Chapter 6
Warp
1. Warp: 실행 단위
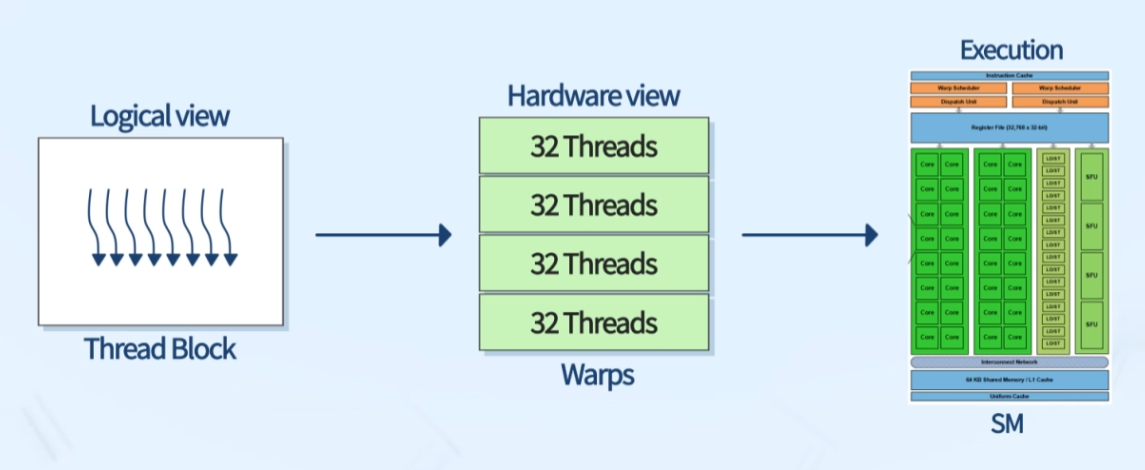
SM에 블록 단위 스레드 할당
- HW 리소스 한계 (CC)
GPU는 병렬 계산 위해 controller 부분이 최소화 된 구조 - 모든 스레드 동시 실행 불가능
- 일정 단위의 묶음을 만들고 각 묶음이 동일 작업을 수행하도록 그룹핑 하는 것이 효율적
Warp 스케줄링
- 1 Warp = 32 Threads
- 16개의 스레드에만 작업 할당 시, 나머지는 비활성화
- 블록은 워프 단위(32 threads)로 스레드를 재구분
Warp 기준 SIMT 실행
kernelA<<<1,120>>> // 1 block 120 threads
- warp 4개 (Warp 0 ~ Warp 3) 생성
- 블록의 총 스레드 수 = 32*4 = 128
- Warp 3의 8개의 스레드는 inactive (효율 저하)
비활성화되는 부분이 많아질수록 코드 성능 저하
2. Warp Divergence
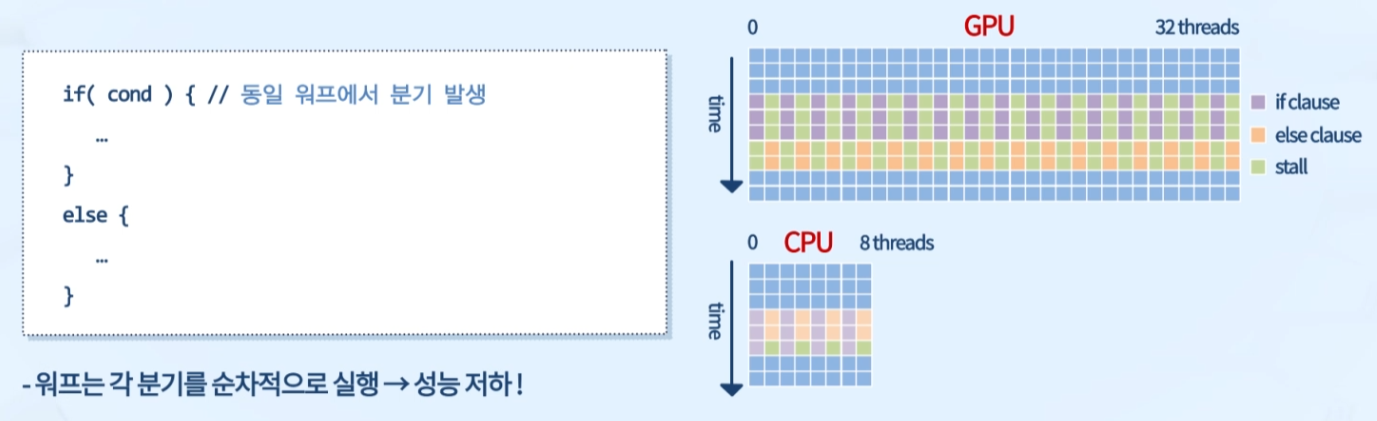
같은 워프, 다른 명령
- 워프는 각 분기를 순차적으로 실행 -> 성능 저하
- 분기문에서의 실행 단위를 warp 단위로 하여 보완
- 더 많은 조건 분기 존재 시, 병렬 손실 증대
워프 분기 회피
스레드 접근워프 접근 사용- 워프 id가 짝수일 때 if절, 홀수일 때 else절 실행
3. Example
스레드 접근 vs 워프 접근
워프 크기=16, 스레드의 실제 계산 절은 다름

