겜린더 백엔드 문제 인식과 문제 해결을 위한 조사에서 이어지는 글 입니다.
요약
-
Redis JSON에서 해야 했던 Indexing(색인) 작업이 사라져 성능을 개선
-
JSON 데이터가 아닌 Sorted Set 형태로 저장해 용량 문제 개선
-
캐싱 작업을 통해 MongoDB의 부하를 대폭 감소
-
Redis-Stack에 대한 의존성 낮추기...
피드백은 언제나 환영입니다. :)
개요
겜린더의 메인 DB를 Redis에서 MongoDB로 전환하면서 한 가지 문제점이 생겼습니다.
검색 기능을 어떻게 구현해야 할까?
Redis에선 편하게 ReJSON을 통해 index와 search 기능을 제공합니다.
덕분에 과거 작성한 글 중에 실제로 적용해 구현까지 완료했었죠
새로 제작 중인 겜린더 앱 일부

문제점 & 개발 방향 정하기
하지만 이번 MongoDB로 전환하는 과정에서 단순하게 쿼리 검색으로 자동완성 기능을 구현하면 큰일 날 것 같은 기분이 들었습니다.
자동완성 기능은 텍스트를 입력할 때마다 사용자에게 완성된 키워드를 줘야 했는데 In-Memory 특징 덕분에 읽기 속도가 빨랐던 Redis의 성능만 믿고 ReJSON의 기능을 이용했지만,
MongoDB는 Disk에 저장하는 방식이기 때문에 분명 성능 상 큰 문제가 발생할 것이라고 판단했습니다.
그래서 방안을 고민하던 과정을 짧게 적어볼까 합니다.
Cache Warming

Cache Warming을 통해 예상 검색어를 미리 Redis에 저장해두는 방식을 고민했는데
과거에 ReJSON을 사용하는 Redis-stack이 Ubuntu 버전(jammy)를 지원하지 않는다는 대참사를 겪어본 적이 있어서 차마 적용하기가 좀 두려웠습니다.
하지만 검색해 보니 이젠 지원하는 것 같네요.. 😂

예전엔 지원하지 않았는데... 🥺
굳이 Redis-Stack을 써야 할까..?
Cache Warming은 결국 여러 문제점으로 인해 아이디어를 폐기하고..
Redis-Stack을 사용하지 않고
Redis-Cli로 충분히 기능을 구현할 수 있지 않을까? 라는 생각을 했으나 String 형식으로는 검색 기능을 사용할 수 없었습니다.
그러다가 문득 전에 Redis를 공부하면서 Redis의 Sorted Set이라는 데이터 타입이 생각났습니다.

자동완성 시스템 구축? 어떻게 가능하지? 하면서 다시 복습을 해봤는데
ZRANGE로 구현할 수 있다는 사실을 알게 되었습니다.
ZRANGE를 사용하면 부하도 줄이고 매우 적절하게 기능을 구현할 수 있지만 기존 로직과는 약간 다르게 설계를 해야 하는 리스크가 있었지만 이건 꼭 개선해 보고 싶은 생각에 다시 설계해 보았습니다.
