https://github.com/lovedlim/tensorflow/tree/main
케라스의 목적
딥러닝 라이브러리를 쉽고 간결한 코드로 실행할 수 있게 만들어주는 것
직관적, 사용자 친화적으로 설계되어 있어 코딩의 난이도가 어렵지 않다.
But, 복잡한 구조의 모델 구현과 사용자 정의 훈련을 위해서는 텐서플로의 저수준 API를 사용해야 한다는 한계점이 존재한다.
하이퍼파라미터(hyper-parameter)
- 딥러닝뿐만 아니라, 머신러닝 모델을 훈련할 때 사용자가 직접 설정해주는 설정 값
- 👉사용자가 어더한 값을 설정하느냐에 따라 모델의 성능 및 결과가 달라지기 때문에 중요!
모델이 훈련하면서 가중치(weights)와 편향(bias)은 자동 업데이트되고 조정되지만,
그 외 학습 속도나 반복 훈련 횟수 등 사용자가 직접 설정해야 하는 값들이 매우 많다.
🙄 그런데 가중치와 편향이 뭐야?
머신러닝에서 "가중치(Weights)"와 "편향(Bias)"는 모델의 핵심적인 구성 요소로, 입력 데이터와 모델의 출력 사이의 관계를 정의하는 역할을 합니다.
가중치(Weights)
-
머신러닝 모델은 입력 데이터로부터 특성이라고 불리는 다양한 정보들을 활용하여 예측을 수행합니다.
-
이때, 각각의 특성이 얼마나 중요한지를 조절하는 역할을 하는 것이
가중치입니다. -
모델 내에서 입력 데이터의 각 특성(feature)에 곱해지는 값으로, 입력 특성이 모델의 출력에 미치는 영향을 조절
모델은 이 가중치를 학습하여 데이터의 패턴을 학습하고 입력과 출력 사이의 관계를 나타냅니다.
가중치는 모델의 학습 과정에서 조정되며, 입력 특성의 중요도를 결정합니다.
가중치 예시
예를 들어, 단순한 선형 회귀 모델을 생각해보겠습니다.
입력 데이터가 두 가지 특성인길이와너비라고 가정해봅시다. 모델은 이 두 특성을 기반으로 꽃의 종류를 예측하려고 합니다.
- 가중치가 작을 때
모델은 해당 특성이 출력에 큰 영향을 주지 않는다고 판단합니다.
예를 들어, 꽃의 길이가 조금 길어져도 종류 예측에 큰 영향을 미치지 않을 것으로 판단합니다.- 가중치가 클 때
모델은 해당 특성이 출력에 매우 큰 영향을 주는 것으로 판단합니다.
예를 들어, 꽃의 너비가 조금 변화해도 종류 예측에 큰 영향을 미칠 것으로 예상합니다.
이렇게 각 특성에 가중치를 곱함으로써 모델은 입력 데이터의 다양한 특성 간에 중요한 관계를 파악하며 예측을 수행합니다.
- 가중치는 모델이 학습하면서 데이터의 패턴을 익히는 과정에서 최적화되어, 입력 특성의 중요도를 조절하게 됩니다.
편향(Bias):
- 편향은 모델의 출력에 더해지는 상수로, 입력 특성이 모두 0일 때의 기대값을 나타냅니다.
편향을 사용함으로써 모델이 입력 특성이 0인 경우에도 출력이 0이 아닌 다른 값으로 시작할 수 있습니다.
편향은 모델이 데이터를 더 유연하게 표현할 수 있도록 도와줍니다.
이를 간단한 수식으로 나타내면 다음과 같습니다:출력= (가중치×입력)+편향
가중치와 편향은 모델의 학습 과정에서 최적화되는 파라미터입니다.
모델은 학습 데이터와 실제 출력 값을 비교하여 가중치와 편향을 조정하여 모델의 예측을 최적화하려고 시도합니다. 이렇게 최적화된 가중치와 편향을 사용하면 입력 데이터에 대한 모델의 예측이 더 정확해지게 됩니다.