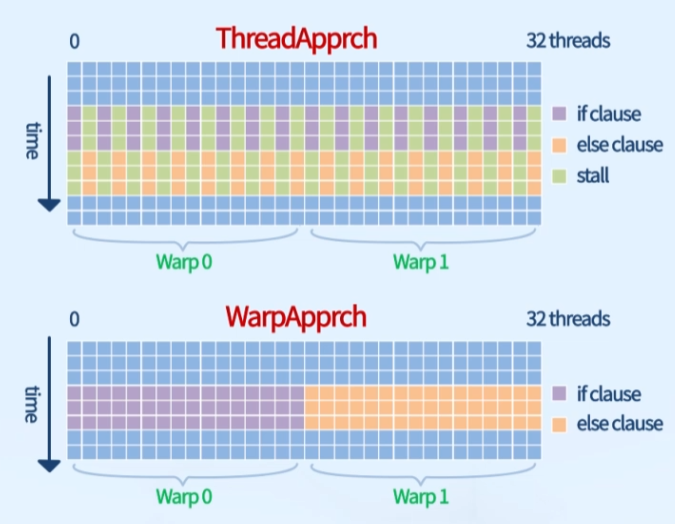
ThreadApprch(): 스레드 접근
절반의 스레드 항상 비활성화 (번갈아서 작업 수행)
if (tid%2==0) // 스레드의 global id 홀짝 기준WarpApprch(): 워프 접근
짝을 잘 맞추면 모든 스레드 활성화 가능
if((tid/warpSize)%2==0) // warp의 홀짝 기준성능 확인
$ nvcc WarpDivergence.cu -G -d WarpDivergence
$ nvprof --metrics branch_efficiency ./WarpDivergence- Branch Efficiency 100% = 비활성화 된 스레드가 없음
Occupancy
1. Occupancy

SM당 최대 허용 워프 수에 대한 활성 워프 수의 비
- Max Warps per SM = 64 (CC 7.0, V100)
- Max Threads per SM = 64*32 = 2048
2. CUDA Occupancy Calculator
공개 코드
- github: CUDA Calculator
https://xmartlabs.github.io/cuda-calculator/ - NVIDIA Nsight: 세세한 Occupancy 정보 제공
https://developer.nvidia.com/nsight-compute
입력
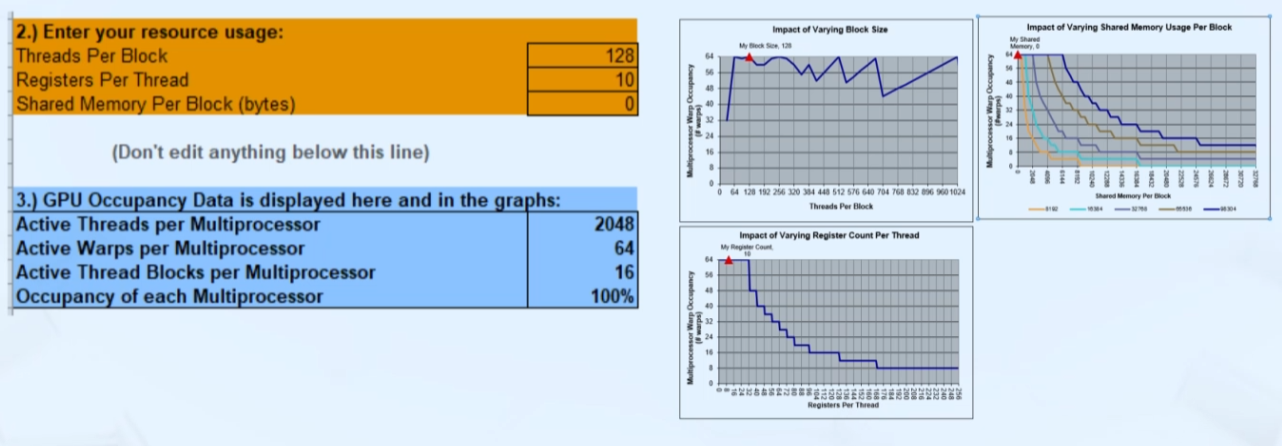
- Threads/block
- Registers/thread
compile option--ptxas-options=-v로 확인 - Shared Memory/block