기존 로직과 새로운 로직의 차이점
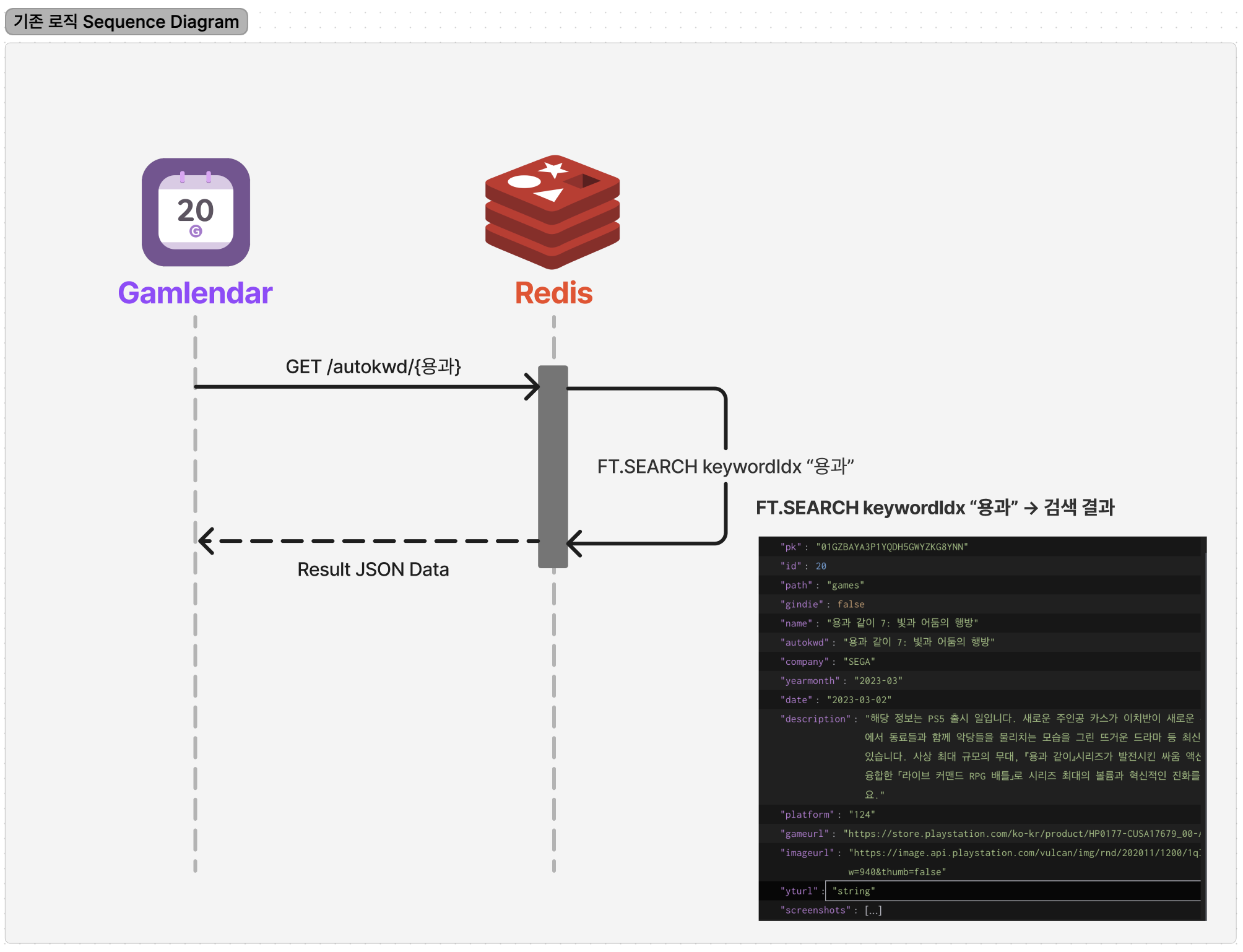
기존 설계
FT.SEARCH를 이용해 DB에 autokwd에 있는 값과 유사한 JSON 데이터 전부를 가져오는 방식
문제점
유사한 데이터를 가져오는데 데이터 일부만 가져오는 것이 아닌 모든 데이터를 가져옵니다.
덕분에 기존 검색 기능에서 이미지와 각종 데이터를 바로 불러올 수 있어 UI&UX 면에서 직관성은 매우 좋다고 생각했으나...

이렇게 하면 비용적인 측면에서 매우 좋지 못하는 것을 알게 되었죠...
가져오는 JSON 데이터가 커지면 그만큼 대역폭과 데이터 송수신 시간이 늘어나기 때문에 추후 서버 부하 문제로 고생할 것 같은 미래가 떠올랐습니다.
(라즈베리파이로 돌릴 예정이라 더욱... 성능 이슈가...)
