Chapter 10
Multi-GPU
1. Why Multi-GPU
Problem Domain Size
- 데이터가 차지하는 메모리의 크기가 너무 큰 경우
- Memory 중 가장 큰 Global Memory 용량의 한계
ex. V100: 16GB, A200/H100: 32GB~40GB - 호스트에 넣어두었다 쪼개는 방법보다 multiple GPU에 나누어 저장해두는 방식이 더 효율적
Throughput and efficiency
- 계산량이 매우 많아 장시간 돌려야하는 코드의 경우
- multiple GPU에서의 동시 계산으로 성능 향상
2. 데이터 통신
GPU간 데이터 통신
- 단일 GPU에서는 호스트-디바이스 통신만 고려
- Multi-GPU에서는 GPU간의 통신을 적절히 설계하는 것도 중요 (호스트-디바이스가 유리할지, 디바이스-디바이스가 유리할지)
- GPU간의 데이터 전달 효율은 노드 내부 GPU 연결, 클러스터 연결에 의존
두가지 타입의 연결성
- 단일 노드에서 PCIe bus를 통해 연결된 Multi-GPU
ex. 계산용 서버 - cluster에서 network switch를 통해 연결된 Multi-GPU
ex. HPC(고성능 컴퓨팅), 슈퍼 컴퓨터 - 웬만하면 단일 노드 내에서 이루어지는 통신이 유리함
3. Functions
cudaGetDeviceCount() : 이용 가능한 디바이스의 수 확인

