SQLD 헷갈리는 개념 정리

23.08.09(수) 수시로 업데이트중!
chatgpt와 함께하는 공부, 웹으로 SQL문 연습하기

이제는 한 번 볼 때 그냥 넘어가지 말자 이해하고 넘어가자
슈퍼타입, 서브타입
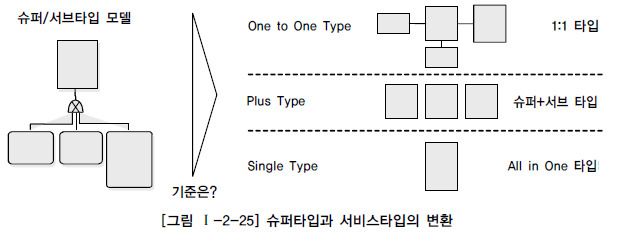
1) 슈퍼 타입(상위/부모 클래스)
- 더 일반적인 엔티티이다.
- 해당 엔티티는 다른 하나 이상의 서브타입으로 구성될 수 있다.
- ✅
슈퍼타입은 공통된 특성과 동작을 가지며, 해당 서브타입들에게 상속된다. - ex) 슈퍼타입 : 동물
-> 공통적인 특성/동작 : '이름', '나이' 등
2) 서브 타입
- 슈퍼타입의 특성을 상속받는 구체적인 엔터티를 의미한다.
- 서브타입은 ✅
슈퍼타입의 특성을 물려받으면서, 추가적인 특성을 가질 수 있다. - 서브타입은 슈퍼타입의 일반적인 특성을 구체화하여 표현할 수 있다.
- ex) 서브타입 : 포유류, 조류
- 슈퍼타입의
동물의 특성인이름과나이를 물려받으면서 특성을 추가할 수 있다. - 추가적인 특성: 날 수 있는지 여부 등
1:1 타입
- 두 개체 (테이블)간에 일대일 관계가 있는 경우를 나타낸다.
- 두 테이블을
하나로 통합하는 것이 더 효율적일 때사용된다.
All in One 타입
-
여러가지 유형의 데이터를 하나의 테이블에 모두 통합하여 저장하는 방식을 의미한다.
-
모든 관련 데이터를 하나의 테이블에 집중하여 관리하는 접근 방식이다.
-
데이터의 구조가 단순하거나, 데이터베이스의 규모가 작을 때 사용될 수 있다. -
ex) 인적정보 테이블: 이름, 나이, 성별, 직업 등..
- 이러한 정보를 모두 하나의 테이블에 통합하여 저장하는 것
본질 식별자와 인조식별자
본질 식별자
- 데이터베이스에서 개체를 고유하게 식별하는 데 필요한 필드 또는 속성이다.
- 즉, 개체 자체가 가지고 있는 고유한 속성을 사용하여 식별하는 방법이다.
- ex) 고객 : 고객ID(본질식별자)
- 각 고객은 자신만의 고유한 고객ID 값을 가지고 있으며, 이를 통해 데이터베이스에서 고객을 고유하게 식별할 수 있다.
인조식별자
- 개체를 고유하게 식별하는 데에
의미없는 인위적인 값이다. - 데이터베이스에서 자동으로 생성되는 숫자나 해시코드와 같은 값이 사용된다.
- 인조식별자는 개체가 생성될 때마다 자동으로 할당되며, 개체 자체의 고유한 특성과는 무관하게 사용된다.
- ex) 고객 : 고객번호(숫자로 구성된 자동생성된 번호, 인조식별자)
- 개체 자체의 특성과는 무관하며, 각 고객에게 자동으로 할당된다.
- 인조 식별자를 사용하는 경우, 본질식별자가 가지고 있는 의미있는 값보다는 단순히 개체를 식별하기 위한 용도로 사용된다.
- 이는 주로 성능 향상, 데이터의 복잡성을 줄이는 데에 도움이 될 수 있다.