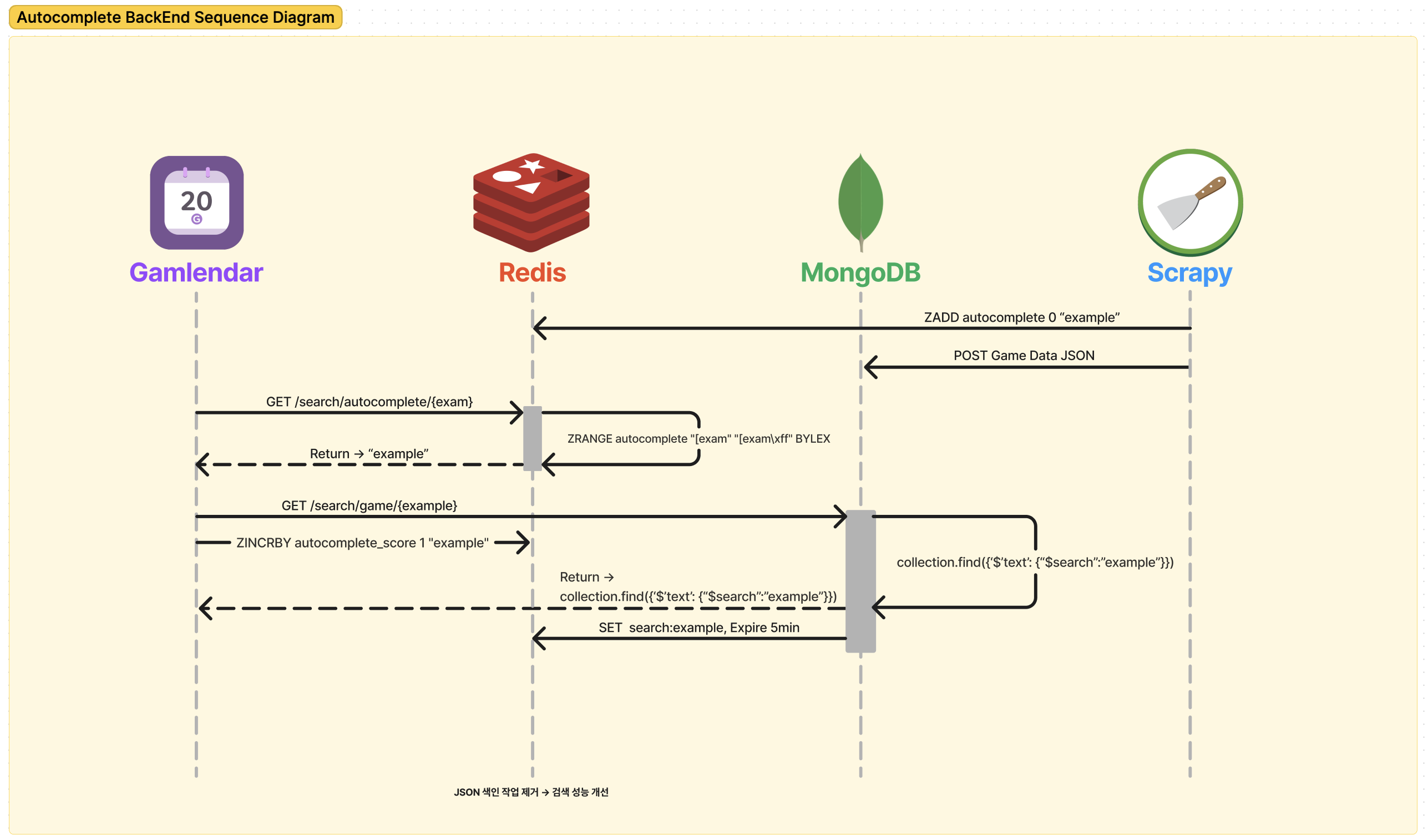
새로운 설계