편향 추가 설명

하이퍼파라미터 튜닝(tuning)
- 모델의 예측 성능을 높이기 위해 하이퍼파라미터 값들을 조절하는 행위
과소적합(undefitting) vs 과대적합(overfitting)
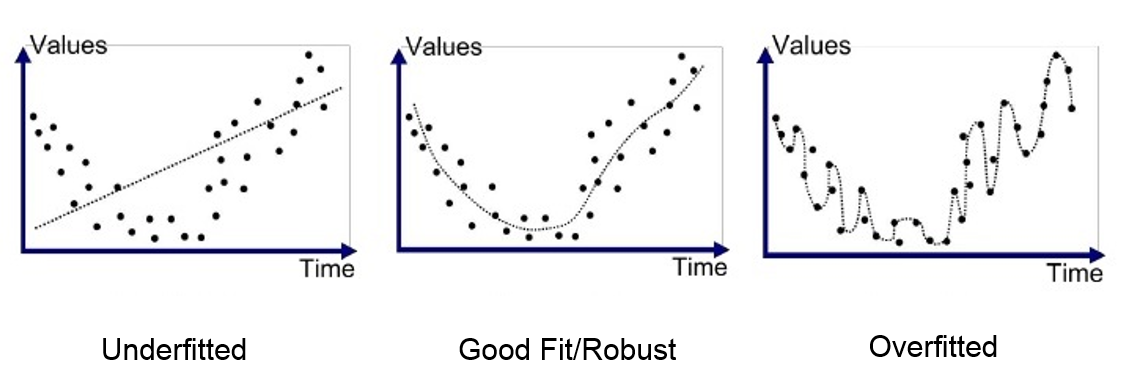
| 과소적합 | 과대적합 |
|---|---|
| 모델이 충분히 학습되지 않은 경우 예측 성능이 떨어지는 것 | 학습 데이터를 지나치게 반복학습하게 되어 과하게 적합된 상태 |
머신러닝 학습의 데이터: 훈련용 데이터와 예측용 데이터
-
훈련용 데이터 : 머신러닝 모델이 학습할 데이터,
training set, train set -
예측용 데이터 : 정답 레이블(label)이 없는 머신러닝 모델이 예측해야 하는 대상 데이터,
test set
주어진 훈련 데이터(traing set)에서 패턴 학습을 통해 모델을 완성해 나간다.
훈련용 데이터를 반복적으로 학습하면서 모델은 사람이 발견하지 못하는 패턴을 발견함으로써
사람의 예측 성능을 뛰어 넘는 모델을 생성할 수 있다.
- 하지만, 예측 데이터가 모델이 학습한 데이터와 다른 분포를 갖거나, 특정 레이블에 편향된 데이터로 이루어졌다면 예측 성능이 현저히 떨어지게 된다.
-
예측 데이터와 분포가 동일하게 구성해야 하며,
불필요한 노이즈는 데이터 분석 및 전처리를 통해 해소해야 한다. -
훈련 데이터의 일부를 검증 데이터로 활용해 검증 성능이 가장 좋은 구간을 모델의 가장 이상적으로 학습된 지점이라 판단하는 방법으로 최종 모델을 결정한다.
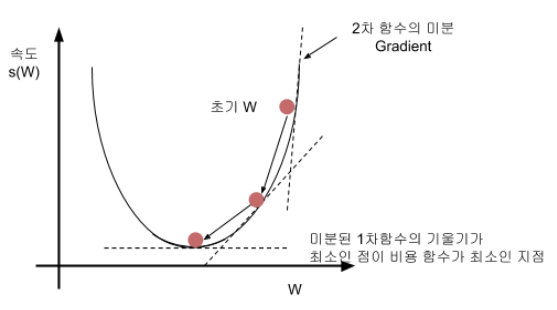
경사하강법(gradient descent)
- 모델 내부의 가중치(weight)에 대한 미분값을 구하고 목적 함수 값이 낮아지는 방향으로 차감하면서 최소함수값을 갖도록 하는 방법
출처
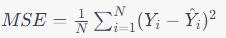
1/N을 책에서는 1/2로 표기했는데, 가중치에 대한 그래디언트(gradient)를 계산하기 쉽도록 추가된 상수값이다.
y = wx + b라는 샘플 데이터셋 생성하는 함수를 정의, w와 b값을 지정하여 주어진 x에 대한 y값을 생성한다.