식별자와 비식별자
| 식별자 | 비식별자 | |
|---|---|---|
| 개체 | 고객 | 고객 |
| 고객ID | 고객이름,고객 주소 등 |
분산 데이터베이스의 투명성
사용자나 응용 프로그램이 데이터를 접근하거나 조작할 때,
데이터가 분산되어 저장되어 있는지 여부를 숨기는 개념을 의미한다.
1. 분산 투명성(Distribution Transparency)
- 사용자나 응용 프로그램이 데이터가 여러 노드에 분산되어 저장되어 있는지 알 필요가 없도록 한다.
- 사용자는 데이터가
단일 데이터베이스에 저장된 것처럼 접근하고 조작할 수 있다.
2. 위치 투명성 (Location Transparency)
-
데이터가 실제로 어느 노드에 저장되어 있는지를 숨김으로써,
사용자가 데이터의 물리적인 위치를 알 필요가 없도록 한다. -
사용자는 논리적인 이름 또는 별칭을 통해 데이터에 접근할 수 있다.
3. 병합 투명성 (Merging Transparency)
-
분산 데이터베이스에 저장된 데이터가 여러 개의 조각으로 나누어져 있더라도, 사용자에게는 하나의 논리적인 데이터로 표현되도록 한다.
-
사용자는 데이터의 조각들을 신경쓰지 않고, 하나로 묶인 데이터를 조작할 수 있다.
4. 복제(중복) 투명성(Replication Transparency)
- 데이터가 여러 개의 노드에 복제되어 저장되어 있더라도, 사용자에게는 하나의 데이터만 존재하는 것처럼 제공한다.
- 사용자는 데이터의 복제본들을 신경쓰지 않고 단일 데이터를 조작할 수 있다.
이러한 투명성은 분산 데이터베이스 시스템의 복잡성을 숨기고,
분산 데이터베이스의 투명성은 데이터베이스 시스템의 설계와 구현에 중요한 측면으로 고려되며, 사용자 경험과 시스템의 유지보수를 개선하는 데 기여합니다.
사용자에게 단순하고 통일된 인터페이스를 제공하여 데이터 액세스를 편리하게 만듭니다.
옵티마이저
SQL을 가장 빠르고 효율적으로 수행할 최적(최저비용)의 처리 경로를 생성해주는 DBMS 내부의 핵심 엔진이다.
- DBMS에 내장된 옵티마이저가 자동으로 처리경로를 생성 =>
실행계획
(비용 기반 옵티마이저)
1. 사용자가 던진 쿼리 수행을 위해 후보군이 될 수행 계획을 찾는다.
2. 데이터 딕셔너리에 미리 수집해놓은 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상 비용을 선정
3. 각 실행계획을 비교해 최저비용을 갖는 하나를 선택한다.
옵티마이저 종류
1) 규칙기반 옵티마이저 (Rule-Based Optimizer)
- 휴리스틱 옵티마이저.
- 미리 정해놓은 규칙에 따라 액세스 경로를 평가하고 실행계획을 선택한다.
규칙: 액세스 경로별 우선순위로서, 인덱스 구조, 연산자, 조건절 형태가 순위를 결정짓는 주요인
2) 비용 기반 옵티마이저(Cost-Based Optimizer)
-
비용: 쿼리를 수행하는 데 소요되는 일량 또는 시간 -
미리 구해놓은 테이블과 인덱스에 대한 여러 통계 정보를 기초로 각 오퍼레이션 단계별 예상 비용을 산정하고,
이를 합산한 총 비용이 가장 낮은 실행계획을 선택한다. -
비용 산정 시 사용되는 오브젝트 통계 항목
- 레코드 개수, 블록 개수, 평균 행 길이, 칼럼 값의 수, 칼럼 값 분포, 인덱스 높이(Height), 클러스터링 팩터 등

SQL 최적화 과정
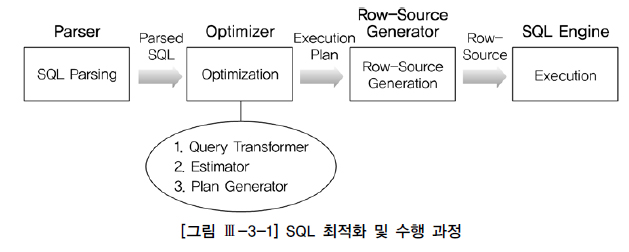
1. SQL Parsing
- SQL 문장을 이루는 개별 구성 요소를 분석, 파싱해서 파싱 트리(내부적인 구조체)를 만든다.