cudaSetDevice() : 작업 타겟 디바이스 명시

- 디바이스 ID = 0~(ngpus-1)
- 기본 디바이스 = 0 (명시되지 않은 경우)
cudaSetDevice()이후 커널 함수를 호출하면 해당 커널 함수는 지정된 device에서 실행됨
4. Example: Matrix Multiplication
Using 2 GPUs
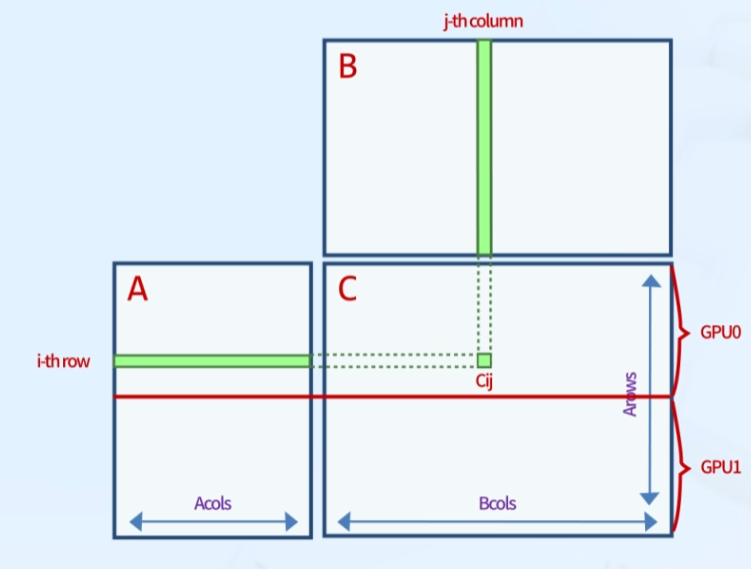
- 글로벌 메모리 사용
- GPU 0이 윗부분, GPU 1이 아랫부분 계산 담당
- Pinned Memory 사용 -> memcpy 과정 생략
단, matrix가 너무 크면 성능 저하 문제 발생 가능
과정
① cudaMallocHost()로 A,B,C를 pinned memory에 저장
② GPU 0, GPU 1에서 pinned memory에 접근
③ 커널 함수를 GPU 0, GPU 1에서 실행
④ 각 디바이스에서 계산된 C의 파편을 모음
⑤ 전체 행렬 C의 적절한 위치에 저장
4-1. 성능 향상
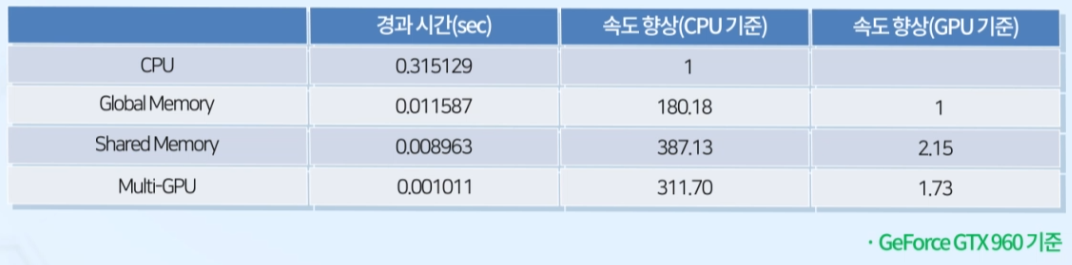
- CPU에서 MatMul을 실행했을 때 보다 GPU에서 실행했을 때 훨씬 더 향상된 성능을 보임
- Global Memory 보다 Shared Memory를 활용했을 때 더 좋은 성능을 보임
CUDA and MPI
1. MPI
GPU-to-GPU Data Transfer
- Performing GPU-to-GPU Communication with MPI
- MPI process가 cudasetDevice로 GPU에 고정되면, 디바이스 메모리와 host pinned memory는 현제 디바이스에 대해 할당
Hybrid Code
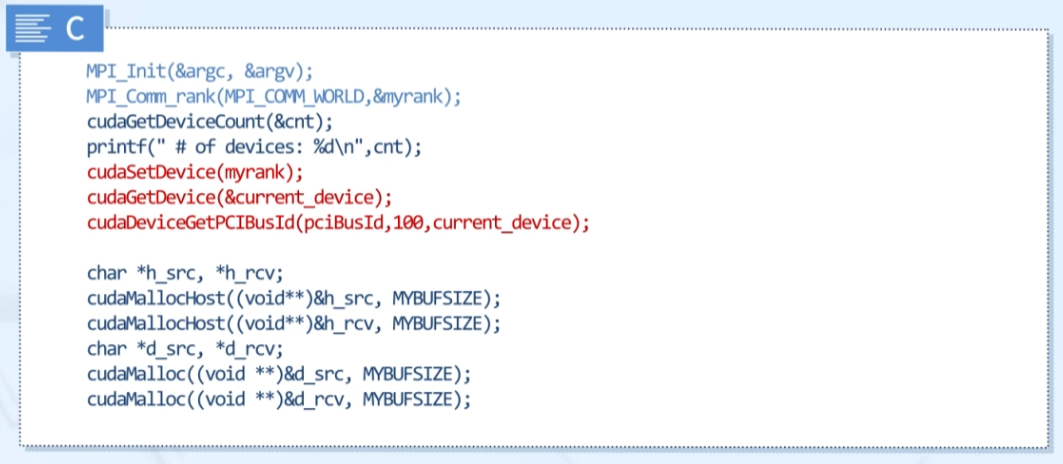
- MPI와 CUDA 문법의 혼용
- MPI는 노드간의 통신 담당 / CUDA는 한 노드 내에서의 작업 담당
2. Traditional MPI vs CUDA-Aware MPI
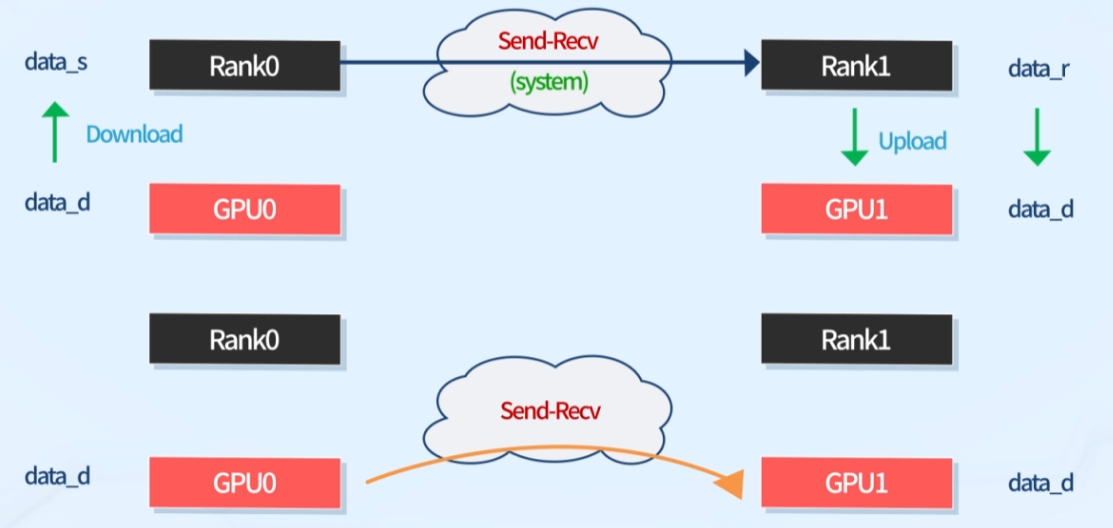
Traditional MPI (위)
- GPU간 데이터 통신을 위해 Host를 거침
- GPU가 Host에 데이터 download -> 호스트는 다른 호스트에 데이터를 send -> 데이터를 recv한 호스트가 자기 노드의 GPU에 데이터 upload
CUDA-Aware MPI (아래)
- Traditional MPI의 중간과정(Host 거침)을 생략하는 방법
- GPU가 네트워크 디바이스와 직접 통신
MPI_Isend(),MPI_Irecv()- 디바이스 메모리 포인터를 직접 MPI 함수에 전달
- Traditional MPI의 여분
cudaMemcpy()호출을 피할 수 있음
환경 설정
- CUDA-Aware MPI는 해당 방식을 지원하는 HW, 드라이버, 라이브러리 등 환경 설정이 되어 있을 때 사용 가능
- 같은 코드라도 환경에 따라 Traditional MPI로 작동할 수도, CUDA-Aware MPI로 작동할 수도 있음
Compile

- CUDA 코드는 nvcc로, MPI 코드는 mpicc로 컴파일
- 각각 컴파일 후 둘을 합쳐야 사용 가능

올해는 진짜 갓생 산다