Paper Review
1.[Paper Review] Transformer: Attention is all you need

About Transformer
2.[Paper Review] LSTM-CNN Architecture for Human Activity Recognition
paper review
3.[Paper Review] SuperGlue: Learning Feature Matching with Graph Neural Networks
paper review
4.[Paper Review] [DINO] Emerging Properties in Self-Supervised Vision Transformers
paper reading
5.[Paper Review] Segmenting Transparent Object in the Wild with Transformer
paper review
6.[Paper Review] Legged Locomotion in Challenging Terrains using Egocentric Vision
https://arxiv.org/pdf/2211.07638.pdf Introduction 사람도 로봇도 평범한 상황에서는 시각이 없어도 잘 이동한다. 시각 정보를 활용하는 것은 험난한 지형을 이동할 떄이다. 본 논문에서는 egocentric vision(로봇에 부착)
7.[Paper Review] Dex-NeRF: Using a Neural Radiance Field to Grasp Transparent Objects
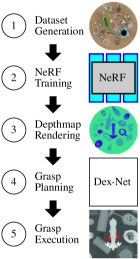
https://arxiv.org/pdf/2110.14217.pdf한계: transparent object를 잡는 것은 로봇에게 어려운 문제이다(using depth camera or something)저자들은 NeRF(neural radiance fields)
8.[Paper Review] PaLM-E: An Embodied Multimodal Language Model
https://arxiv.org/pdf/2303.03378v1.pdfembodied language models를 이용해 real world의 continuous sensor data를 word와 통합시킨다.multimodal sentences(visual,
9.[Paper Review] Vision Transformer - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
https://arxiv.org/pdf/2010.11929.pdf Abstract transformer는 NLP 분야에서 널리 사용 되고 있다. 이를 vision task에 가져와 시도한 것이 본 논문의 의의이다.(단, 많은 양의 학습 데이터를 필요로 한다) Int
10.[Paper Review] Plant growth information measurement based on object detection and image fusion using a smart farm robot
Abstract 그동안 작물의 관리 및 수확은 농부의 경험적인 감각에 의존해 왔다. 이를 정량화하기 위해 스마트팜 로봇이 연구되었지만 주변 배경과의 유사성으로 인해 큰 성과를 거두지 못했다. 본 논문은 object detection, image fusion, data
11.[Paper Review] You Only Learn One Representation: Unified Network for Multiple Tasks
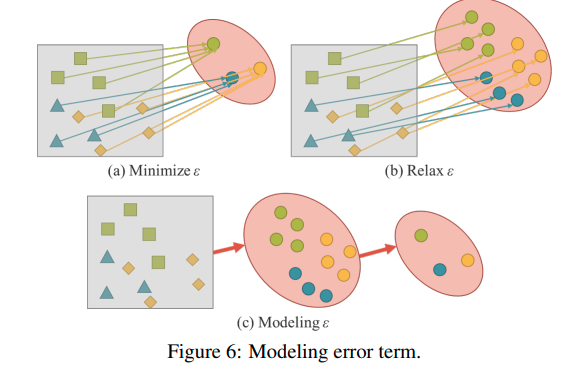
Abstract explicit knowledge와 implicit knowledge 2개를 통해 사람은 학습을 한다.(뇌에 encoded and stored 되는 것으로 생각 가능) 이를 딥러닝에 활용하여 본 논문에서는 normal learning 뿐만 아니라 sub
12.[Paper Review] CURL: Contrastive Unsupervised Representations for Reinforcement Learning
https://arxiv.org/pdf/2004.04136.pdf 강화학습에 대해 잘 모르는 관계로 충분히 공부한 후에 다시 보완하도록 하겠습니다. Abstract CURL은 state based에 근접한 최초의 image-based 알고리즘입니다. Introduc
13.[Paper Review] Zero-shot Learning Through Cross-Modal Transfer
Abstract 학습 데이터가 없는 상황에서 unseen object에 대한 class 분류 문제를 해결하는 과정입니다. unsupervised text corpora 를 통해 visul 과 text의 semantic space를 학습해서 unseen class를 예측
14.[Paper Review] Scan Context: Egocentric Spatial Descriptor for Place Recognition within 3D Point Cloud Map
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8593953&tag=1 Abstract feature detector와 descriptor가 많이 있지만 structural information을 이용한 것은 적
15.[Paper Review] Towards Segmenting Anything That Moves

CVPR 2019 https://arxiv.org/pdf/1902.03715.pdf Abstract Detection 과 segmentation은 action detectino이나 robotic interaction에서 많이 사용됩니다. 기존에는 spatio-tem
16.[Paper Review]Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation
Abstract precision based manipulation from visual using RL는 기존 방식의 어려움을 해결했습니다. 하지만 정밀한 motor control은 visual input만으로 해결하기 여렵습니다. 이를 위해 egocentric vi
17.[Paper Review] UNSUPERVISED SEMANTIC SEGMENTATION BY DISTILLING FEATURE CORRESPONDENCES

