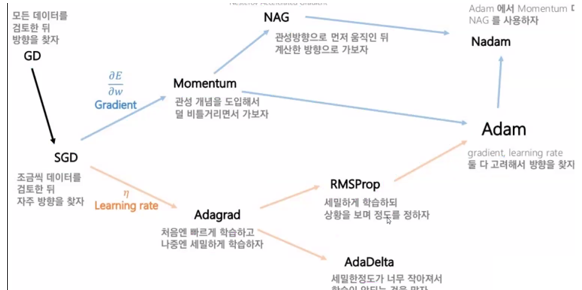
1.경사하강법 종류
-경사하강법(GD) : 전체 데이터를 사용해서 업데이트
-확률적 경사 하강법(SGD):
일부데이터를 사용해서 업데이트, GD보다 빠름,
지그재그로 이동함(방향이 불안정) => 방향,
한번에 이동할 수 있는 거리가 고정 => 학습률
-방향 :
모멘텀 => 관성을 이용함, 전 움직임을 생각하고 이동
네스테로프 모멘텀 => 개선된 모멘텀방식, 불필요한 이동이 줄어듬
#모델설계
model = Sequential()# 딥러닝 틀 만들기
#입력층
model.add(Dense(units = #원하는 뉴런수,input_dim=#입력데이터 특성의 크기,activation='relu'))
#중간층(은닉층)
model.add(Dense(units=#원하는 뉴런수, activation='relu'))
#출력층
model.add(Dense(units=,activation=))
#units : 이진분류, 회귀 = 1, 다중분류 = 클래스의 수(정답의 개수)
#activation : 이진분류 = 'sigmoid', 다중분류 = 'softmax', 회귀 = 'linear' or 생략가능
#모델 실행 방법 설정
model.compile(loss=,optimizer='adam',metrics=
#loss 이진분류 ='binary_crossentropy', 다중분류 = 'categorical_crossentropy', 회귀 = 'mean_squared_error'
#metrics 분류=['accuracy'], 회귀=['mean_squared_error'] or 생략
model.fit(X_train,y_train,epochs = #원하는만큼,
batch_size = #한번에 학습할 데이터 갯수
validation_data = (X_test,y_test))2.딥러닝 모델 저장 / 불러오기
3.이미지 학습
4.학습중단 / 중단모델 저장
손글씨 분류
from tensorflow.keras.datasets import mnist
((X_train,y_train),(X_test,y_test)) = mnist.load_data()
# 데이터 확인
import matplotlib.pyplot as plt
plt.imshow(X_train[0], cmap='gray')
plt.show()
# 0~ 255 사이의 픽셀 값으로 이루어짐
X_train[0]
# 이미지 데이터를 MLP
# 퍼셉트론은 1차원의 데이터만 학습가능
# 2차원 => 1차원으로 변환
X_train = X_train.reshape((60000,28*28))
X_test = X_test.reshape((10000,28*28))
X_train.shape
# 이미지 픽셀값 수정
# 0 ~ 255 => 0 ~ 1
# 분산을 줄여서 계산상의 오차를 줄이자
# 작은 범위의 숫자로 기존의 의미를 표현 => 계산량 감소
X_train = X_train.astype('float')/255
X_test = X_test.astype('float')/255
# 모델 설계
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model1 = Sequential()
# 입력층
model1.add(Dense(32, input_dim=784, activation='sigmoid'))
# 중간층
model1.add(Dense(64,activation='sigmoid'))
model1.add(Dense(128,activation='sigmoid'))
model1.add(Dense(64,activation='sigmoid'))
# 출력층
model1.add(Dense(10,activation='softmax'))
# 0 ~ 9 까지의 손글씨가 존재
import numpy as np
np.unique(y_train)
# ✔다중분류시에만 진행
import pandas as pd
y_train = pd.get_dummies(y_train)
y_test = pd.get_dummies(y_test)
model1.compile(
loss='categorical_crossentropy',
optimizer='SGD',
metrics=['accuracy']
)
model1.fit(X_train,y_train,epochs=40, validation_data=(X_test,y_test))
model2 = Sequential()
# 입력층
model2.add(Dense(32, input_dim=784, activation='sigmoid'))
# 중간층
model2.add(Dense(64,activation='sigmoid'))
model2.add(Dense(128,activation='sigmoid'))
model2.add(Dense(64,activation='sigmoid'))
# 출력층
model2.add(Dense(10,activation='softmax'))
model2.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
model2.fit(X_train,y_train,epochs=20, validation_data=(X_test,y_test))
model3 = Sequential()
# 입력층
model3.add(Dense(32, input_dim=784, activation='relu'))
# 중간층
model3.add(Dense(64,activation='relu'))
model3.add(Dense(128,activation='relu'))
model3.add(Dense(64,activation='relu'))
# 출력층
model3.add(Dense(10,activation='softmax'))
model3.compile(
loss='categorical_crossentropy',
optimizer='SGD',
metrics=['accuracy']
)
model3.fit(X_train,y_train,epochs=20, validation_data=(X_test,y_test))
model4 = Sequential()
# 입력층
model4.add(Dense(32, input_dim=784, activation='relu'))
# 중간층
model4.add(Dense(64,activation='relu'))
model4.add(Dense(128,activation='relu'))
model4.add(Dense(64,activation='relu'))
# 출력층
model4.add(Dense(10,activation='softmax'))
model4.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
model4.fit(X_train,y_train,epochs=20, validation_data=(X_test,y_test))
# 직접 적은 손글씨 불러오기
import PIL.Image as pimg
img=pimg.open('/content/test.gif')
plt.imshow(img)
plt.show()
# 흰색(255)과 검은색(0) 바꾸기
num = np.array(img)
num = 255-num
# 차원 수정
num = num.reshape(1,784)