딥러닝 프로세스
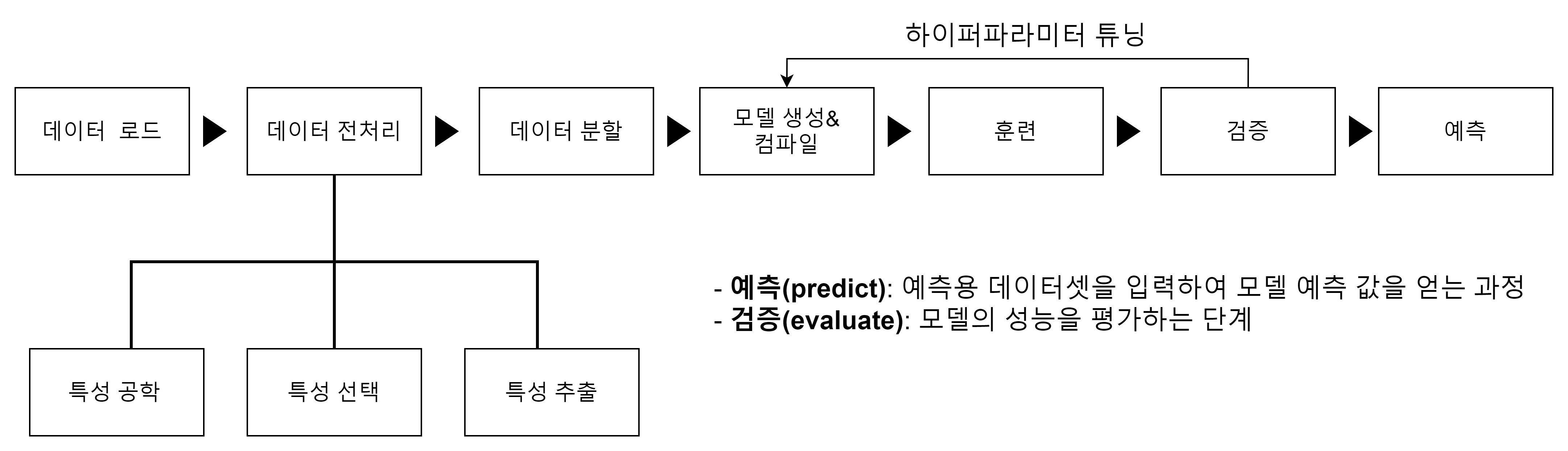
1. 데이터 전처리
- 데이터를 모델에 주입하기 전 데이터를 가공하는 단계
- 배열의 차원 변경 / 스케일 조정
2. 모델 생성
- 모델의 구조를 정의하고 생성하는 단계
1) 순차적 구조 모델 :Sequential API
2) 다중 입력 및 출력, 복잡한 구조 모델:Functional API/Model Subclassing
3. 모델 컴파일
- 딥러닝 모델 구조를 정의하고 생성한 뒤, 생성된 모델 훈련에 사용할 손실함수(loss), 옵티마이저(optimizer), 평가지표(metrics) 등을 정의
- 모델 인스턴스에 compile()메소드를 적용, 여러가지 속성 값을 설정한다. =>
컴파일 단계
4. 모델 훈련
- 모델을 훈련하는 단계
- fit() 함수에 모델 훈련에 필요한 정보를 매개변수(또는 파라미터)로 전달
- 훈련 데이터셋, 검증 데이터셋, epoch, 배치(batch) 크기 및 콜백(callback) 함수 등을 지정
5. 모델 검증
- 훈련이 완료된 모델 검증
- 검증 데이터셋 모델에 입력하고, 모델의 예측값을 정답과 비교하여 평가지표를 계산
- 반환된 검증 결과를 토대로 잠재적 모델의 성능 평가 진행
검증 결과를 바탕으로, 다시 모델 생성 단계로 돌아가 모델 수정을 하고, 컴파일 및 훈련 과정을 거쳐 재평가하는 단계를 통해 목표 성능에 도달할 때까지 이 과정을 반복
6. 모델 예측
- 훈련과 검증이 완료된 모델로 테스트셋에 대하여 모델이 예측하고 그 결과를 반환한다.
단순 신경망 훈련
선형회귀
- 회귀 분석: 하나 이상의 독립 변수들이 종속 변수에 미치는 영향을 추정하는 통계 기법
단순 선형 회귀: 하나의 X가 Y에 미치는 영향을 추정, 1차 함수 관계
쉽게 설명하는 선형회귀
선형 회귀는 수학을 사용해서 어떤 것들 사이에 있는 관계를 이해하는 방법 중 하나입니다. 예를 들어, 너가 공부한 시간과 시험 성적 사이의 관계를 알고 싶다고 해봐요.
선형 회귀는 이럴 때 도움이 돼요.
- 공부한 시간과 시험 성적을 살펴보면, 시간이 늘어날수록 성적도 더 잘 나올 것 같아 보여요. 이걸 수학적으로 표현하자면, 시간(x)과 성적(y) 사이에 어떤 직선이 있다고 가정해봐요.
- 선형 회귀는 그 직선을 찾는 방법이에요. 이 직선은 y = ax + b 형태로 나타낼 수 있어요. 여기서 a는 시간과 성적 사이의 관계를 나타내는 기울기이고, b는 그래프가 y축을 얼마나 위로 올라가는지를 나타내는 절편이에요.
- 데이터를 모아서 그래프를 그려보고, 그래프와 가장 가까운 직선을 찾아내는 거야. 그럼 이 직선을 사용해서 공부한 시간으로부터 예상되는 시험 성적을 예측할 수 있어요.
- 간단히 말하자면, 선형 회귀는 두 가지 변수 사이의 관계를 직선으로 표현하여 하나의 변수를 다른 변수로 예측하는 방법이에요.
y = ax + b: 1차 함수식
- X: 독립변수
- Y: 종속변수
- 1차 함수식의 a: (그래프의) 기울기
- 딥러닝에서는 기울기 a 대신 가중치(weight)을 의미하는 w를 더 많이 사용한다.
y = wx+b
- 딥러닝에서는 기울기 a 대신 가중치(weight)을 의미하는 w를 더 많이 사용한다.