- 'User'가 쿼리문을 실행시키면 DBMS가
요청받은 쿼리를 실행시키기 위해 하는 행위- Parsing은 문법체크(Syntax check), 의미(Semantic check) & 권한체크를 진행
- 'User'가 쿼리문을 실행시키면 DBMS가
- 문법적 오류가 없는지, 의미상 오류가 없는지 확인한다. (
Syntax,Semantic체크)
2. Optimizer
1) Query Transformer
- 파싱된 SQL을 좀 더 일반적, 표준적인 형태로 변환
2) Estimator
- 오브젝트 및 시스템 통계 정보를 이용해 쿼리 수행 각 단계의 선택도, 카디널리티, 비용 계산 -> 실행계획 전체에 대한 총 비용을 계산
3) Plan Generator : 후보군이 될만한 실행계획 생성
3. Row-Source Generator
-
옵티마이저가 생성한 실행계획을 SQL 엔진이 실제 실행할 수 있는 코드(또는 프로시저)형태로 포맷팅
4. SQL Engine
-
SQL을 실행
가상 테이블
CREATE TABLE sales (
product VARCHAR(50),
region VARCHAR(50),
quarter VARCHAR(10),
amount_sold NUMBER
);
INSERT INTO sales VALUES ('Product A', 'Region 1', 'Q1', 1000);
INSERT INTO sales VALUES ('Product A', 'Region 1', 'Q2', 1500);
INSERT INTO sales VALUES ('Product A', 'Region 2', 'Q1', 1200);
INSERT INTO sales VALUES ('Product A', 'Region 2', 'Q2', 1800);
INSERT INTO sales VALUES ('Product B', 'Region 1', 'Q1', 800);
INSERT INTO sales VALUES ('Product B', 'Region 1', 'Q2', 1000);
INSERT INTO sales VALUES ('Product B', 'Region 2', 'Q1', 900);