compile option--ptxas-options=-v로 확인
3. Occupancy 증대
Calculator 권장 # of registers 사용
-maxrregcount=NUM(compile option)
그리드/블록 크기 조정
- 블록 당 스레드 개수는 32(워프 크기)의 배수
- 적당한 크기의 블록: 블록 당 128 ~ 256 스레드
- 커널에 필요한 자원에 따라 블록 크기 조절
- SM 보다 많은 수의 블록 사용
V100 기준 SM 개수 = 64
64 보다 블록 개수가 커야 효율적으로 병렬 처리 가능 - TEST (recommended)
4. Synchronization
Barrier 동기화
- 병렬 프로그래밍 언어에서 일상적으로 사용
- 잦은 동기화는 성능 저하로 이어짐
CUDA: 두가지 수준의 동기화
- System-level
호스트, 디바이스의 모든 작업이 완료될 때 까지 대기
__host__ __device__ cudaError_tcudaDeviceSynchronize(void);- Block-level
블록 내의 모든 스레드들이 디바이스에서 임의 실행 지점에 도달할 때 까지 대기
__device__ void__syncthreads(void);서로 다른 블록들 사이의 동기화는 존재하지 않음
5. Scalability
Scalable CUDA programs
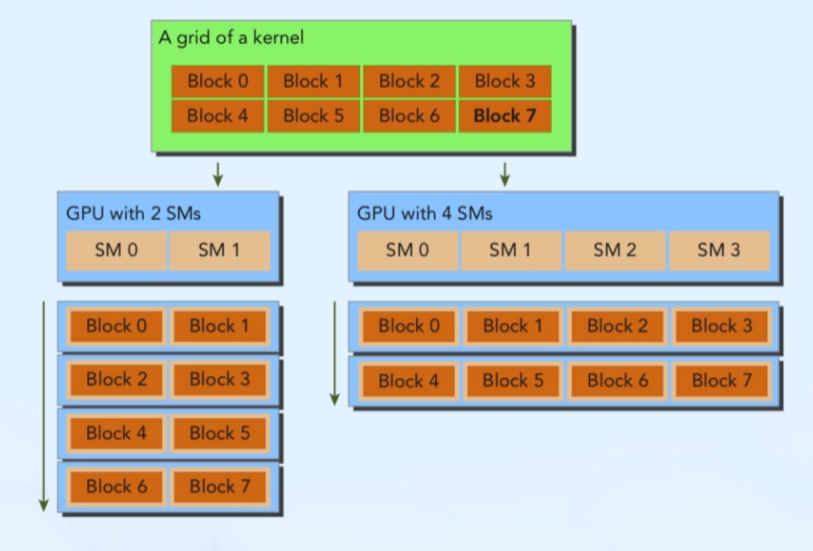
- 수동 매칭 X
- grid, block 크기 지정 시 가용 SM 개수에 따라 스케줄링

올해는 진짜 갓생 산다