- b: 절편(그래프의 높낮이)
뉴런(Neuron)
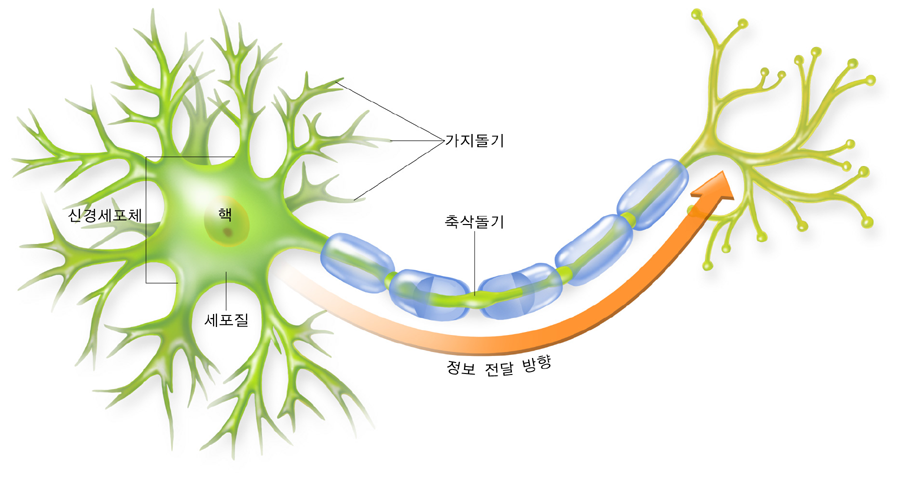
- 인공 신경망 모델을 구성하는 하나의 신경
뉴런= 노드(node)- 신경망은 여러 개의 레이어(layer)를 가지며, 1개의 레이어는 1개 이상의 뉴런으로 구성
- 뉴런 내부에는 가중치 조재, 모델이 훈련을 진행하면서
오차 역전파를 통해 뉴런의 가중치가 업데이트 된다.
오차 역전파 쉽게 설명하기(gpt)
물론입니다! 오차 역전파(Backpropagation)를 초등학생이 이해할 수 있는 간단한 예시를 통해 설명해보겠습니다.
- 가정:
당신이 친구에게 숫자 게임을 가르치려고 합니다. 이 게임에서는 숫자 하나를 입력으로 주면, 그 숫자에 3을 곱하고 2를 더해서 결과를 계산합니다. 그리고 그 결과에 5를 더해서 최종 결과를 얻습니다.
단계별로 설명해보겠습니다:
숫자 입력:
친구가 4라는 숫자를 입력했습니다.
1️⃣첫 번째 단계: 3을 곱하고 2를 더하기:
친구가 입력한 4를 3과 곱해서 12를 얻습니다.
2️⃣그리고 2를 더해 14를 얻습니다.
3️⃣두 번째 단계: 5를 더하기:
첫 번째 단계에서 얻은 14에 5를 더해 최종 결과인 19를 얻습니다.
이제 여기서 역전파를 이해해봅시다. 역전파란, 최종 결과에서부터 역순으로 각 단계의 연산을 역으로 따라가며 각 단계에서 얼마나 잘못되었는지를 계산하는 것입니다.
👉역전파
오차 계산:
친구가 게임을 플레이한 결과는 19이지만, 실제 정답은 어떤 숫자였을까요? 예를 들어, 실제 정답은 30이었다고 해봅시다.
이제 19와 30의 차이, 즉 오차를 계산합니다. 30에서 19를 빼면 11이 됩니다.
👉역전파: 각 단계의 영향 계산:
이제 오차를 각 단계로 역으로 전달하면서 그 단계에서의 영향을 계산합니다.
5를 더한 단계에서의 영향은 11입니다.
2를 더하고 3을 곱한 단계에서의 영향은 11을 5로 나눈 값인 2.2입니다.
이렇게 계산한 각 단계에서의 영향을 활용하여 게임의 규칙을 더 잘 배우도록 조정할 수 있습니다. 오차를 줄이기 위해 3을 곱하는 단계나 2를 더하는 단계에서 조금씩 수정하면, 미래에 더 정확한 결과를 얻을 수 있게 됩니다.