INSERT INTO sales VALUES ('Product B', 'Region 2', 'Q2', 1100);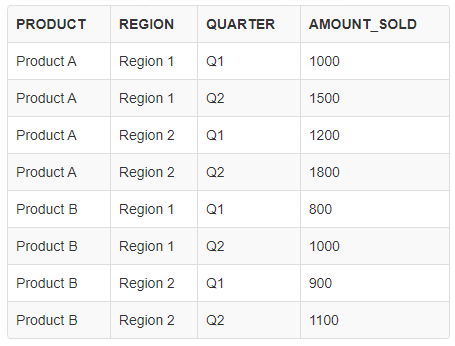
ROLLUP 함수
- 그룹화 수준을 지정하며,
지정한 열들에 대한 모든 가능한 조합에 대한 그룹화를 수행select data1,data2,count(*) from test group by rollup(data1,data2)
- 각 a, b, c의 소계 + 전체 총계 생성
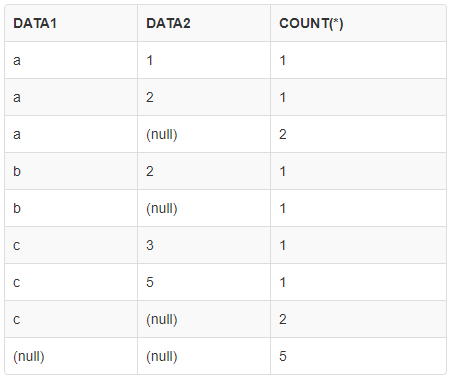
ROLLUP 예시2
SELECT product, region, quarter, SUM(amount_sold) AS total_sales FROM sales GROUP BY ROLLUP (product, region, quarter);
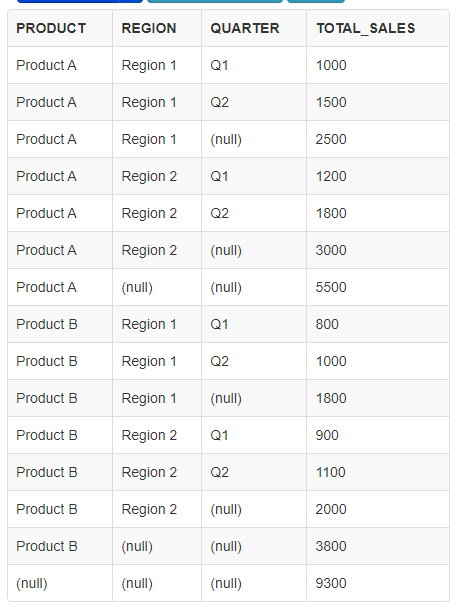
CUBE
- 모든 가능한 조합에 대한 그룹화를 수행한다.
SELECT product, region, quarter, SUM(amount_sold) AS total_sales FROM sales GROUP BY CUBE (product, region, quarter);```
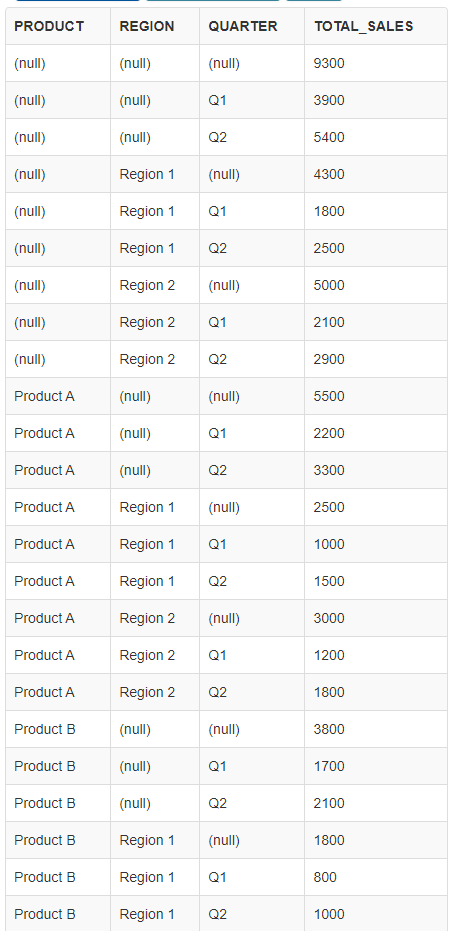
(테이블 결과 아래 잘림!)
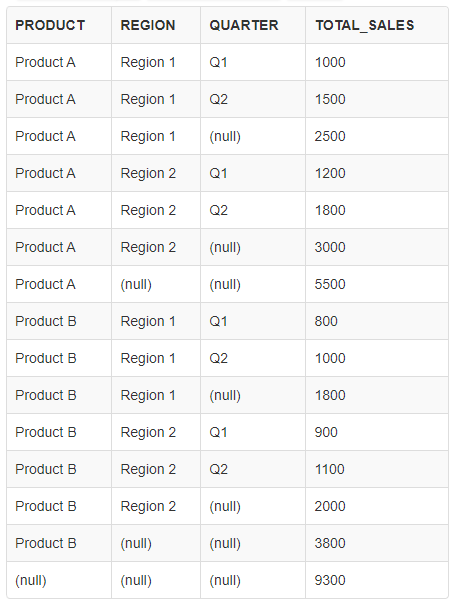
GROUPING SETS
- 사용자가 지정한 그룹화 수준에 따라 그룹화를 수행
SELECT product, region, quarter, SUM(amount_sold) AS total_sales FROM sales GROUP BY GROUPING SETS ( (product, region, quarter), (product, region), (product), () );
- 순서가
1) (product, region, quarter),
2) (product, region),
3) (product)
4) ()가 있다.
