
MySQL Scan 정리
MySQL에서 인덱스를 이용한 스캔 방법은 쿼리 성능 최적화에 중요한 역할을 합니다. 인덱스는 데이터베이스에서 빠른 검색을 가능하게 해주는 데이터 구조입니다. MySQL은 다양한 방식으로 인덱스를 활용하여 쿼리를 최적화합니다. MySQL에서의 스캔 방법을 정리해보았습니다.
employees라는 데이터를 기준으로 작성했습니다. (구글 검색을 통해 나오는 데이터를 기준으로 작성)
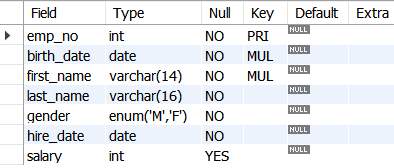
employees 테이블 구조
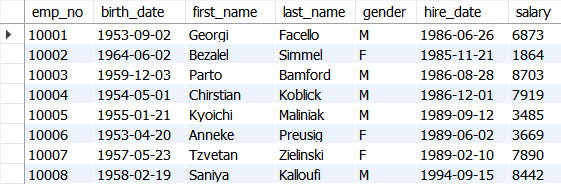
select * from employees
1. 풀 테이블 스캔 (Full Table Scan)
풀 테이블 스캔은 인덱스를 사용하지 않고 테이블의 모든 행을 검사하는 방법입니다. 인덱스가 없거나, 인덱스를 사용할 수 없는 경우에 발생합니다.
EXPLAIN SELECT * FROM employees;많은 사람들이 오해하고 있는 것 중 하나는 풀 테이블 스캔이 인덱스 스캔보다 나쁘다는 것입니다. 인덱스 스캔의 경우 주로 랜덤 I/O로 값을 읽어오게 되는데, 이때 발생하는 I/O는 디스크 헤더가 움직여야 하기 때문에 매우 느립니다. (SSD의 경우 이보다는 개선되었지만 메모리와 비교해 보았을 때에도 메모리가 SSD에 비해 수백에서 수천 배 더 빠릅니다.)
그러나 순차 I/O의 경우 값을 읽어올 때 디스크 헤더의 이동 시간이 더욱 줄어들며 값을 읽어올 때 여러 페이지의 값을 가져올 수 있기에 많은 데이터를 읽어올 때 더욱 유리한 점을 가지고 있습니다. (MySQL의 경우 리드 어헤드라는 방식을 통해 필요한 값을 미리 백그라운드 스레드를 통해 InnoDB 버퍼 풀에 가져다 놓기에 더욱 높은 성능을 보여줍니다.)
2. 풀 인덱스 스캔 (Full Index Scan)
풀 인덱스 스캔은 인덱스의 모든 값을 순차적으로 읽어오는 방식입니다.
CREATE INDEX idx_first_name ON employees(first_name);
EXPLAIN SELECT count(*) FROM employees;
type 컬럼을 보면 index로 되어 있는데 이것이 풀 인덱스 스캔을 사용했다는 것을 표현한 값입니다.
풀 인덱스 스캔으로 되어 있는 경우 쿼리를 확인해 볼 필요가 있습니다. 인덱스를 타게 되면 결국 랜덤 I/O로 값을 가져오게 되는데 이는 순차 I/O에 비해 약 4-5배 정도 느립니다. 풀 스캔 방식과 비교해보거나 다른 더 좋은 방법이 있는지 확인하면 좋습니다. (4-5배도 정확한 수치는 아니지만 보통 전체 데이터의 20-25% 정도의 데이터를 읽어야 하는 경우에는 풀 스캔 방식으로 진행되기에 4-5배라고 하였습니다.)
3. 인덱스 레인지 스캔 (Index Range Scan)
인덱스 레인지 스캔은 특정 범위의 값을 검색할 때 사용됩니다.
CREATE INDEX idx_salary ON employees(salary);
EXPLAIN SELECT * FROM employees WHERE salary BETWEEN 5000 AND 5100;급여를 기준으로 범위 스캔을 하게 됩니다.
4. 인덱스 유니크 스캔 (Index Unique Scan)
인덱스 유니크 스캔은 유니크 인덱스나 프라이머리 키를 사용하여 단일 행을 검색할 때 사용됩니다.
EXPLAIN SELECT * FROM employees WHERE emp_no = 1;emp_no가 프라이머리 키인 경우, MySQL은 인덱스 유니크 스캔을 사용하여 단일 행을 빠르게 검색합니다.
추가
유니크 제약 조건이 무조건 좋다고 하기 힘든 이유는 유니크 제약을 걸게 되면 데이터 INSERT 할 때 기존 기본 인덱스 구조에 넣는 방식에 더해 유니크한지 체크하는 과정이 한번 더 들어가기 때문에 유니크 제약 조건도 신중하게 걸어야 합니다.
5. 인덱스 스킵 스캔 (Index Skip Scan)
기존에는 선행 인덱스 컬럼을 사용하지 않으면 인덱스를 사용하지 못했지만 인덱스 스킵 스캔을 사용하게 되면 선행 컬럼이 없는 경우 후행 컬럼을 이용해서 스캔을 할 수 있습니다. 조건에 맞는 블록만 탐색하는 방식으로 조건에 맞지 않는 경우 스킵한다 해서 스킵 스캔이라고 불립니다. 보통 GROUP BY, MIN(), MAX()를 사용할 때 나타납니다.
EXPLAIN ANALYZE SELECT first_name, MIN(salary) FROM employees GROUP BY first_name;EXPLAIN값:'-> Covering index skip scan for grouping on employees using salary_index (cost=1703 rows=1263) (actual time=0.0348..3.4 rows=1275 loops=1)\n'
위 EXPLAIN 값을 보면 index skip scan for라는 구문이 있는데, 인덱스 스킵 스캔을 사용한 것을 알 수 있습니다.
참고
인덱스 스킵 스캔은 MySQL 8.0 이상에서 가능한 기능입니다.
6. 커버링 인덱스 (Covering Index)
커버링 인덱스는 쿼리가 인덱스에 포함된 컬럼만을 참조하여 테이블 행을 읽지 않고 인덱스만으로 쿼리를 해결할 수 있는 경우입니다.
EXPLAIN SELECT emp_no FROM employees WHERE emp_no=10001;
extra의 using index가 커버링 인덱스를 나타내는 문구입니다.
주의사항
- 스캔의 경우 옵티마이저가 풀 스캔이 유리하다고 생각하는 경우에는 인덱스를 타지 않습니다. (20-30%의 전체 스캔을 해야 한다고 생각하는 경우 인덱스를 타지 않습니다.)
- 만약 인덱스를 생성한 후에 예상과는 다르게 인덱스가 적용되지 않는 경우
ANALYZE TABLE employees;를 통해 테이블의 통계 정보를 최신화 시켜주시면 됩니다.
결론
MySQL에서 인덱스를 이용한 스캔 방법은 쿼리 성능 최적화의 핵심 요소입니다. 인덱스를 적절하게 사용하면 데이터베이스의 성능을 크게 향상시킬 수 있습니다. 인덱스 설정에 있어서 고려해야 할 점이 많기에 인덱스 설정은 신중하게 하셔야 합니다.
참고자료
