CVPR 2019
https://arxiv.org/pdf/1902.03715.pdf
Abstract
Detection 과 segmentation은 action detectino이나 robotic interaction에서 많이 사용됩니다. 기존에는 spatio-temporal grouping을 사용한 것이 SOTA를 달성했고 learning based의 방식들은 사용되지 않았습니다. optical flow를 활용한 motion 단서와 appearnace 단서를 결합하여 활용합니다. FBMS dataset에서 모든 방식을 능가합니다.
Introduciton
closed world에 대한 연구는 많이 진행되었지만 open-world에 대해서는 많이 진행되지 않았습니다. 하지만 실무에서 필요한 작업들은 open world에 대한 모델이 필요합니다. (never before seen data) 같이 움직이는 pxiel들은 하나의 object로 묶일거라는 통념을 바탕으로 설계하였습니다. 이를 통해 모든 움직이는 object들을 segment합니다. 딥러닝 이전의 방식들은 bottom-up, static image는 top-down 방식들을 주로 적용하였습니다.
FBMS에서 false positive에 대해 penalty를 주지 않으므로 선택했고 새로운 metric을 제시합니다. seen에 대해서는 top-down과 견주고 unseen은 압도하는 모델을 개발하였습니다.

Related Work
Spatio temporal grouping
기존의 spatio-temporal grouping에서는 각 픽셀을 optical flow로 tracking한 뒤에 descriptor에 정보를 넣고 motion similarity로 clustering하는 방식을 활용했습니다. 하지만 본 논문은 top-down 접근법을 활용합니다. 이와 유사한 연구는 CNN base로 detection을 진행한뒤 여기에서 pixel trajectories로 segmentaiton을 진행합니다. 본 논문은 여기서 더 나아가 한번에 segmentation mask를 출력합니다. heruistic method 역시 존재하며 RNN을 적용한 연구도 존재합니다.
Foreground / Background Video Segmentation
초기 방식들은 전경 후경을 나누어 binary version으로 처리하는 경우가 많았습니다. Heruistic에 의존적인 optical flow를 사용한 경우가 많았습니다. 하지만 Unseen data들에 대해서는 좋은 성능을 보여줄 수 없었습니다. 본 논문과 유사한 다른 연구들의 경우 motion 과 appearance를 따로 처리하지만 individual object instances를 처리하지는 못합니다.
Object Detection
COCO 같은 대형 dataset에서의 OD 및 segmentation은 큰 성공을 거두어 왔습니다. 하지만 여기서의 segmentation은 지정된 category에 한정 됩니다. 본 연구는 each object에 대한 instance mask의 제공을 목표로 합니다.
Approach
Two stream으로 appearance와 motion cue를 각각 동시에 처리합니다. 그 후 RPN을 통해 object의 종류에 관계없이 segment 및 OD를 합니다. 특징을 2개로 요약하면 첫째 appearance와 motion을 fuse합니다. 둘째, 부족한 dataset을 채우기 위해 image셋으로 appearance 라인을 train하고 그 후 video set을 활용합니다.
Motion based Segmentaiton & Appearance based Segmentation
FlyThings3D dataset을 활용해 motion stream에 대해 학습을 진행합니다. Appearance는 coco에 대해서 진행하고 둘에서 얻은 backbone을 Two stream model에서 활용합니다.
Two-stream Model
Mask R-CNN 구조와 유사합니다. Feature Extraction -> region proposal -> Regression으로 이어지는 파이프라인입니다.
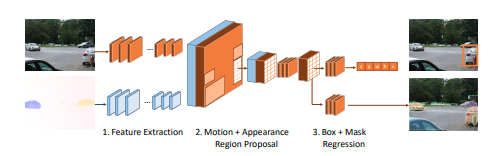
직관적으로 보면 appearance에서 놓인 object를 motion으로 보완하는 방식으로 이해하면 됩니다. 또 기존과 다르게 motion과 appearance를 fuse하여 사용했다는 의의가 있습니다.
Tracking
하이퍼파라미터 값 이하의 score를(overlap baed tracker using IoU) 가진 mask들은 제거합니다. static object에 대해서는 backbone에서 얻은 feature를 앞의 appearance based segmentation의 뒷 레이어에 적용하여 mask를 얻습니다. 두 결과를 합치고 중복은 제거하여 최종 prediciton을 완료합니다.
Evaluation
간단히 말하면 기존의 F-measure가 많은 prediciton을 하면 좋게 평가하는 경향성이 있는 것을 지적하며 새로운 F-measure를 제시한다는 것입니다.
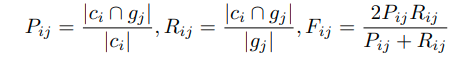

이 글은 정말 인상적이었습니다.