[혼공머신:1주차] Chapter01 나의 첫 머신러닝

맨 하단에 코랩 캡쳐본 인증합니다.
- 😻 코랩 공유링크
01-1 인공지능과 머신러닝, 딥러닝
1) 인공지능
인공지능 (artificial intelligence)
- 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
일반인공지능/강인공지능
- 영화
그녀의 사만다나,터미네이터의 스카이넷처럼 사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템
약인공지능
- 특정 분야에서 사람의 일을 도와주는 보조 역할만 가능
- ex) 음성 비서, 자율 주행 자동차, 음악 추천, 기계 번역 등
2) 머신러닝
머신러닝 (machine learning)
- 규칙을 일일이 프로그래밍하지 않아도, 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 인공지능 하위 분야 중 지능을 구현하기 위한 소프트웨어를 담당하는 핵심 분야
- 통계학과 깊은 관련
- 통계학에서 유래된 머신러닝 알고리즘 多 + 컴퓨터 과학 분야 상호작용
- 오픈소스 통계 소프트웨어 R
- 최근 머신러닝 발전 : 통계, 수학 이론 < 경험
- 컴퓨터 과학 분야 대표적인 머신러닝 라이브러리 :
사이킷런(scikit-learn)🦾
3) 딥러닝
딥러닝(deep learning)
인공신경망을 기반으로 한 방법들을 통칭- 인공 신경망과 딥러닝을 크게 구분하지 않고 사용
-
2016년 국내 : 이세돌과 알파고의 대국
- LeNet-5(손글씨 숫자인식) 및 AlexNet(이미지 분류)보다 더 놀라운 성능을 갖게 된 이유
- ① 복잡한 알고리즘을 훈련할 수 있는 풍부한 데이터
- ② 컴퓨터 성능 향상
- ③ 혁신적인 알고리즘 개발
- LeNet-5(손글씨 숫자인식) 및 AlexNet(이미지 분류)보다 더 놀라운 성능을 갖게 된 이유
-
최근 딥러닝 발전은
매우 긍정적이다!😊 -
2015 구글: 텐서플로(TensorFlow) 오픈소스 공개
-
2018 페이스북: 파이토치(PyTorch) 딥러닝 라이브러리
공통점
- 인공 신경망 알고리즘을 전문으로 다루고 있다는 점
- 사용하기 쉬운 파이썬 API를 제공
01-1 정리
| 키워드 | 설명 |
|---|---|
| 인공지능 | 사람처럼 학습하고 추론할 수 있는 지능을 가진 시스템을 만드는 기술 |
| 머신러닝 | 규칙을 프로그래밍하지 않아도, 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야 |
| 딥러닝 | 인공 신경망이라고도 하며, 텐서플로와 파이토치가 대표적인 라이브러리 |
01-2 코랩과 주피터 노트북
구글 코랩(Colab)
- 웹 브라우저에서 무료로 파이썬 프로그램을 테스트 및 저장할 수 있는 서비스
- 머신러닝 프로그램도 제작 가능
- 클라우드 기반의 주피터 노트북 개발 환경 =
웹 브라우저에서 텍스트 및 프로그램 코드를 자유롭게 작성할 수 있는 온라인 에디터 노트북/코랩 노트북: 코랩 파일
- 셀: 코랩에서 실행할 수 있는 최소 단위
- 텍스트 셀: html 및 마크다운을 혼용해서 사용 가능.
- 코드 셀
노트북
- 대화식 프로그래밍 환경인
주피터커스터마이징 - 주피터 프로젝트 대표 제품 : 주피터 노트북 (Jupyter Notebook)
새 노트북 만들기
- 불러오기도 가능하다.
01-3 마켓과 머신러닝
한빛마켓🐟🐠🐡
- 앱 마켓 최초로 살아있는 생선 판매하기 시작
- 고객이 온라인으로 주문하면 가장 빠른 물류 센터에서 신선한 생선을 곧바로 배송
- 근데, 직원이 생선 이름을 못외움
-> 생선 이름을 자동으로 알려주는 머신러닝 만들어줘!
