분류평가지표
-이진분류 (기준은 1, 0)
정확도 => 정밀도, 재현율 순으로 판단한다.
높은 정밀도 선호 => 애매한 것 사용하지않는다.
높은 재현율 선호 => 애매한 것 사용한다.#평가지표확인 from sklearn.metrics import classification_report, confusion_matrix y_pred= svm.predict(X_test) y_pred # TN / TP / FN / FP # confusion_matrix(오차 행렬) print(confusion_matrix(y_test,y_pred)) assification_report(y_test,y_pred)) print(classification_report(y_test,y_pred))
텍스트마이닝
텍스트분류, 주제찾기 (파이썬 머신러닝 책 534page)

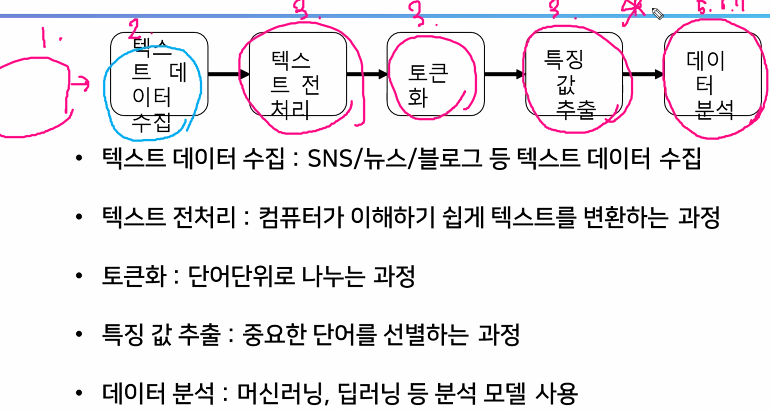
#1.문제정의
#영화리뷰 데이터셋을 사용해서 긍정과 부정을 판단하는 모델을 만들어보자
#2.데이터 수집
Large movie dataset
from sklearn.datasets import load_files # 여러개의 파일을 읽어오는 함수
train_data_url = 'data/aclImdb/train'
test_data_url = 'data/aclImdb/test'
reviews_train = load_files(train_data_url, shuffle = True)
reviews_test = load_files(test_data_url, shuffle = True)
reviews_train
reviews_train.keys()
# 바이트 자료형(1바이트 단위의 값으로 데이터를 관리) , b 가 맨앞에 붙는다.
reviews_train['data'][0]
reviews_train['target']
reviews_train['target_names']
3.데이터 전처리
.replace(b"<br />",b"")
# br 태그 제거
# br > 공백으로 변환
reviews_train['data'][1].replace(b"<br />",b"")
text_train
# text_train = []
# for txt in reviews_train['data']:
# text_train.append(txt.replace(b"<br />",b""))
# 를 간소화하기위해
# 리스트 내포(안에 포함한다)
text_train = [ txt.replace(b"<br />", b" ") for txt in reviews_train['data'] ]
text_test = [ txt.replace(b"<br />", b" ") for txt in reviews_test['data'] ]
train_copy = text_train
test_copy = text_test
y_train_copy= reviews_train['target']
y_test_copy= reviews_test['target']
text_train = text_train[:1000]
text_test = text_test[:1000]
y_train = reviews_train['target'][:1000]
y_test = reviews_test['target'][:1000]
# 토큰화 , 특징값 추출
# n-gram 단위 n개의 연속된 단어를 하나로 취급
# 수치 변환 => 원핫인코딩, BOW(Bag Of Word),
# ✔원핫인코딩 지양한다.
# BOW
from sklearn.feature_extraction.text import CountVectorizer
test_bow = CountVectorizer()
text=['이제 목소리 괜찮네','솔직히 오전에는 별로였음','지금 목소리가 더 좋은 목소리네요']
# 단어 사전 구축 =>
test_bow.fit(text)
# 단어 사전
test_bow.vocabulary_
# 토큰화 및 수치화 (특징값 추출)
test_bow.transform(text).toarray()
# 3x10 sparse matrix : 3개의 문장에서 10개의 단어 표현
# .toarray() 붙여추면 들어가있는 단어 확인가능
# 실제 데이터 적용
movie_bow = CountVectorizer(ngram_range=(1,2), # (단어개수부터,단어개수까지)
max_df=1000, # ?번 이상 나오는건 단어사전에 안올림
min_df = 10 # ?번 이하로 나오는건 단어사전에 안올림
)
movie_bow.fit(text_train) # 단어 사전 구축
X_train = movie_bow.transform(text_train)
X_test = movie_bow.transform(text_test)
#5.모델 선택 및 하이퍼 파라미터 튜닝
from sklearn.svm import LinearSVC
svm = LinearSVC()
#6.학습
svm.fit(X_train,y_train)
7.평가
svm.score(X_train_copy,y_train_copy)
#예측
# 데이터 => 전처리(br 태그 제거) => 토큰화 및 특징 값 추출(Bow) => 머신러닝 학습
reviews = ['This movie so good']
reviews = [ txt.replace("<br />", " ") for txt in reviews ]
reviews = movie_bow.transform(reviews)
svm.predict(reviews)
# 감성 분석하는데 많은 영향을 끼친 단어
# 데이터 > (BOW > SVM ) 하나로 묶기 : pipeline
# 토큰화 하는 새로운 방법 : tfidf
# 한글 리뷰 : konlpy
꾸준히