💗요약하면, 오차 역전파는 게임의 규칙을 더 잘 학습하도록 계산된 오차를 각 단계로 역순으로 전달하고,
각 단계에서의 영향을 계산하여 게임을 더 잘할 수 있도록 도와주는 것입니다.Dense 레이어
- 심층 신경망 모델을 구성하는 가장 기본 레이어
- 완전 연결층
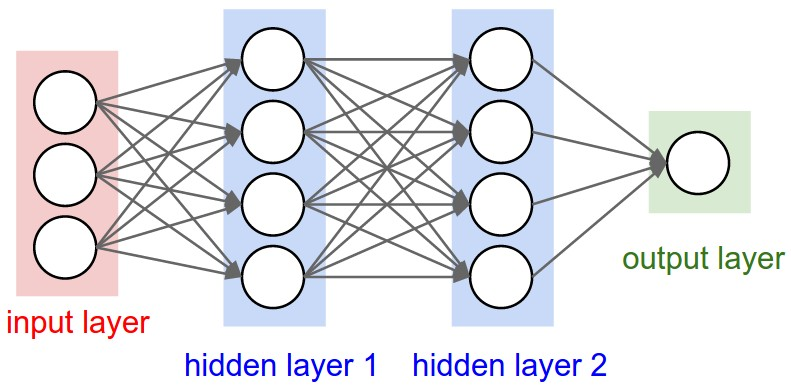
- 입력 레이어 : 3개의 뉴런, 출력 레이어는 1개의 뉴런
- 정보(텐서)의 흐름을 나타내는 화살표로 연결되어 있어 완전 연결층이라 한다.
지도학습
지도학습은 supervised learning으로, 정답이 있는 데이터를 활용해 데이터를 학습시키는 것
- 모델에 주입할 입력 데이터를
피처(feature), 정답은레이블(label)- 지도학습 외에도 비지도 학습, 강화학습, 준지도학습 등이 있다.
Sequential API
- 텐서플로 케라스는 세 가지 방식으로 모델을 생성할 수 있다.
- 층을 이어붙이듯 시퀀스에 맞게 일렬로 연결하는 방식
- 입력 레이어부터 출력 레이어까지 순서를 갖는다.
컴파일
- 모델의 훈련 과정에서 적용할 옵티마이저(optimizer), 손실함수(loss), 평가지표(metrics) 정의
- 3가지 방법으로 지정 :
클래스 인스턴스,함수혹은사전 정의된 문자열
옵티마이저란?
신경망을 학습시킬 때,
모델의 가중치와 편향을 업데이트하는 알고리즘
학습 과정에서 옵티마이저는 손실 함수의 값을 최소화하는 방향으로 모델 파라미터를 조정하여 최적의 성능을 얻도록 도와줍니다.
심층 신경망으로 이미지 분류
딥러닝: 모델에 여러 층을 구성해 깊이 있다는 의미에서 딥러닝이라고 부른다.
데이터넷은 케라스 내장 데이터셋을 가져와 사용한다.
정규화
정규화는 데이터의 전체 범위를 0~1 사이의 값을 가지도록 한다.
- 정규화하는 이유: 입력 데이터가 정규화되어 모델이 학습하는 경우 경사하강법 알고리즘에 의한 수렴 속도가 비정규화된 입력 데이터를 가질 때보다 더 빨리 수렴하기 때문이다.
- 정규화는 입력 데이터의 분포를 조정하여 학습 과정을 안정화시키는 방법입니다.
배치 정규화
-
배치 정규화(Batch Normalization)는 딥러닝 모델에서 학습을 더 안정적으로 하고 빠르게 진행할 수 있도록 도와주는 기술입니다.
-
배치 정규화는 정규화를 미니배치(mini-batch) 단위로 수행하며, 학습 도중에 각 미니배치의 평균과 표준편차를 사용하여 입력 데이터를 조정합니다.
🤔딥러닝에서의 배치(batch)란?
- 딥러닝에서 한 번의 모델 학습 과정에서 사용되는 데이터의 묶음
- 데이터셋이 매우 큰 경우 모든 데이터를 한 번에 모델에 입력하고 학습시키는 것은 컴퓨팅 자원과 메모리 측면에서 효율적이지 않을 수 있습니다.
- 이 때문에 데이터를 작은 묶음으로 나누어서 모델에 주입하는 방식이 사용됩니다. 이 작은 묶음이 바로 "배치"입니다.
배치는 보통
2의 제곱수로 설정됩니다. 예를 들어, 32개의 데이터, 64개의 데이터, 128개의 데이터 등이 배치 크기로 많이 사용됩니다.
배치 크기가 클수록 데이터 처리 속도는 빨라질 수 있지만, 더 많은 메모리를 필요로 하며, 학습의 안정성이나 일반화 성능에도 영향을 줄 수 있습니다.
- 배치 학습(batch learning)은 모델이 한 번의 학습 과정에서 배치 단위로 입력 데이터를 처리하고 가중치를 업데이트하는 방식입니다.
- 전체 데이터셋을 모두 사용하여 한 번에 가중치를 업데이트하는 방식인 "배치 학습"과 달리, 배치별로 가중치를 업데이트하는 "
미니 배치 학습(mini-batch learning)"과 "온라인 학습(online learning)"도 있습니다.
배치 학습은 학습 속도와 안정성 측면에서 장점을 가지고 있으나
메모리 사용량과 계산 복잡도 측면에서 한계가 있을 수 있습니다.