# 픽셀값 수정 : 0 ~ 255 => 0 ~ 1
num = num.astype('float')/255
model4.predict(num)
# Early Stopping : 오차가 줄지 않거나 정확도가 높아지지않으면 학습을 중단
# Model Check Point : 학습중 오차나 정확도가 개선되면 모델을 저장
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# 모델 저장 폴더 및 저장 파일명 지정
# epoch:03d = 반복수(epoch)를 3자리 정수로 표현
# val_accuracy:.4f = 검증 정확도를 소수점 4번째 자리까지 표현
modelpath = '/content/handmodel-{epoch:03d}-{val_accuracy:.4f}.hdf5'
# 결과 handmodel-012-0.9764.hdf5로 저장
# 전보다 나아지면 저장
mcp = ModelCheckpoint(
filepath = modelpath,
monitor = 'val_accuracy', # 판단기준 => 검증 정확도를 기준으로 전보다 나아졌다면 저장
save_bear_only = True, # 나아진 결과만 저장
verbose = 1 # 학습과정에서 모델체크포인트를 보여준다
)
# 전보다 나아지지 않으면 학습 중단
es = EarlyStopping(
monitor = 'val_accuracy',
patience = 5 # 전보다 나아지지않아도 실행할 횟수
)
model5 = Sequential()
# 입력층
model5.add(Dense(32, input_dim=784, activation='relu'))
# 중간층
model5.add(Dense(64,activation='relu'))
model5.add(Dense(128,activation='relu'))
model5.add(Dense(64,activation='relu'))
# 출력층
model5.add(Dense(10,activation='softmax'))
model5.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
model5.fit(X_train,y_train,epochs=50, validation_data=(X_test,y_test),
callbacks = [mcp,es])
개 고양이 분류
# 데이터 경로 지정
train_dir = '/content/drive/MyDrive/dogs_vs_cats_small/train'
val_dir = '/content/drive/MyDrive/dogs_vs_cats_small/validation'
test_dir = '/content/drive/MyDrive/dogs_vs_cats_small/test'
# ImageDataGenerator
# 픽셀값 0 ~ 255 => 0 ~ 1 기능만들기
# ImageDataGenerator.flow_from_directory
# => 하나의 변수에 이미지 파일 전부 다 합치기
# 이미지 크기 동일하게 모두 맞춰주기 (150, 150)
# 라벨링
from tensorflow.keras.preprocessing.image import ImageDataGenerator
generator = ImageDataGenerator(rescale = 1./255) # . => 'float'형변환
train_generator = generator.flow_from_directory(
directory = train_dir, # train 이미지 경로
target_size = (150,150), # 변환할 이미지 크기
batch_size = 100, # 한번에 변환할 이미지 갯수
class_mode = 'binary' # 라벨링 (binary 이진분류, categorical 다중분류) =>
)
val_generator = generator.flow_from_directory(
directory = val_dir, # train 이미지 경로
target_size = (150,150), # 변환할 이미지 크기
batch_size = 100, # 한번에 변환할 이미지 갯수
class_mode = 'binary' # 라벨링 (binary 이진분류, categorical 다중분류) =>
)
test_generator = generator.flow_from_directory(
directory = test_dir, # train 이미지 경로
target_size = (150,150), # 변환할 이미지 크기
batch_size = 100, # 한번에 변환할 이미지 갯수
class_mode = 'binary' # 라벨링 (binary 이진분류, categorical 다중분류) =>
)
# 라벨링 결과 확인
print(train_generator.class_indices)
# CNN 모델 설계
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPool2D, Flatten
# Flatten 2차원을 1차원으로 만들어줌
model1 = Sequential()
# 입력층, 특징 추출부
model1.add(
Conv2D( # 특징이 될만한 것들 사이즈만큼을 기준으로 찾는다 무작위로
filters = 32, # 찾을 특징의 갯수 = 뉴런
kernel_size = (3,3), # 특징의 크기
input_shape = (150,150,3), # 입력 데이터의 모양(RGB)
padding = 'same',
activation = 'relu'
)
)
model1.add(
MaxPool2D( # 특징이 아닌부분 삭제
pool_size = (2,2) # 기준 크기(2,2)에서 1개의 특징만 가져오기
)
)
#중간층
model1.add(
Conv2D( # 특징이 될만한 것들 사이즈만큼을 기준으로 찾는다 무작위로
filters = 16, # 찾을 특징의 갯수 = 뉴런
kernel_size = (3,3), # 특징의 크기
padding = 'same',
activation = 'relu'
)
)
model1.add(
MaxPool2D( # 특징이 아닌부분 삭제
pool_size = (2,2) # 기준 크기(2,2)에서 1개의 특징만 가져오기
)
)
#✔✔✔✔✔ 특징 추출 끝
model1.add(Flatten()) # 1차원으로 만들어 주기
#✔✔✔✔✔ 분류 시작
model1.add(Dense(units= 64, activation='relu'))
model1.add(Dense(units= 16, activation='relu'))
# 출력층
model1.add(Dense(units = 1,activation='sigmoid'))
model1.summary()
# Param => 32 x 28 (=> 3 x 3 x 3 + 1)=> 32 x 28 + 1 x 32
model1.compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics =['accuracy']
)
model1.fit_generator(
generator = train_generator,
epochs=20,
validation_data = val_generator
)
MLP
1.CNN 모델
2.이미지 증식
3.전이학습
4.YOLO v5
5.OPENCV
6.RNN/LSTM

꾸준히