회귀 모델
- X : 문제데이터, train / y : 정답데이터, test
- Linear Regression, Ridge, Lasso, 회귀평가지표, Scaling
선형 회귀모델
-입력 특성(입력데이터 = X , y)에 대해서 선형 함수를 만든다.
-만든 선형함수를 이해한다.
-특성(X) 마다 다른 가중치(w)를 사용한다
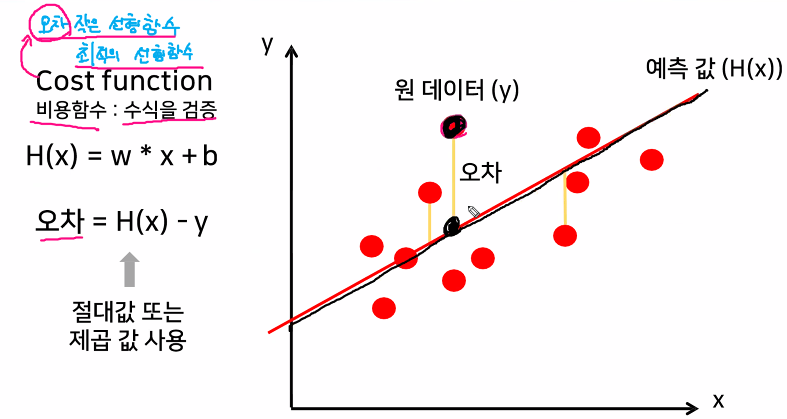
-완벽한 선형함수 만들수없으니 최대한 그럴듯한(오차가 적은) 선형함수를 그린다.
-오차의 부호가 다르니 오차끼리 상쇄 => 방지하기위해 평균제곱오차(MSE)
-최대한 효율적인 선형함수 그리기 => 경사하강법

경사하강법 (Gradient Descent)
-여러번 과정을 통해서 최적의 선형함수를 찾는다
-확실하게 선형함수를 찾을수있지만, 계산이 오래걸린다.
-SGD Regressor

성적 데이터 생성
import pandas as pd
data = pd.DataFrame([[2,20],[4,40],[8,80],[9,90]],
columns = ['시간','성적'])
data
수학공식을 이용한 해석적 모델
LinearRegression
from sklearn.linear_model import LinearRegression
# 모델 로드
linear_model = LinearRegression()
X = data[['시간']] # 문제는 2차원, series면 안된다.
y = data['성적'] # 정답은 1차원
# 모델 학습
linear_model.fit(X,y)
LinearRegression()
# 결과 확인
# 가중치 = 기울기
print("가중치 : ",linear_model.coef_)
# 편향 = 절편
print("편향 : ",linear_model.intercept_) # 부동소수점
#경사하강법
SGDRegressor
from sklearn.linear_model import SGDRegressor
# 모델로드
sgd_model = SGDRegressor(max_iter = 1000,# 몇번까지 반복해서 찾아갈것인가
eta0=0.001,# 학습률(learning rate) = 오차반영률
verbose=1) # 학습 과정 확인
# 학습
sgd_model.fit(X,y)
# 결과 확인
# 가중치 = 기울기
print("가중치 : ",sgd_model.coef_)
# 편향 = 절편
print("편향 : ",sgd_model.intercept_)
# 데이터가 너무 단순해서 찾아갈길이없어 편향이 크게나온다.
# y = wx + b = 9.86x + 1.02
#1. 문제정의
#보스턴 집값을 예측해보자
#회귀문제
#2. 데이터수집
from sklearn.datasets import load_boston
data = load_boston()
data.keys()
## 3. 데이터 전처리
import pandas as pd
X = pd.DataFrame(data['data'],columns = data['feature_names'])
y = pd.DataFrame(data['target'], columns=['price'])
total = pd.concat([X,y],axis=1)
total.head()
## 4. 탐색적 데이터 분석(EDA)
# 상관관계 분석
# -1 ~ 1 까지의 숫자로 상관관계 표현, 1 정비례관계, -1 반비례관계
total.corr()
## 5. 모델 선택 및 하이퍼 파라미터 튜닝
# 데이터 나누기
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=3)
from sklearn.linear_model import LinearRegression, SGDRegressor
linear = LinearRegression()
sgd = SGDRegressor(max_iter = 500, eta0=0.01)
linear.fit(X_train,y_train)
sgd.fit(X_train,y_train)
X_train.info()
y_train.info()
print(X_train.shape)
print(y_train.shape)
## 평가
linear.score(X_test,y_test)
sgd.score(X_test,y_test)
## 특성 확장을 통해서 과소적합 해소
col = X.columns
for i in range(col.size):
for j in range(i, col.size):
X[col[i]+'x'+col[j]] = X[col[i]]*X[col[j]]
X.shape
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=3)
linear2 = LinearRegression()
linear2.fit(X_train,y_train)
print(linear2.score(X_train,y_train))
print(linear2.score(X_test,y_test))


꾸준히