생선 분류 문제
- 도미 / 곤들매기 / 농어 / 강꼬치고기 /로치 / 빙어 / 송어
- 머신러닝은 스스로 기준을 찾아서 일을 수행한다. -> 그 기준을 이용해 생선이 도미인지 아닌지도 판별 가능
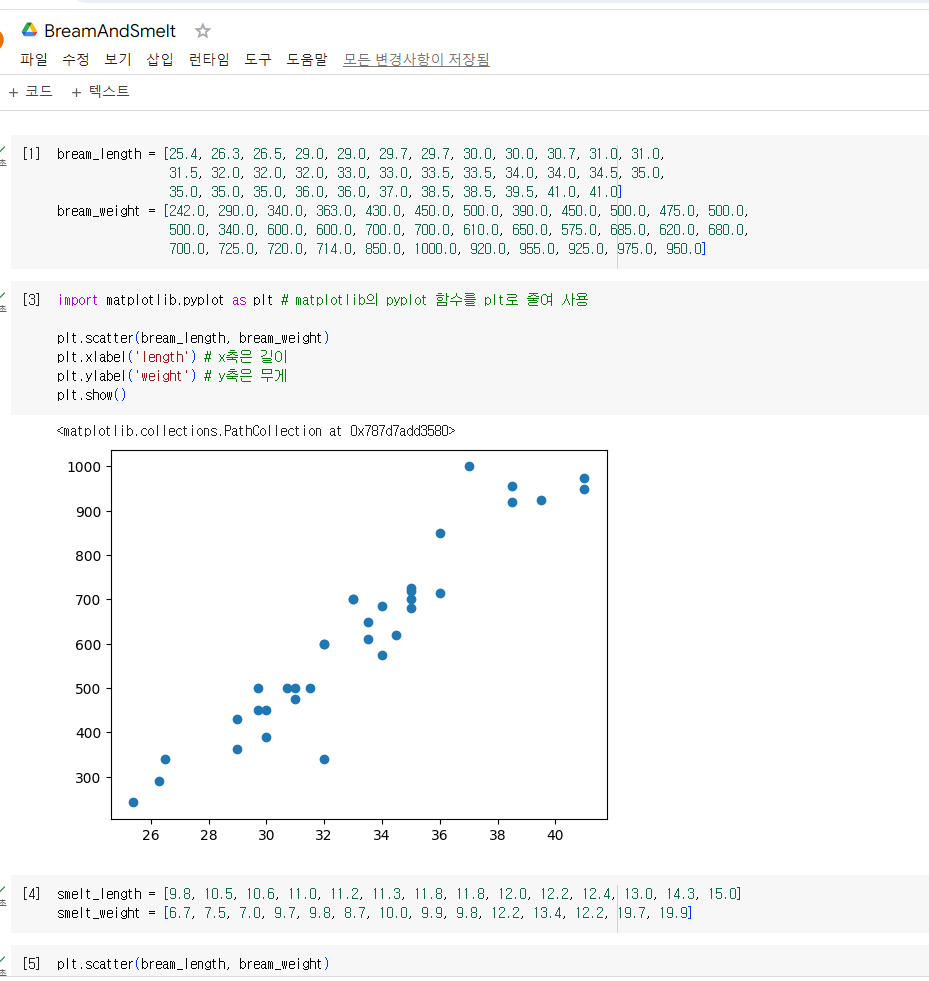
도미 데이터 준비하기
👉손코딩
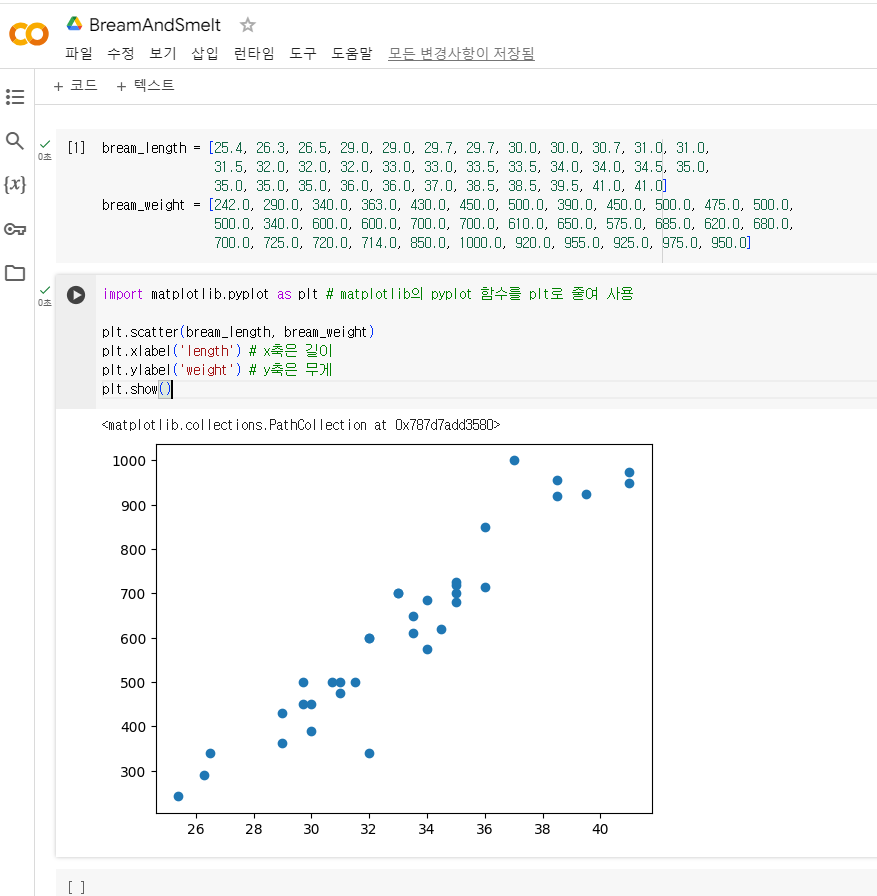
bream_length(생선의 길이) = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight(생선의 무게) = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
- 각 도미의 특징을 길이와 무게로 표현 -> 특성
- 산점도 : 그래프를 점으로 표시 (x, y축으로 이뤄진 좌표계에 두 변수(x, y)의 관계를 표현하는 방법)