GROUPING SETS 다른 SQL문으로 확인해본다면?
SELECT product, region, quarter, SUM(amount_sold) AS total_sales FROM sales GROUP BY GROUPING SETS ( (product, region, quarter), (region, quarter), () );이부분을 바꿔 보았다. ㅋㅋ
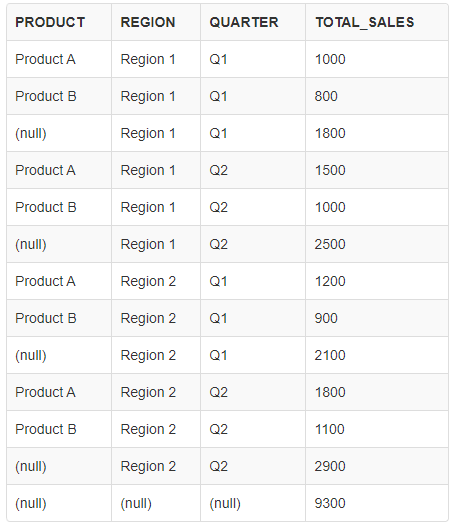
- () 이 부분은 맨 아래에 출력되나보다.
ROLLUP과 GROUPING SETS의 차이는 뭐야?
-
ROLLUP:
계층적 집계-
데이터를 계층적으로 집계하는 데 사용되는 기능
-
주어진 열 집합에 대해 계층 구조를 생성하여 다양한 수준의 집계 결과를 반환한다.
-
이때,
각 계층에서 총계를 생성한다. -
ex) 날짜(Date)와 지역(Region)열을 가진 테이블에서 ROLLUP을 사용하면,
날짜별+지역별 총계/날짜별 전체 총계
-
-
GROUPING SETS :
다양한 열 집합에 대한 집계를 위함-
여러 열 집합에 대한 다차원 집계를 수행하는 데 사용
-
이 기능을 사용하면 여러개의 열 집합을 지정하여 각 열 집합에 대한 집계 결과를 반환할 수 있다.
-
ROLLUP과 달리 계층 구조를 생성하지 않고, 지정된 열 집합대로 집계 결과를 반환한다. -
ex) 날짜(Date), 지역(Region), 제품(Product) 열을 가진 테이블에서 사용하면
날짜별/지역별/제품별, 그리고 모든 조합에 대한 집계 결과를 한번에 볼 수 있다.
-
JOIN
NL 조인(Nested Loop Join)
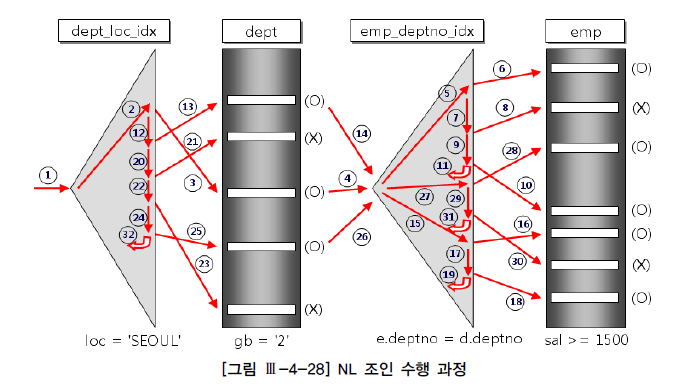
-
가장 기본적인 조인 방법
-
두 테이블의 각 행을 한 번씩 모두 비교하는 방식
- ex) 주문(Order)테이블과 고객(Customer) 테이블이 있다고 가정,
주문 테이블의 각 주문과 고객 테이블의각 고객을 순차적으로 비교하여
조건을 만족하는 경우 결과를 반환.