반면에 미니 배치 학습은 일부 데이터만 사용하므로 메모리 사용량을 줄일 수 있고,
확률적 경사 하강법(SGD, Stochastic Gradient Descent)의 변형으로 볼 수 있어서
노이즈가 포함된 경사 하강법을 사용하게 됩니다.활성화 함수
- 입력을 비선형 출력으로 변환해주는 함수
- 선형관계를 나타내는 함수에 비선형성을 추가하는 방법으로 표현
- 비선형성을 추가하지 않고 선형함수로만 층을 구성한다면, 모델을 깊게 구성하더라도 결국은 선형함수로 표현
시그모이드(Sigmoid), 하이퍼볼릭 탄젠트(Hyperbolic Tangent 혹은 tanh), ReLU(Rectified Unit), Leaky ReLU 등
활성화 함수(Activation Function)는 인공 신경망에서 각 뉴런의 출력을 결정하는 함수입니다.
신경망은 입력 데이터를 여러 개의 뉴런을 통해 처리하고, 각 뉴런의 출력은 활성화 함수를 거쳐서 다음 뉴런으로 전달됩니다.
활성화 함수는 입력값을 받아서 어떤 규칙 또는 패턴에 따라 출력값을 생성하며,
이를 통해 신경망이 복잡한 함수를 모델링할 수 있습니다.
간단히 말해, 활성화 함수는 뉴런이 활성화되거나 활성화되지 않도록 결정하는 역할을 합니다.
이를 조합하여 신경망은 비선형성을 표현하고 다양한 문제를 해결할 수 있습니다.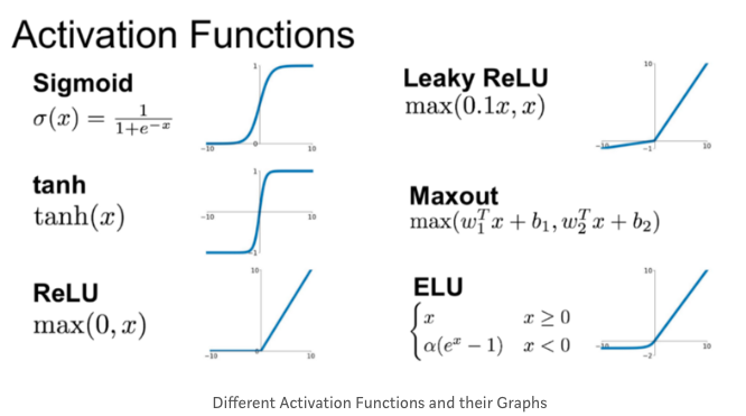
1. 시그모이드(Sigmoid) 함수
- 입력값을
0과 1사이로 압축합니다.
주로 이진 분류 문제에서 출력값으로 활용될 수 있습니다.
그래프는 S 자 형태로, 입력값이 커질수록 출력이 포화(saturation)되는 특성을 가집니다.
2. 렐루(Rectified Linear Unit, ReLU) 함수
- 입력값이 0보다 작을 경우 0으로 출력하고,
양수인 경우 그대로출력합니다.
주로은닉층에서 사용되며, 특히 딥러닝에서 인기 있는 활성화 함수입니다.
계산이 간단하고 경사 소실 문제를 완화할 수 있습니다.
3. 하이퍼볼릭 탄젠트(Tanh) 함수
- 입력값을
-1과 1 사이로 압축합니다.
시그모이드 함수와 유사하지만, 출력 범위가 -1부터 1로 확장된 점이 다릅니다.
입력값이 0 주변에서 더 민감하게 반응하는 특성이 있습니다.
4. 소프트맥스(Softmax) 함수
- 다중 클래스 분류 문제에서 주로 사용됩니다.
입력값을 클래스별 확률 분포로 변환하여, 가장 확률이 높은 클래스를 선택하게 합니다.
각 클래스의 출력값은 0과 1 사이이며, 전체 클래스의 합은 1이 됩니다.
손실함수
| 마지막 출력층 | Loss |
|---|---|
| Dense(1, activation='sigmoid') | loss='binary_crossentropy' |
| Dense(1, activation='softmax') | loss='categorical_crossentropy' loss='sparse_categorical_crossentropy' |
원 핫 벡터
- 원핫 벡터(One-Hot Vector)는 범주형 데이터를 컴퓨터가 처리하기 쉽도록 숫자로 표현하는 방법 중 하나입니다.
이해하기 쉽게 설명하면, 원핫 벡터는 특정한 값을 나타내는 위치에 1이고, 나머지 위치에는 모두 0인 벡터입니다.
예를 들어, 과일 종류를 나타내는 범주형 데이터가 있다고 가정해봅시다. 다음과 같이 여러 가지 과일이 있다고 합시다:
사과
바나나
오렌지
이러한 과일들을 원핫 벡터로 표현하려면 각각의 과일을 벡터로 변환하는데, 이때 각 과일을 고유한 인덱스로 대응시킵니다.
