Chapter 4
진짜 기가 막힌 거 발견
ㄹ ㅣ ㅌ ㅓ ㄴ << 이거 한글로 쓰면 velog에서 자체 비공개 처리를 함
왜지....? ㄷ ㅗ ㅂ ㅏ ㄱ 관련이라 그런가 암튼 return으로 바꾸니 해결됨
앞으로 글 쓸때 조심할 것
Dynamic Parallelism
병렬화 된 스레드 안에서 병렬화 함수를 재호출
Nested Parallelism
커널에서 커널 함수 호출 (동일 디바이스)
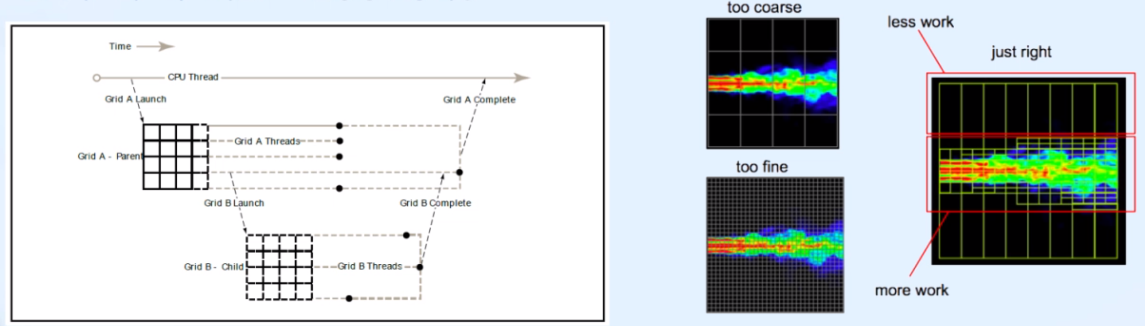
cc 3.5 이상, 최대 Nesting Depth는 24
블록과 그리드의 크기를 코드 실행 중 결정 가능
유동적 해석에서의 동적 병렬화
- too coarse -> 정보 탐지 어려움
- too fine -> 계산량이 너무 많아짐
- 필요한 부분에서만 fine하게, 빈 공간에서는 coarse하게 병렬화 -> just right
옵션
$ nvcc -arch=sm_70 -rdc = true src.cu -o src-lcudadevrt- 컴파일 옵션:
-rdc = true - 링크 옵션:
-lcudadevrt
장단점
- 장점: 정말 필요한 개수의 스레드만 사용
- 단점: 실행 전에는 사용할 스레드 개수 판단 불가
Example

- recursive function 형태로 구현
- 재귀 호출이 한 번 일어날 때 마다
int nthreads = iSize/2,iDepth += 1
Managing Data
1. Managing Memory
Standard C vs CUDA C
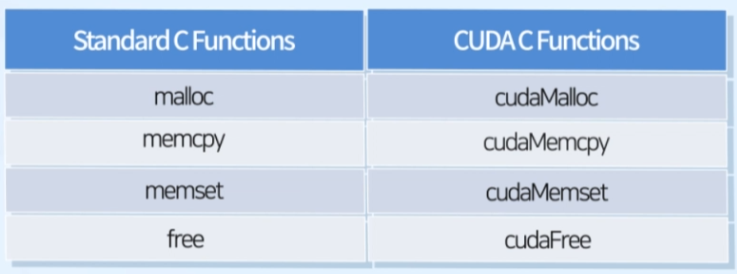
- kernel은 device memory의 데이터를 이용해 연산
- 일반 C 함수는 CPU의 Host 메모리(시스템 메모리)에 자원 할당, CUDA C 함수는 GPU 메모리에 할당
- CPU, GPU 메모리 상호 접근 불가 -> cpy 사용
GPU memory Allocation / Release
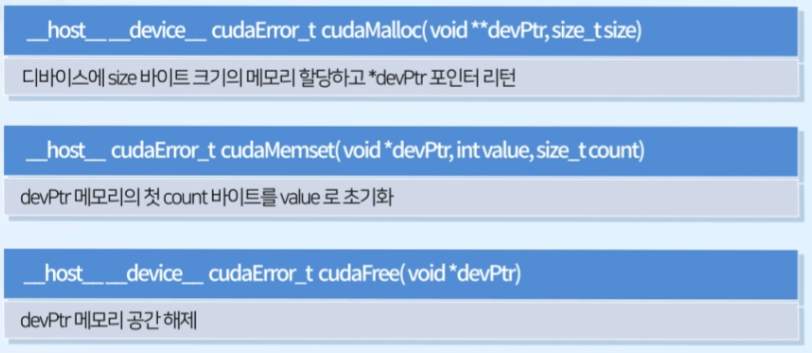
- cudaMalloc() : 디바이스에
size바이트 크기의 메모리 할당하고*devPtr포인터 리턴 - cudaMemset() : devPtr 메모리의 첫
count바이트를value로 초기화 - cudaFree() : devPtr 메모리 공간 해제
2. Data Copy
cudaMemcpy()

- 앞서 호출된 CUDA 함수 완료 후 데이터 복사 시작
- CPU thread blocking: 복사 완료 후 return
묵시적 동기화 - 비동기 데이터 복사는
cudaMemcpyAsync()활용
cudaMemcpyKind
cudaMemcpyHostToHost: Host -> HostcudaMemcpyHostToDevice: Host -> DevicecudaMemcpyDeviceToHost: Device -> HostcudaMemcpyDeviceToDevice: Device -> Device
Multi GPU 환경에서의 GPU간 data copy 가능cudaMemcpyDefault: dst, src 변수 기초로 시스템이 자동으로 결정 (recommended)
시스템이 dst, src가 Host인지 Device인지 판별
Chapter 5는 Example 2개 (Summing Vector / Matrices) 다룸
- GPU에 넘기는 게 오히려 비효율적일 수 있음
ex.cudaMemcpy()시간 > 연산 시간- grid, block size 설정에 따라 성능이 상이함
- 효율적인 프로그램을 위한 가이드라인
block size = Warp(32)* n (스레드 낭비 X)
block size >= 64 (128 ~ 256 recommended)
-> 다음 포스트는 Chapter 6 부터 시작

올해는 진짜 갓생 산다