iris(붓꽃)
데이터 탐색적 분석 EDA
산점도 행렬 : 한꺼번에 변수의 관계를 파악가능
각 특성에 대한 정답들의 집합
# 산점도 행렬 : 다변량 데이터에서 변수의 쌍 간이 관계를 확인가능하다
# 4개 특성간의 3개 품종의 집합을 시각화한다.
# 같은 품종끼리는 뭉치고 다른 품종끼리는 떨어져있는다.
#도수분포표(x=x,y=y)의 빈도수를 나타내어 히스토그램으로 표현
pd.plotting.scatter_matrix(iris_df, c = y, figsize=(10,10))
#모델 생성
# 쉬프트+탭하면 default값을 볼수있다.
knn_model=kn(n_neighbors=50)
#모델학습
knn_model.fit(X_train,y_train)
#모델예측
pre =knn_model.predict(X_test)
# 예측한 데이터를 품종의 이름으로 바꿔보자
# 인덱싱 / 슬라이싱 개념을 생각해보자
iris_data['target_names'][pre]
일반화 성능 확인하기
knn모델에서는 n_neighbors(이웃수) 하이퍼파라미터 튜닝
#모델평가
acs(pre,y_test)*100
print(f"{acs(pre,y_test)*100:.2f}%")
#trrin, test 들의 여러개의 정확도를 저장해주는 빈리스트 생성
test_list=[]
train_list=[]
#1부터 100까지 값을 k 값으로 설정해서 반복해주자
for i in range(1,101):
#모델 생성
knn_model=kn(n_neighbors=i)
#모델학습
knn_model.fit(X_train,y_train)
#모델예측
pre =knn_model.predict(X_test)
#train 정확도 저장 => 모델 내에서 제공하는 정확도 측정방법
train_list.append(knn_model.score(X_train,y_train))
#test 정확도 저장
test_list.append(knn_model.score(X_test,y_test))
# 데이터 시각화
# train 정확도
plt.figure()
plt.plot(range(1,101),train_list, label = 'train_acc')
# test 정확도
plt.plot(range(1,101),test_list, label = 'test_acc')
plt.grid()
plt.xticks(range(1,101,2))
plt.legend()
plt.show()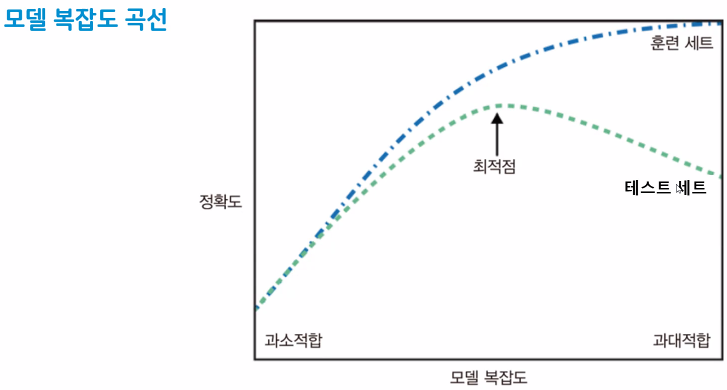
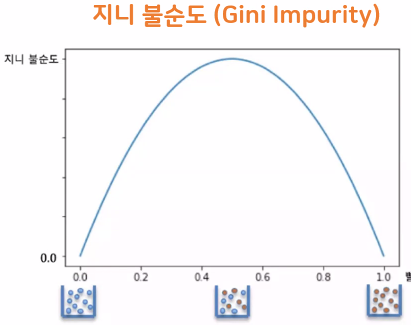
Decision Tree 알고리즘 (의사결정 나무 모델)
- 스무고개와 비슷하게 질문에 대한 예/아니오 반복으로 학습
- 분류 회귀 모두 사용가능
- 불순도가 낮아지는 방향

버섯예제
#도구 불러오기
import matplotlib.pyplot as plt
import pandas as pd
#머신러닝 패키지
from sklearn.neighbors import KNeighborsClassifier as kn #KNN 분류모델
from sklearn.metrics import accuracy_score as acs
from sklearn.tree import DecisionTreeClassifier as dtc
from sklearn.model_selection import train_test_split as tts
#목표
#버섯의 특징을 활용해서 식용/독 버섯 분류
#의사결정나무 그래프 시각화 & 과대적합 제어하기
#특성의 중요도 확인
#중요한 특성일수록 탑노드에 위치한다
#모델 내부에 들어있는 기능
#줄어져있는 전체 데이터 확인하는 방법
pd.set_option('display.max_columns',None)
#버섯데이터
#행 8124개 열 22개 라벨 2개
data=pd.read_csv("data/mushroom.csv",encoding="utf-8")
data.head()
# 현재 데이터의 값들이 문자열 형태이다 = 디시전트리는 범위로 질문
# 특정 문자열 이상이니? 라는 질문은 답할수 없음
# 알파벳을 수치화해서
#데이터 크기 확인
data.shape
#특징 (22)+레이블(1)
# 데이터의 정보확인
data.info()
# 결측치 없음 전처리 해주지 않아도 된다.
# 데이터 문자열 => 인코딩 (수치형으로 인코딩)
#데이터 크기 확인
data.shape
#특징 (22)+레이블(1)
# 데이터의 정보확인
data.info()
# 결측치 없음 전처리 해주지 않아도 된다.
# 데이터 문자열 => 인코딩 (수치형으로 인코딩)
#문제데이터와 답데이터 분리
#문제(X, 피처, 특징, 독립변수)
#답(y, 레이블, 라벨, 종속변수, 타겟)
# 데이터 분리
# 데이터.iloc[행,열]
#드랍
z = data.drop('poisonous',axis=1)
X= data.iloc[:,1:]
y = data['poisonous']
# X의 기술통계향 확인(우리의 데이터는 문자열)
# 원래는 숫자와 문자가 함께 존재하면 숫자 값에 대한 통계량만 출력
data.describe()
# 문자열만 있게되면 데이터의 특징을 추출해서 보여준다
# count : 단순하게 데이터의 개수
# unique : 고유값(특정알파벳의 개수)
# top : 제일 많이 등장한 값 , 가장 많이 나온 데이터값
# freq : top 항목의 개수
#Label 값의 횟수 확인
y.value_counts()
# e : 식용
# p : 독성
#데이터 전처리
#데이터 문자열 => 수치화 (인코딩)
#인코딩 방법 2가지
# 1.원핫인코딩 (onehot encoding)
# 2.레이블인코딩 (label encoding)
# 원핫 인코딩 : 값의 크고 작음이 의미가 없을때 사용한다
# 원핫 인코딩 도구 :pandas에서 제공 => pd.get_dummies(컬럼이름)
pd.get_dummies(X)
# 기술통계량에서 봤던 unique 개수(알파벳의 종류)만큼 열이 늘어난다.
# 그 알파벳에 해당하는 값이면 1, 나머지는 0 값을 배치
# 'cap-shape_x'>=1 이렇게 물어보면 분리가 가능해진다.


꾸준히