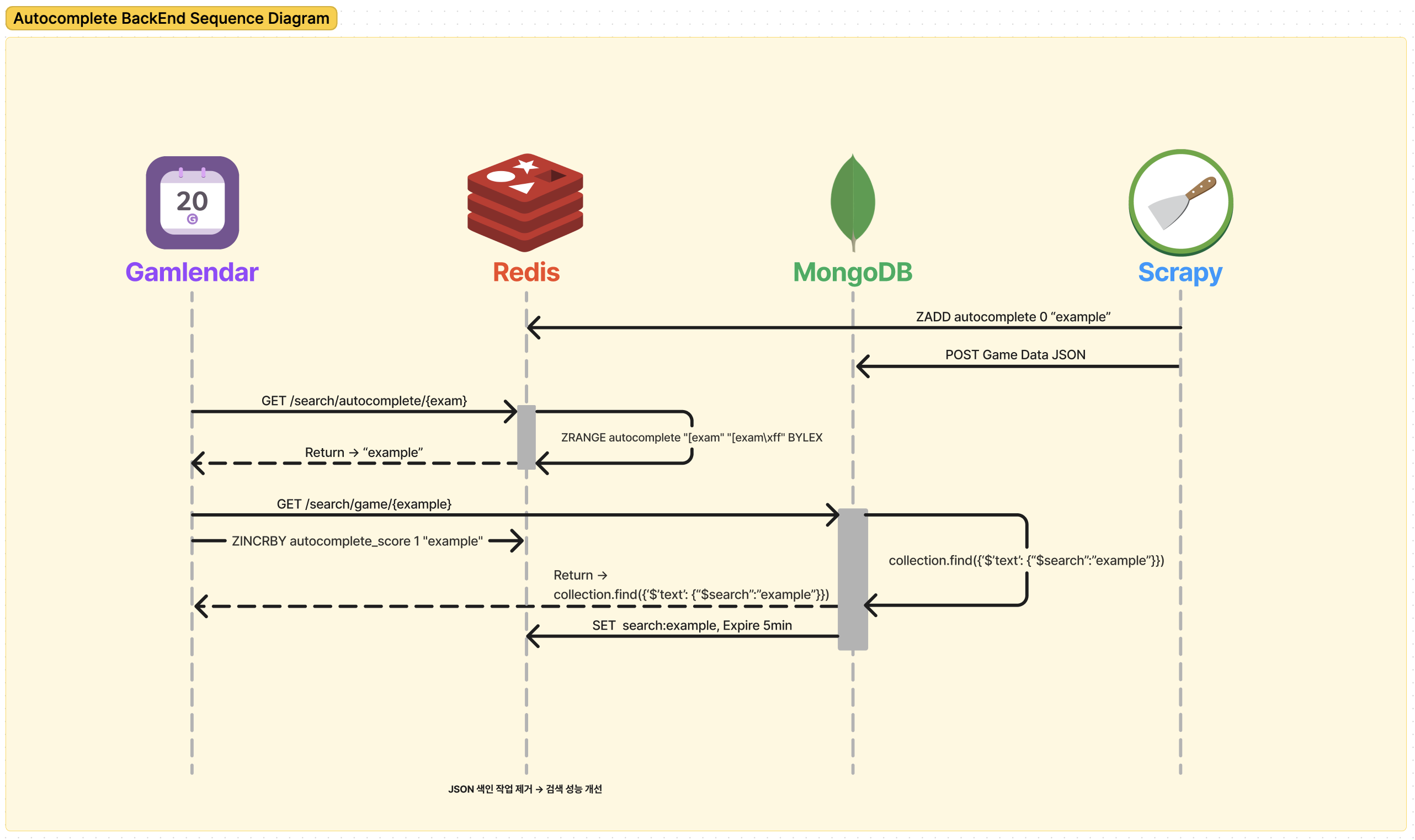
더 복잡해 보이는 건 기분 탓...이 아니다.