- 예를 들어,
사과는 0번인덱스,바나나는 1번인덱스,오렌지는 2번인덱스로 대응시킬 수 있습니다.
그러면 각 과일의 원핫 벡터는 다음과 같이 표현됩니다:
사과: [1, 0, 0]
바나나: [0, 1, 0]
오렌지: [0, 0, 1]
- 이렇게 하면 컴퓨터는 숫자로 표현된 벡터를 이용해 과일 데이터를 처리할 수 있게 되며, 머신러닝 모델에 입력으로 활용할 수 있습니다.
- 원핫 벡터는 범주형 데이터를 효과적으로 숫자로 변환하는 방법 중 하나로, 분류 문제나 텍스트 처리에서 자주 사용됩니다.
옵티마이저(optimizer)
- 손실을 낮추기 위해, 신경망의 가중치와 학습률과 같은 신경망의 속성을 변경하는 데 사용되는 최적화 방법
케라스에서 지원하는 옵티마이저 목록
- SGD, Adam, Adagrad, Nadam, RMSprop, Adadelta, Adamax, Ftrl
# 클래스 인스턴스로 지정
adam = tf.keras.optimizers.Adam(👉learning_rate=0.001) ------lr 로 더이상 표기x
model.compile(optimizer=adam)
# 문자열로 지정
model.compile(optimizer='adam')평가지표
- 모델을 훈련할 때, 모델이 얼마나 잘 작동하는지를 평가하고자 할 때 사용하는 지표
이러한 평가 지표들은 모델을 컴파일하는 단계에서 지정되며, 모델이 최적화되도록 도와줍니다.
1. 손실 함수 (Loss Function)
- 손실 함수는 모델의 예측값과 실제 정답(label) 사이의 차이를 측정합니다.
모델이 예측을 얼마나 잘 했는지에 대한 척도로 사용됩니다. - 손실 함수의 값이 작을수록 모델이 정확하게 예측했다고 할 수 있습니다.
훈련 과정에서 모델의 가중치(weight)를 업데이트하는데 사용됩니다.
2. 정확도 (Accuracy)
- 정확도는 전체 데이터 중에서
모델이 올바르게 예측한 데이터의 비율을 나타냅니다.
간단한 평가 지표로 많이 사용되며, 예측이 얼마나 정확한지를 보여줍니다.
하지만 클래스의 불균형이 있는 경우에는 조심해야 할 수 있습니다.
3. 정밀도 (Precision)와 재현율 (Recall):
- 정밀도는 모델이 양성으로 예측한 샘플 중에서 실제 양성인 비율을 나타냅니다.
재현율은 실제 양성인 샘플 중에서 모델이 양성으로 예측한 비율을 나타냅니다.
이 두 지표는 주로 이진 분류에서 사용되며, 서로의 균형을 맞추는 것이 중요합니다.
4. F1 스코어 (F1 Score)
- F1 스코어는 정밀도와 재현율의 조화 평균으로 계산됩니다.
양성 클래스에 불균형이 있는 경우에 유용하며, 정확도보다 더 신뢰성 있는 지표일 수 있습니다.
5. 평균 절대 오차 (Mean Absolute Error, MAE)
- 회귀 문제에서 사용되는 지표로, 예측값과 실제 값 사이의 평균 절대 차이를 측정합니다.
작을수록 모델의 예측이 정확하다고 할 수 있습니다.

회귀문제가 뭐야?
회귀 문제(Regression Problem)는 머신 러닝이나 통계 분야에서 다루는 문제 유형 중 하나입니다.
회귀 문제는 입력 변수(input features)와 연속적인 출력 변수(target variable) 간의 관계를 모델링하고, 주어진 입력에 대해 연속적인 값을 예측하는 것을 목표로 합니다.
- 간단하게 말하면, 어떤 입력 데이터가 주어졌을 때, 해당 입력에 대한 연속적인 출력 값을 예측하는 문제입니다.
- 여기서 "연속적인 출력 값"은 실수로 표현되는 숫자로, 예를 들어 가격, 온도, 시간 등이 될 수 있습니다.
- 예를 들어, 아파트의 크기, 방의 개수, 위치 등의 특성을 가지고 해당 아파트의 가격을 예측하는 문제가 회귀 문제의 하나입니다. 다른 예로는 날씨 데이터를 이용하여 내일의 최고 기온을 예측하거나, 광고 비용과 판매량의 관계를 분석하여 향후 판매량을 예측하는 것도 회귀 문제에 해당합니다.
회귀 모델은 주어진 입력 데이터와 출력 값의 관계를 학습하여 새로운 입력에 대한 출력 값을 예측하는 방법을 찾습니다.
- 주어진 데이터를 이용하여 모델을 훈련하고, 이 모델을 이용하여 미래의 값을 예측하는 것이 회귀 문제의 핵심입니다.