- 산점도 그래프가 일직선에 가까운 형태로 나타나는 경우:
선형👨
- 산점도 그래프가 일직선에 가까운 형태로 나타나는 경우:
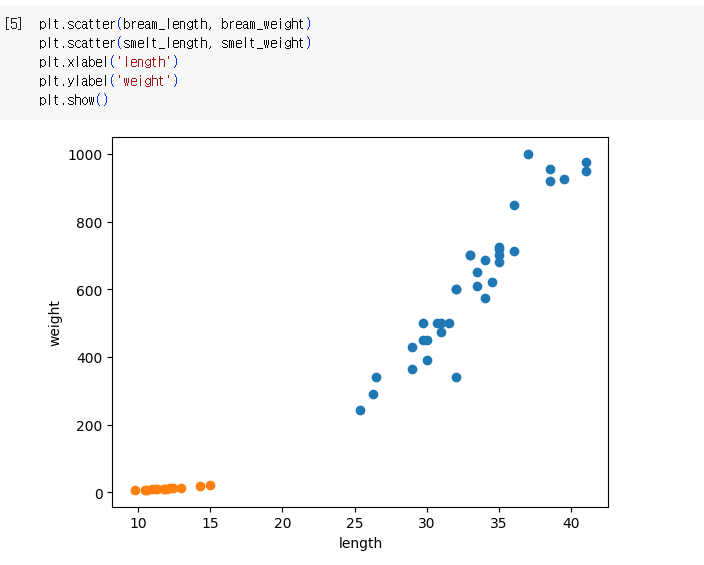
빙어 데이터 준비하기
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
첫 번째 머신러닝 프로그램
k-최근접 이웃(k-Nearest Neightbors) 알고리즘
- 도미와 빙어 데이터를 하나로 합침
length = bream_length + smelt_length
weight = bream_weight + smelt_weight

- 생선의 길이와 무게를 보고 도미와 빙어를 구분하기를 원함. -> 어떤 생선이 도미이고 빙어인지를 알려주어야 한다.
