Abstract
학습 데이터가 없는 상황에서 unseen object에 대한 class 분류 문제를 해결하는 과정입니다. unsupervised text corpora 를 통해 visul 과 text의 semantic space를 학습해서 unseen class를 예측할 수 있게 됩니다. 동시에 기존에 학습 됐던 seen class에 대해서도 높은 accuracy를 유지합니다.
Introduction
사람이 text적 설명만으로 그 생김새를 유추한다는 것을 아이디어로 삼았습니다.
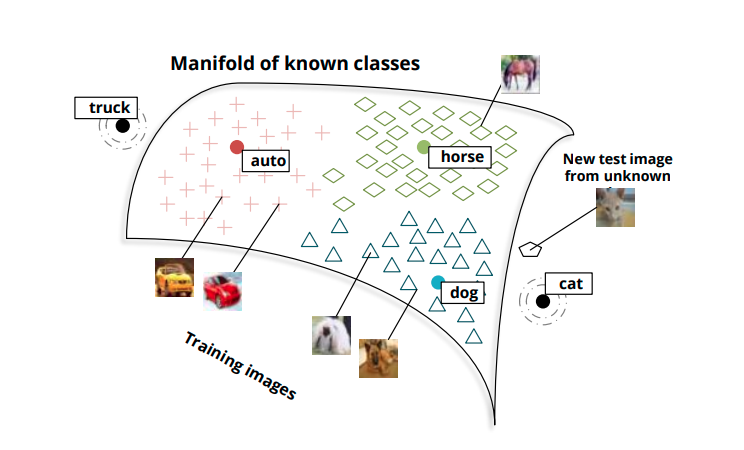
image가 들어오면 semantic space에 mapping합니다. novelty detection을 사용하는데 위의 그림처럼 known category에 해당하는 manifold에 있다면 standard classifier를 사용하여 분류를 진행하게 됩니다. 반면에 이에 해당하지 않는다면 (그림에서 truck, cat) likelihood에 따라 class 분류를 진행합니다.
Related Work
zero shot, one shot, knowledge transfer, domain adaptation, multimodal embeddings
Word and Image Representations
word의 경우 vector distribtional 특성을 활용합니다. image의 경우도 unsupervised 방식으로 feature를 추출합니다.
Projecting Images into Semantic Word Spaces
목적함수는 다음과 같습니다.
세타는 파라미터이고 f는 하이퍼볼릭 탄젠트입니다. (2 layer)
Zero shot Learning Model
테스트 셋의 이미지의 클래스 확률을 예측하는 것입니다.
에 따라 seen과 unseen을 고려해 예측합니다.
Strategies for Novelty Detection
전략 1
isometric, class specific Gaussians
seen class y에 대한 정규분포를 설정하고 특정값 이하이면 1(unseen)으로 설정합니다.
이상치에 대한 실제 확률값을 보여주지 않는 한계가 있어 2에서 보완합니다.
전략2
weighted combinated classifier를 사용해 class에 대한 조건부 확률을 구합니다. context set(가까운 k개 이웃)과 data 간에 probabilistic set distance를 구합니다. 이후 Iof값을 계산합니다. seen 클래스의 Iof값에 대한 표준편차를 Z로 둡니다. 이후 Local Outlier Probability를 구합니다.
Classification
seen은 softmax, unseen은 likelihood에 따라 클래스를 분류합니다.
Experiments
생략
Conclusion
semantic word vector와 image embedding 간의 knowledge transfer를 가능하게 합니다. 베이지안 프레임워크는 zero shot과 일반 분류를 하나로 묶을 수 있습니다.