- ex) 주문(Order)테이블과 고객(Customer) 테이블이 있다고 가정,
Nested Join을 수행하는 순서
- Outer Query 작성
: 이 쿼리는 내부 쿼리의 결과를 사용하게 된다. 보통 바깥쪽 쿼리는 결과를 필터링하거나 정렬하는 데 사용된다.- Inner Query 작성
: 조인할 테이블들을 결합하고 결과를 생성한다.- Inner Query에 조인 조건 적용
: 내부 쿼리에서 조인 조건을 정의- Nested Join 적용
: 바깥쪽 쿼리에서 내부 쿼리를 서브쿼리로 사용하여 중첩된 조인을 수행한다. 바깥쪽 쿼리의 결과와 내부 쿼리의 결과가 결합되어 최종 결과가 생성된다.
정렬 병합 조인(Sort-Merge Join)

-
조인할 테이블을 먼저 정한 다음, 정렬된 상태에서 두 테이블을 합치는 방식
- ex) 학생(Student)와 성적(Grades) 테이블 조인 가정,
학생과 성적을학생의 ID를 기준으로 정렬하고,
정렬된 상태에서두 테이블을 하나씩 비교하여 조인합니다.
- ex) 학생(Student)와 성적(Grades) 테이블 조인 가정,
Sort-Merge join 순서
- 각 테이블 정렬
: 먼저 조인할 두 테이블을 조인할 열을 기준으로 정렬
이때, 외부정렬(external sort) 알고리즘이 사용된다.- Merge
: 정렬된 두 테이블을 동시에 순회하며 조인 기준 열의 값들을 비교. 이렇게 비교하면서 일치하는 값을 찾아낸다.
: 만약 값이 일치한다면, 조인 결과에 해당하는 행을 생성- 조인 결과 생성
: Merge 단계에서 일치하는 조인 기준 값을 찾아내어 조인결과를 생성, 이때 각 테이블의 정렬된 상태를 유지하면서 조인 작업을 수행한다.
장점 : 두 테이블을 미리 정렬하는 것이기 때문에, 일부 상황에서 다른 조인 알고리즘보다 빠른 성능을 보일 수 있다는 점
-
두 테이블을 정렬하는 작업이 추가되기 떄문에, 메모리나 디스크 공간을 많이 사용할 수 있다.
-
대량의 데이터를 다룰 때 유용하며, 데이터베이스 시스템이 정렬 알고리즘을 효율적으로 처리할 수 있을 때 높은 성능을 보인다.
해시 조인(Hash Join)
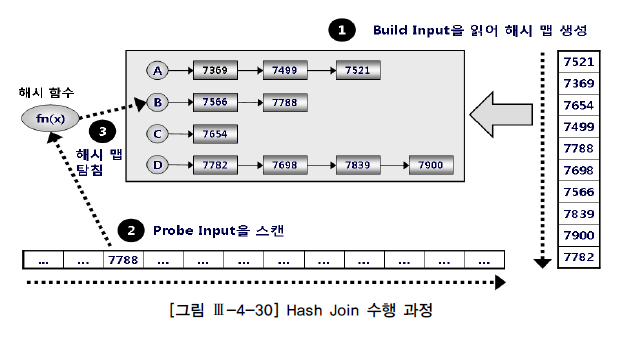
-
조인할 테이블 중 하나의 테이블을 해시 함수를 사용하여 해시 테이블로 반환한 후,
-
나머지 테이블을 순회하면서 해시 테이블에서 조인 조건을 만족하는 값을 찾는 방식.