- 도미는 1, 빙어는 0이라고 가정
- 찾으려는 대상을 1로 놓고, 그 외에는 0으로 놓는다.
KNeighborsClassifier를 import
훈련: 모델에 데이터를 전달하여 규칙을 학습하는 과정
k-최근접 이웃 알고리즘
- 어떤 데이터에 대한 답을 구할 때, 주위의 다른 데이터를 보고 다수를 차지하는 것을 정합으로 사용한다.
- 주위의 데이터로 현재 데이터를 판단하는 것
😻 전체 코드 링크
01-3 정리
-
특성: 데이터를 표현하는 하나의 성질 -
훈련: 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정 -
모델: 알고리즘이 구현된 객체 -
k-최근접 이웃 알고리즘: 전체 데이터를 메모리에 갖고 있음, 가장 간단한 머신러닝 알고리즘 중 하나. -
정확도: 정확한 답을 몇 개 맞혔는지를 백분율로 나타낸 값.- 사이킷런: 0~1 사이의 값
- 정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)
-
scikit-learn
- KNeighborsClassifier()는 k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스, 이웃의 개수는 기본값 5이다.
- fit() : 사이킷런 모델 훈련 시 사용, 특성과 정답 데이터를 전달
- predict() : 사이킷런 모델을 훈련, 예측시 사용하는 메서드
- score() : 훈련된 사이킷런 모델의 성능을 측정한다.
Chapter02 데이터 다루기: 수상한 생선을 조심하라!
02-1 훈련 세트와 테스트 세트
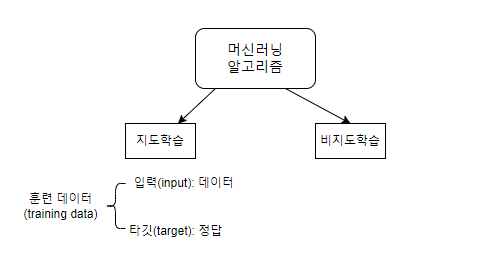
지도학습과 비지도 학습
- KNeighborsClassifier()는 k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스, 이웃의 개수는 기본값 5이다.
-
입력: 생선의 길이와 무게
-
정답: 도미인지 아닌지 여부
-
특성: 입력으로 사용된 길이와 무게
비지도 학습
- 타깃 없이 입력 데이터만을 사용합니다. (입력 데이터만 있을 때 사용하기도 함)
- 정답을 사용하지 않으므로, 무언가를 맞힐 수 없지만,
- 데이터를 잘 파악하거나 변형하는 데 도움을 준다.
훈련 세트와 테스트 세트
- 도미와 빙어의 데이터와 타깃을 주고 훈련한 다음, 같은 데이터로 테스트한다면 모두 맞히는 것이 당연하다.
- 연습 문제와 시험 문제가 달라야 올바르게 학생의 능력 평가할 수 있듯, 훈련 데이터와 평가에 사용할 데이터가 각각 달라야 한다!