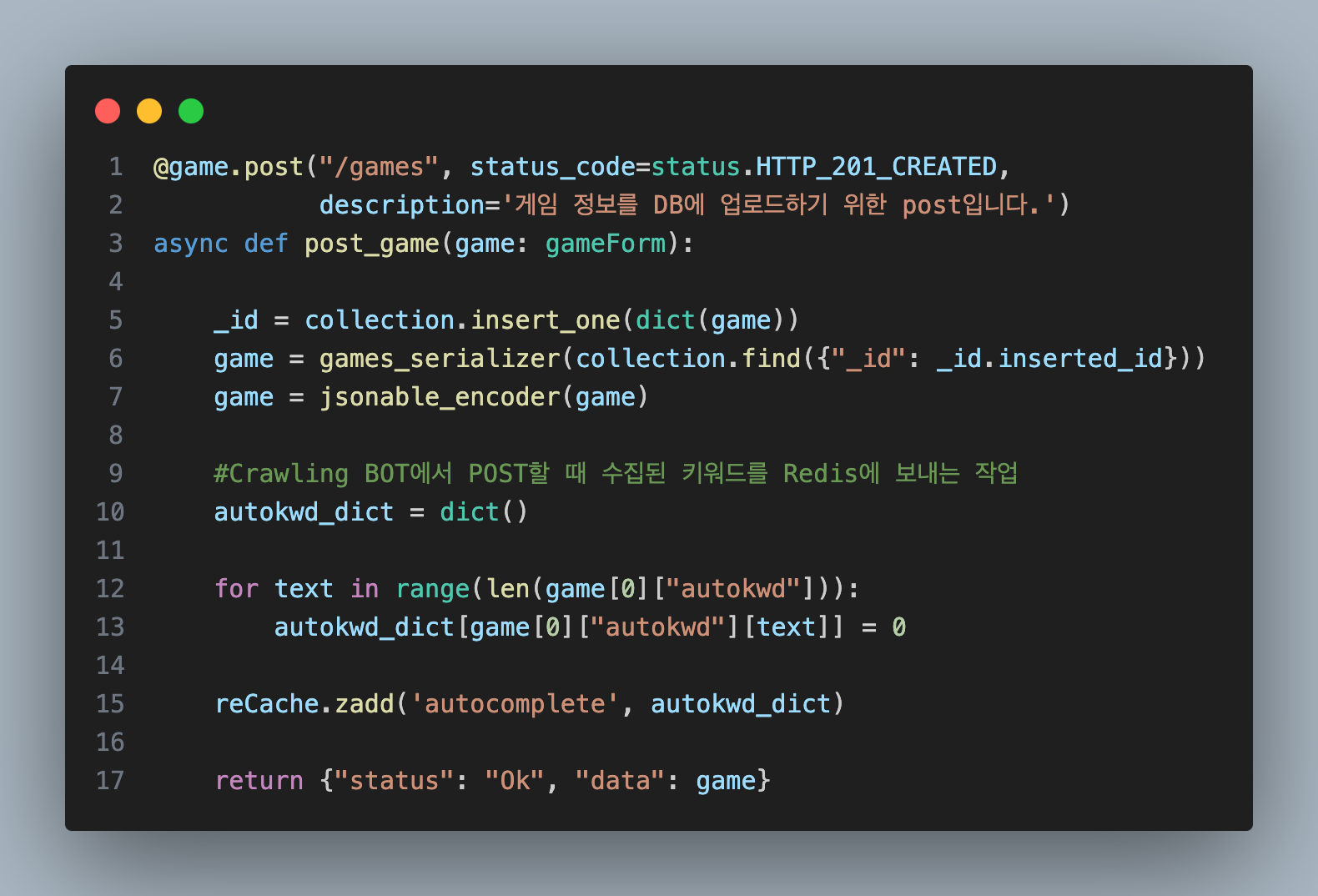
부분적으로 코드와 함께 설명을 해보자면...
MongoDB와 Redis에 데이터 저장
"example"이란 이름의 게임이 있다고 가정해 보겠습니다.
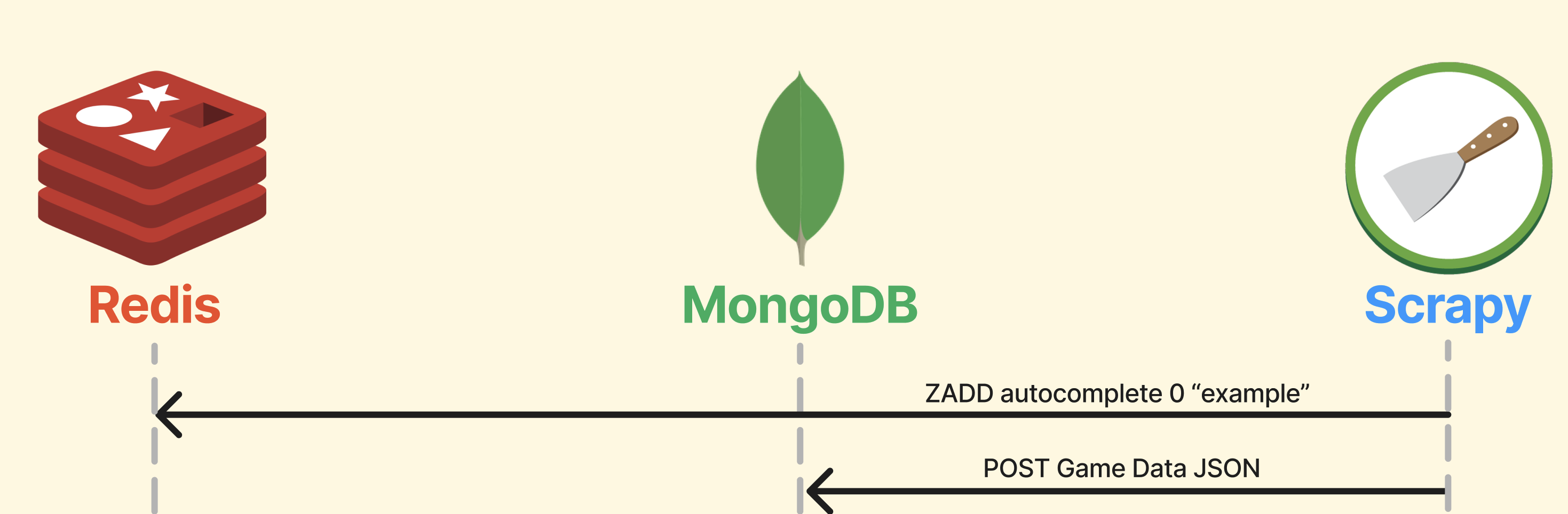 Redis에는 autocomplete라는 Sorted Set에 "example"를 추가합니다.