- ex) 제품(Products)테이블과 주문상세(Order Details) 테이블을 조인한다고 가정,
제품 테이블을 해시 테이블로 변환 후, 주문 상세 테이블을 순회하며
각 주문에 맞는 제품을해시 테이블에서 빠르게 찾아 조인
- ex) 제품(Products)테이블과 주문상세(Order Details) 테이블을 조인한다고 가정,
해시 테이블이 뭔데?
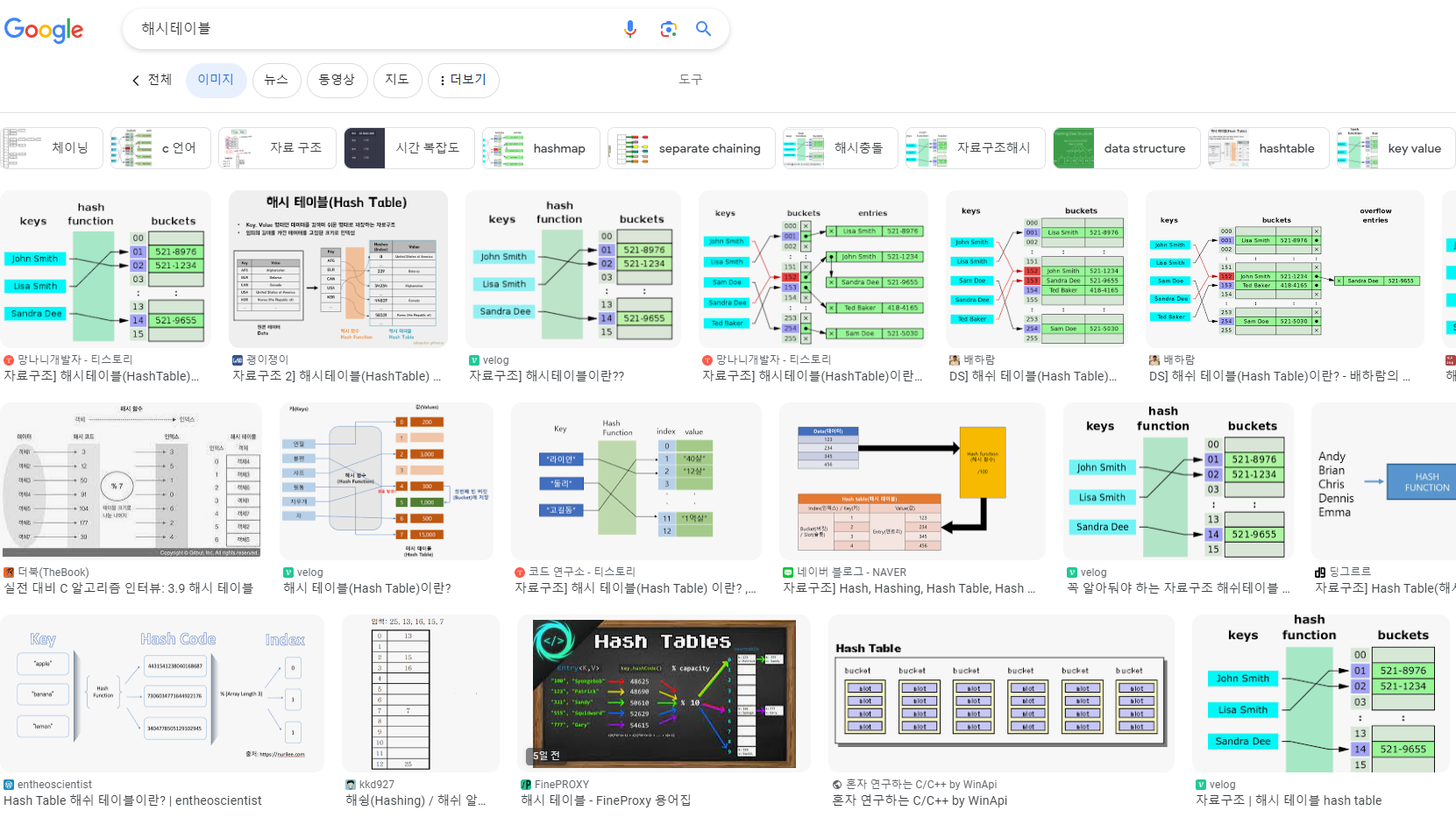
-
데이터를 효율적으로 저장, 검색하기 위한 자료구조
-
해시 테이블은
해시 함수라는 함수를 사용하여 데이터를 키-값 쌍으로 저장, 이후에 특정 키를 사용하여 해당하는 값을 빠르게 검색한다. -
일종의
배열로 생각할 수 있다. 각 배열의 원소는버킷(bucket)이라 불리는 공간이며, 각 버킷은 특정 해시값에 해당하는 데이터를 저장한다. -
해시 함수는 주어진 키를 받아 해당 키의 해시값을 계산하고, 이 해시값은 배열의 인덱스로 사용된다.