ICLR 2022 https://arxiv.org/pdf/2203.08414.pdf Abstract Unsupervised semantic segmentation은 대량의 이미지를 통해 annnotation 없이도 semantic segmentation을 가능하게 하
18.[Paper Review] Grounding Language with Visual Affordances over Unstructured Data
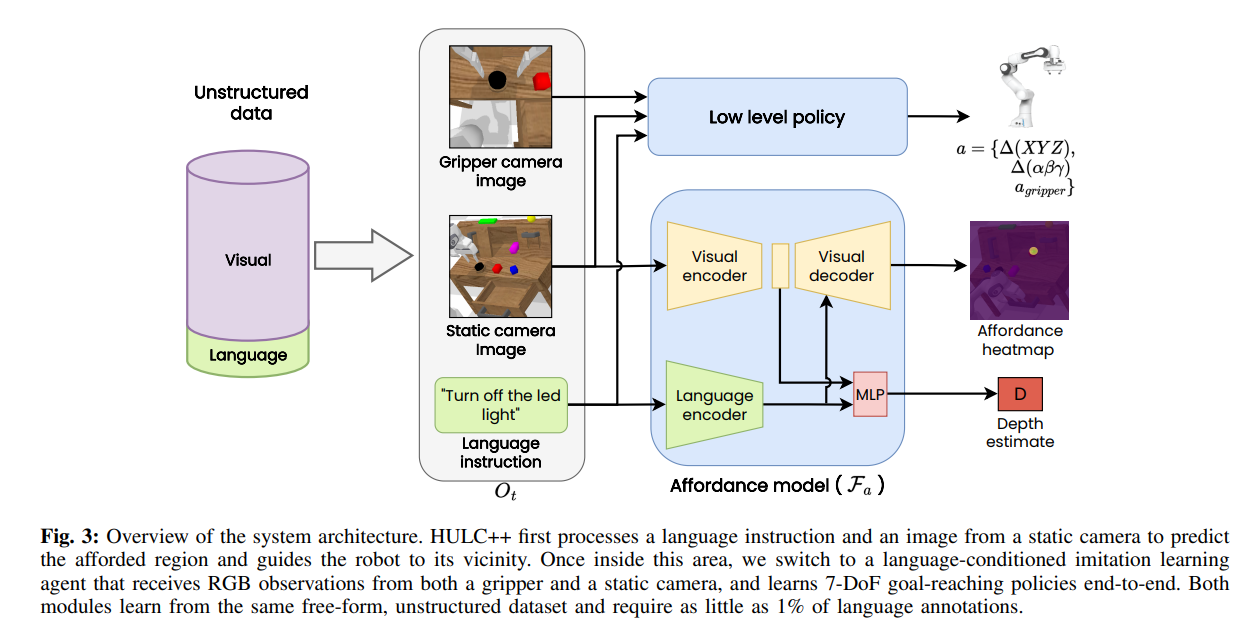
https://arxiv.org/pdf/2210.01911.pdf ICRA 2023 Abstract 최근 연구에서는 LLM을 robot task에 적용하는 것이 효과적임을 보여줘왔습니다. 본 연구에서는 self-supervised visuo-lingual afford
19.[Paper Review] ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
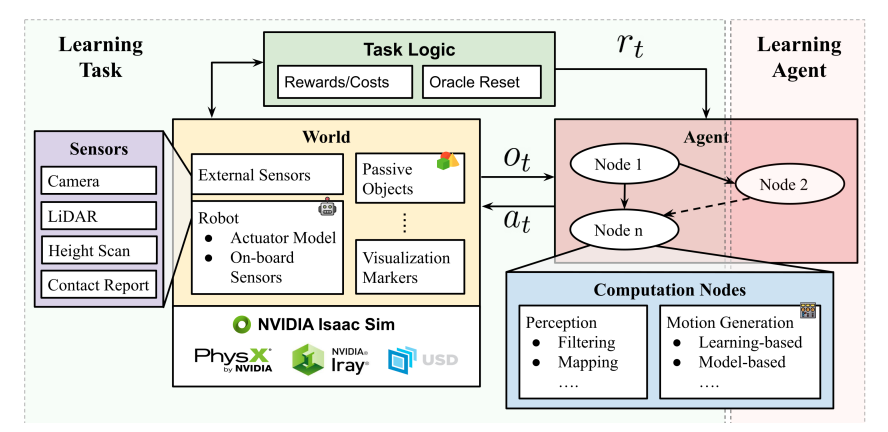
https://isaac-orbit.github.io/본 논문은 Nvidia의 Isaac Sim에서 동작하는 robot learning을 위한 프레임워크인 ORBIT을 제시하고 있습니다. photo realistic하고 빠르고 정확한 데이터를 얻어낼 수 있습니
20.[Paper Review] Siamese Masked Autoencoders
시간에 걸쳐 visual correspondence를 self supervied manner로 해결한 연구이다. 기존의 많은 연구들이 contrastive learning을 활용한 경우가 많은데 extensive augmentation이 필요한 단점이 있다. 본 논문은