훈련에 사용한 데이터로 모델을 평가하는 것은 적절하지 않다. 🤔
링크
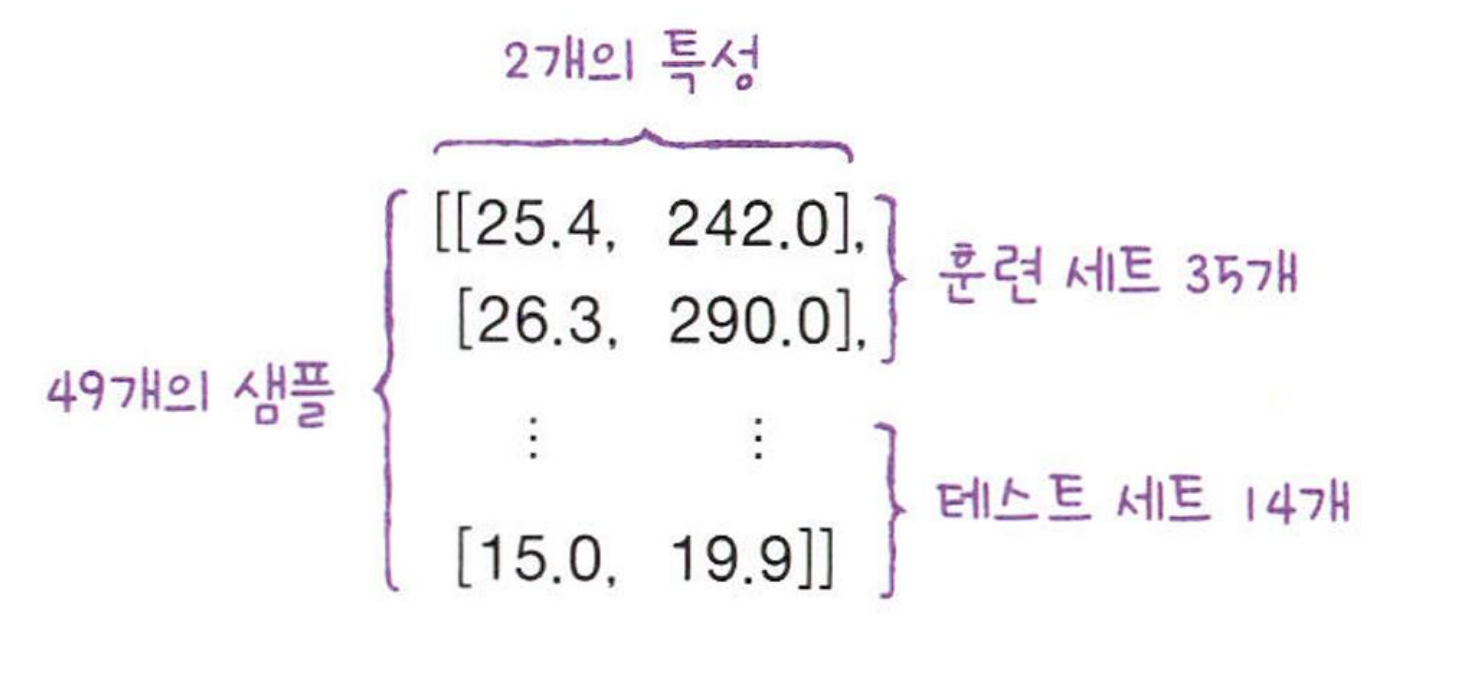
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
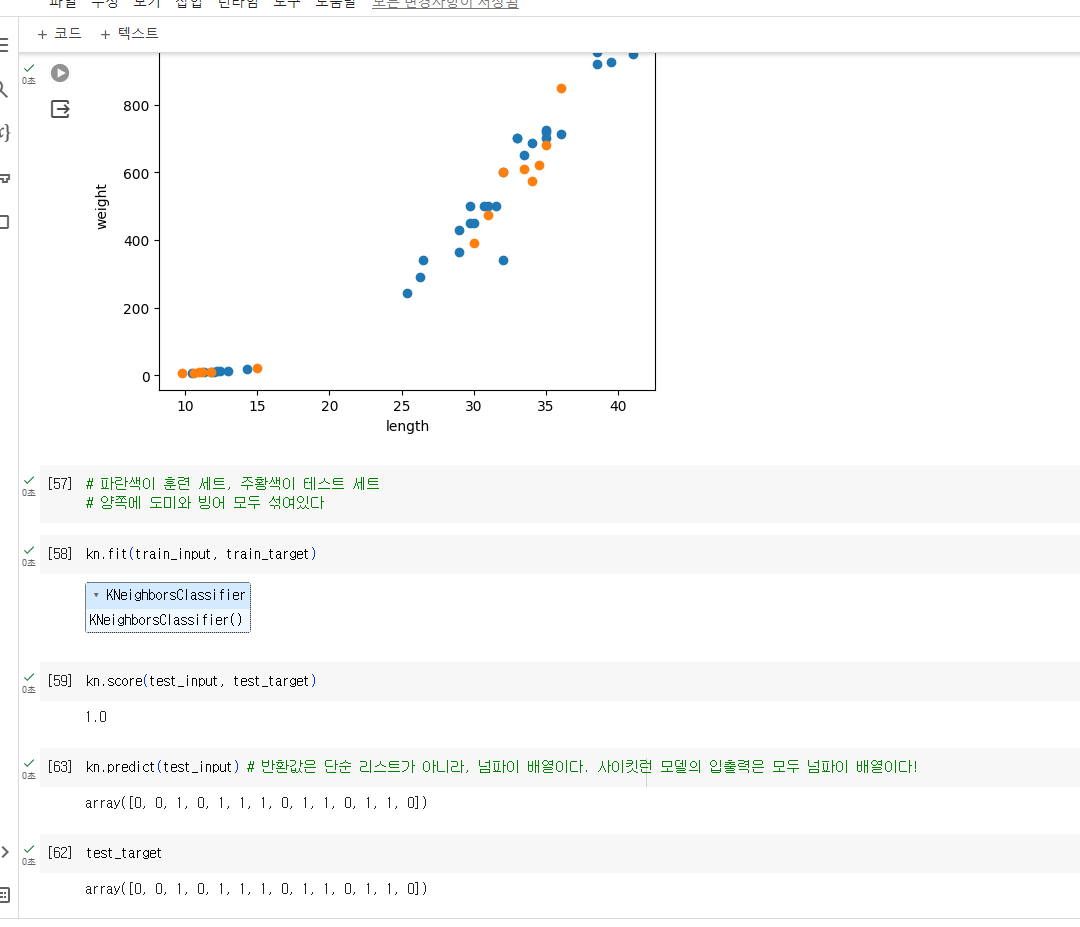
훈련하는 데이터와 테스트 데이터에는 도미와 빙어가 골고루 섞여 있어야 한다.
한 쪽으로 치우치게 되는 것은 샘플링 편향이라고 한다. (sampling bias)
훈련/테스트 세트를 나누기 전 데이터를 섞거나, 골고루 샘플을 뽑아 훈련 세트와 테스트 세트를 만들어야 한다.
넘파이
- 파이썬의 대표적인 배열 라이브러리
- 고차원의 배열을 손쉽게 만들고 조작
- 왼쪽 위에서부터 시작한다.
훈련 모델 평가(문제 해결 과정)
- 김팀장: 알고리즘이 도미와 빙어 모두 외우고 있다면, 같은 데이터로 모델 평가하는 것은 이상해!
- 훈련 데이터 -> 훈련 세트 / 테스트 세트 (모델 평가)
- 두 세트에 어느 한 생선만 들어가 있으면 올바른 학습이 되지 않을 것
- 골고루 섞기 위해 넘파이를 사용, shuffle 함수를 사용해 배열의 인덱스 섞었다.
미션 인증😍 (기본+선택)
- 기본 미션 : 코랩 실습 화면 캡쳐하기
- 선택 미션 : Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기
[확인문제]
- 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은?
답: ① 지도학습
- 비지도학습: 타깃(정답) 없이 입력 데이터만 사용한다.
- 강화학습 알고리즘: 타깃이 아닌 알고리즘이 행동한 결과로 얻은 보상을 사용해 학습한다.
- 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
답: ④ 샘플링 편향(sampling bias)
- 나머지 보기는 책에 설명되어 있지 않다.
- 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
답: ② 행: 샘플, 열: 특성