-
이렇게 하면 키에 대응하는 값이 배열 내 특정 위치에 저장되고, 검색할 때도 해당 키의 해시값을 계산하여 그 위치에 저장된 값을 빠르게 찾을 수 있다.
해시테이블의 장점 : 빠른 검색 속도
- 해시 함수를 잘 설계하면 데이터가 어디에 저장되어 있는지 빠르게 계산할 수 있기 때문
- 그러나! 해시 함수의 충돌 문제를 고려해야 한다.
- 충돌은 서로 다른 키가 같은 해시값에 매핑되는 상황을 의미, 충돌 처리기법 사용
- 체이닝(Chaining), 개발 주소법(open addressing) 등
- 데이터베이스, 캐싱, 인덱싱, 검색엔진 등 다양한 분야에서 활용, 데이터의 효율적인 관리와 빠른 검색을 위해 중요한 자료구조
해시테이블에서 해시 함수를 왜 사용하는거야? (chat gpt)
해시 테이블에서 해시 함수를 사용하는 이유:
데이터의 효율적인 저장과 검색을 위해서
- 해시 테이블은 해시 함수를 활용하여 데이터를 빠르게 저장하고 검색할 수 있는 자료구조
1. 고속 검색
: 해시 함수는 데이터를 고유한 해시 값으로 변환합니다. 이 해시 값은 배열의 인덱스로 사용되어 데이터를 빠르게 저장하고 검색할 수 있게 해줍니다. 해시 테이블에서 데이터를 찾는 데 걸리는 시간은 대개 O(1)에 가깝습니다.
2. 데이터 분산
: 해시 함수는 데이터를 해시 값으로 변환할 때 각 데이터를 고르게 분산시키는 역할을 합니다. 따라서 데이터가 균등하게 흩어져 저장되므로 해시 테이블의 잠재적인 충돌 문제를 줄여줍니다.
3. 중복 데이터 식별
: 해시 함수를 사용하면 서로 다른 데이터에 대해 다른 해시 값을 생성합니다. 이로써 데이터 중복을 식별하고 효율적으로 처리할 수 있습니다.
4. 데이터 무결성 확인
: 해시 함수를 사용하여 데이터의 해시 값을 계산하고 저장해두면, 이를 이용하여 데이터의 무결성을 확인할 수 있습니다. 나중에 데이터가 변조되었는지 여부를 확인하는 데 사용됩니다.
5. 자료구조 구현
: 해시 테이블은 해시 함수를 기반으로 구현되는 자료구조 중 하나입니다.
- 해시 테이블은 키와 값의 쌍으로 데이터를 저장하며,
키를 해시 함수에 적용하여 배열 인덱스로 변환하여 데이터를 저장하거나 검색합니다.
6. 캐싱
: 해시 함수를 사용하여 데이터를 캐시에 저장하면, 캐시에서 원하는 데이터를 빠르게 검색할 수 있습니다. 해시 값을 통해 캐시 내부의 위치를 신속하게 파악할 수 있습니다.
좋은 글 감사합니다.