[Paper Review] Legged Locomotion in Challenging Terrains using Egocentric Vision
Paper Review
https://arxiv.org/pdf/2211.07638.pdf
Introduction
사람도 로봇도 평범한 상황에서는 시각이 없어도 잘 이동한다. 시각 정보를 활용하는 것은 험난한 지형을 이동할 떄이다. 본 논문에서는 egocentric vision(로봇에 부착)을 활용해 사족보행 로봇을 구현했다.
사람처럼 경험을 통해 미리 앞의 상황을 보고 걸음을 결정할 수 있는 메모리를 활용한다.
기존
- 2차원 고도 정보를 활용
- 여러 depth images 활용
Method
목표: 인식 및 깊이 입력을 바탕으로 다음 joint angles를 예측하여 걷는 방법을 learning
Phase 1
- 저해상도 scandots 사용(depth image 대용)
Phase 2
- RNN에 depth 와 proprioception을 input로 주어 지형을 추적하고
joint angles을 예측한다
metric elevation maps 없이 직접적으로 joint angles를 예측한다.
Phase 1: Reinforcement LEarning from Scandots
Proprioception은 joint angles, joint velocities, angular velocitym roll and pitch로 구성
Monolithic
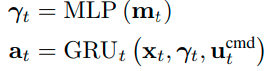
를 mlp로 압축
GRU로 joint angles를 예측
RMA
memory base를 대신해 MLP를 controller로 사용
각 phase1은 PPO(back prop)으로 학습된다.
Rewards
energy consumption과 damage to hw에 penalty를 주는 것으로 확장
Training environment
쉬운 task에서 어려운 task로 진행
Phase 2: Supervised Learning
phase1 policy를 distill을 통해 onboard sensor만을 활용해 유사한 policy를 구현한다
Monolithic
DAgger알고리즘으로 RL 진행
간의 MSE를 최소화하는 방향으로 학습
EMA
전체 controller를 재학습 시키는 대신에 train estimator인 와 를 학습
Experiment
Blind policy와 Noisy와 비교
Conclusion
기존의 방식은 elevation map을 만드려 함
depth 정보로 바로 행동 도출하는 방향으로 연구중
한계점: visual or terrain mismatch 발생시(simulation 과) 실패 가능
개선점: 현실에서 얻은 데이터를 바탕으로 학습시키고자 함

안녕하세요 글 잘 봤습니다. 질문 하나 드리고자 답글 남깁니다.
introduction에서 RNN을 사용하는 가운데, feedforward pass를 이용한다고 했는데 이게 feedforward pass는 입력 데이터를 처리할때 이고 그 처리된 데이터들로 rnn을 돌리는게 맞을까요? 즉, feedforward pass이 rnn을 구성하는 것이라고 보면 될까요?
result 부분에서 fig 4를 보면 #stairs, #stones 들이 ttf(time to failure)을 뜻하는 거 같은데, upstairs에서 ours가 100퍼센트, 13이면 13번 이후에는 부서졌다는건가요? Ttf를 어떻게 이해하면 될까요??
질문 들어주셔서 감사합니다. 혹여나, 바쁘시면 답 안주셔도 괜찮습니다. 초면에 질문드려 죄송했습니다.