밍 노력으로 고성능 병렬 application 작성 가능
- scan, sort, reduce와 같은 풍부한 데이터 병렬 primitive 제공
2. Reduction
Reduction Algorithm
#include <thrust/reduce.h>
#include <thrust/device_vector.h>- 입력 시퀀스를 단일값으로 reduce하기 위해 이항연산 사용
ex. 숫자 배열의 합 = '+' 연산으로 배열을 reducing하여 얻음
thrust::reduce
int sum=thrust::reduce(D.begin(), D.end(), (int) 0, thrust::plus());
- 처음 두 인자는 값의 범위 지정, 세 번째 인자는 초기값, 네 번째 인자는 reduction 연산자
- 초기값과 연산자는 default값 제공