6. 평균 제곱 오차 (Mean Squared Error, MSE)
- 또 다른 회귀 문제에서 사용되는 지표로, 예측값과 실제 값 사이의 평균 제곱 차이를 측정합니다.
MSE가 MAE보다 오차의 크기에 더 민감하게 반응합니다.
콜백
- 모델을 훈련할 때 보조적인 작업을 수행할 수 있도록 도와주는 객체.
fit()메소드에 callbacks 매개변수로 지정할 수 있다.
모델 체크포인트
- 모델 훈련 시 콜백으로 지정, epoch별 모델의 가중치를 저장
- 체크포인트를 생성하듯 미리 정해 놓은 규칙에 의하여 체크포인트를 생성, 저장
# 체크포인트 설정
checkpoint = tf.keras.callbacks.ModelCheckpoint(filepath='tmp_checkpoint.ckpt', # 체크포인트의 저장 경로 지정
save_weights_only=True, # 가중치만 저장할지 여부 설정
save_best_only=True, #monitor 기준으로 가장 높은 epoch만 저장할지 아니면 매 epoch별 저장할지 여부를 설정
monitor='val_loss', #monitor: 저장 시 기준이 되는 지표 설정. val_loss로 지정 시 검증 손실이 갖아 낮은 epoch의 가중치를 저장
verbose=1) #1로 설정 시 매epoch별 저장 여부를 알려주는 로그 메시지 출력모델 체크포인트(Model Checkpoint)는
딥러닝 모델을 훈련하는 동안 주기적으로 모델의 상태를 저장하는 기능을 말합니다.
- 이렇게 저장된 체크포인트는 나중에 모델을 재사용하거나 이어서 학습을 진행할 때 유용하게 활용됩니다. 이해를 돕기 위해 아래와 같은 비유를 생각해볼 수 있습니다.
-
체크포인트는 여행을 할 때 미리 지점을 찍어두는 것과 비슷합니다. 여행 중에 언제든지 체크포인트에서 다시 시작할 수 있으며, 만약 어떤 이유로 중간에 길을 잃어버렸다면 그 전의 체크포인트에서 다시 시작할 수 있습니다.
-
딥러닝에서도 이와 비슷한 원리로, 모델 체크포인트는 모델의 중간 상태를 주기적으로 저장합니다. 이는 모델이 훈련 도중에 중단되거나 문제가 발생했을 때 이전의 상태로 돌아가거나, 모델의 성능을 추적하거나, 학습이 멈췄을 때 학습을 재개하는 데 유용합니다.
-
예를 들어, 딥러닝 모델을 훈련하는 도중 특정 에포크(epoch)에서 모델의 정확도가 높아졌다면, 해당 시점에서 모델 체크포인트를 저장하여 나중에 이 모델을 사용할 수 있습니다.
- 또한, 매 에포크마다 모델 체크포인트를 저장하여 학습이 중단되더라도 가장 최근의 상태로 학습을 이어나갈 수 있습니다.
딥러닝 모델 체크포인트는 모델의 가중치(weight), 최적화 상태, 학습 기록 등을 저장하는데 사용됩니다. 이를 통해 모델을 효율적으로 관리하고 활용할 수 있습니다.
텐서보드
훈련에 대한 시각화를 실시간으로 제공하는 유용한 도구이다.
텐서보드를 활용하면, epoch별 훈련 손실 및 평가 지표를 시각화해 차트로 보여주거나 모델의 구조를 시각화해 보여주거나, 레이어의 가중치 분포도를 시각화로 제공한다.
- 모델 훈련시 시각화 차트를 실시간으로 업데이트해 제공하는 기능도 포함한다.
# 텐서보드 extension 로드
%load_ext tensorboard
# 텐서보드 출력 매직 커멘드
%tensorboard --logdir {log_dir}%load_ext tensorboard
- 이 명령어는 텐서보드 확장(extension)을 로드하는 명령어입니다. 텐서보드를 사용하기 위한 환경을 설정합니다.
%tensorboard --logdir {log_dir}
- 이 명령어는 텐서보드를 실행하여 로그 디렉터리(log directory)에 저장된 학습 로그를 시각화하는 역할을 합니다.
- {log_dir}은 로그 디렉터리의 경로를 나타내며, 실제 경로로 대체되어 실행됩니다.
이 명령어를 실행하면 텐서보드가 웹 브라우저에서 열리고, 학습 과정의 그래프, 메트릭, 히스토그램 등을 확인할 수 있습니다.
텐서플로 데이터셋
- 별도의 라이브러리를 제공함으로써 훈련에 필요한 다양한 데이터셋을 쉽게 얻을 수 있다.
- 텐서플로와는 별도로 구분된 라이브러리이다.
pip install tensorflow-datasets
- 구글 코랩(colab)에서는 사전에 설치되어 있어 별도의 설치가 필요 없다.