Redis에는 autocomplete라는 Sorted Set에 "example"를 추가합니다.
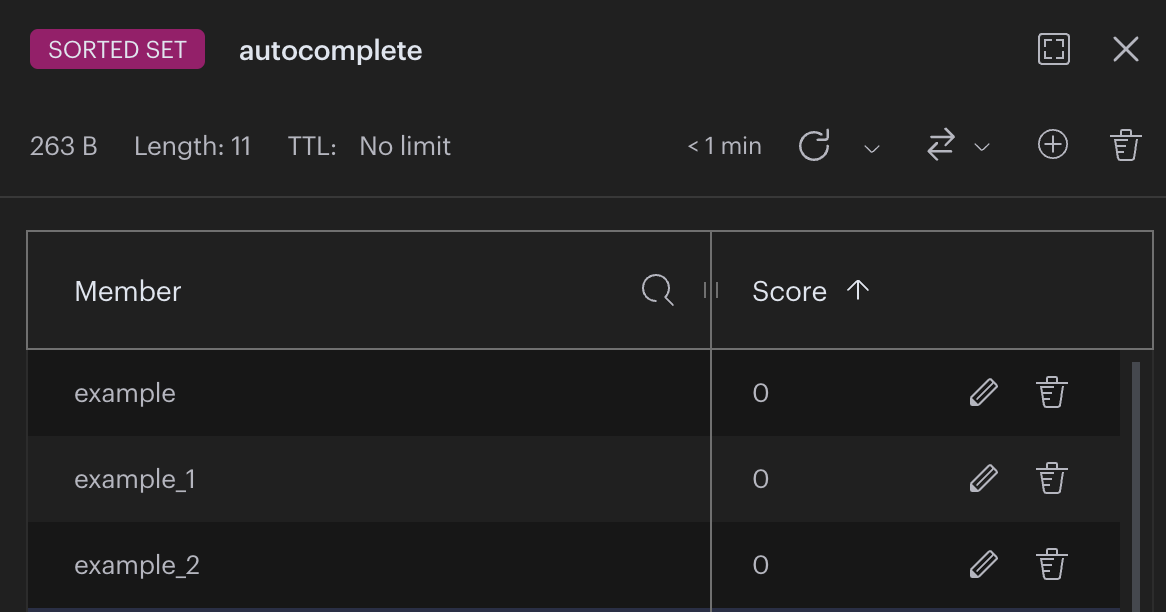 (예시로 example_1, example_2를 추가했습니다.)
(예시로 example_1, example_2를 추가했습니다.)
 MongoDB에는 수집한 게임 데이터를 저장합니다.
MongoDB에는 수집한 게임 데이터를 저장합니다.
코드 구현
자동완성 키워드 불러오기
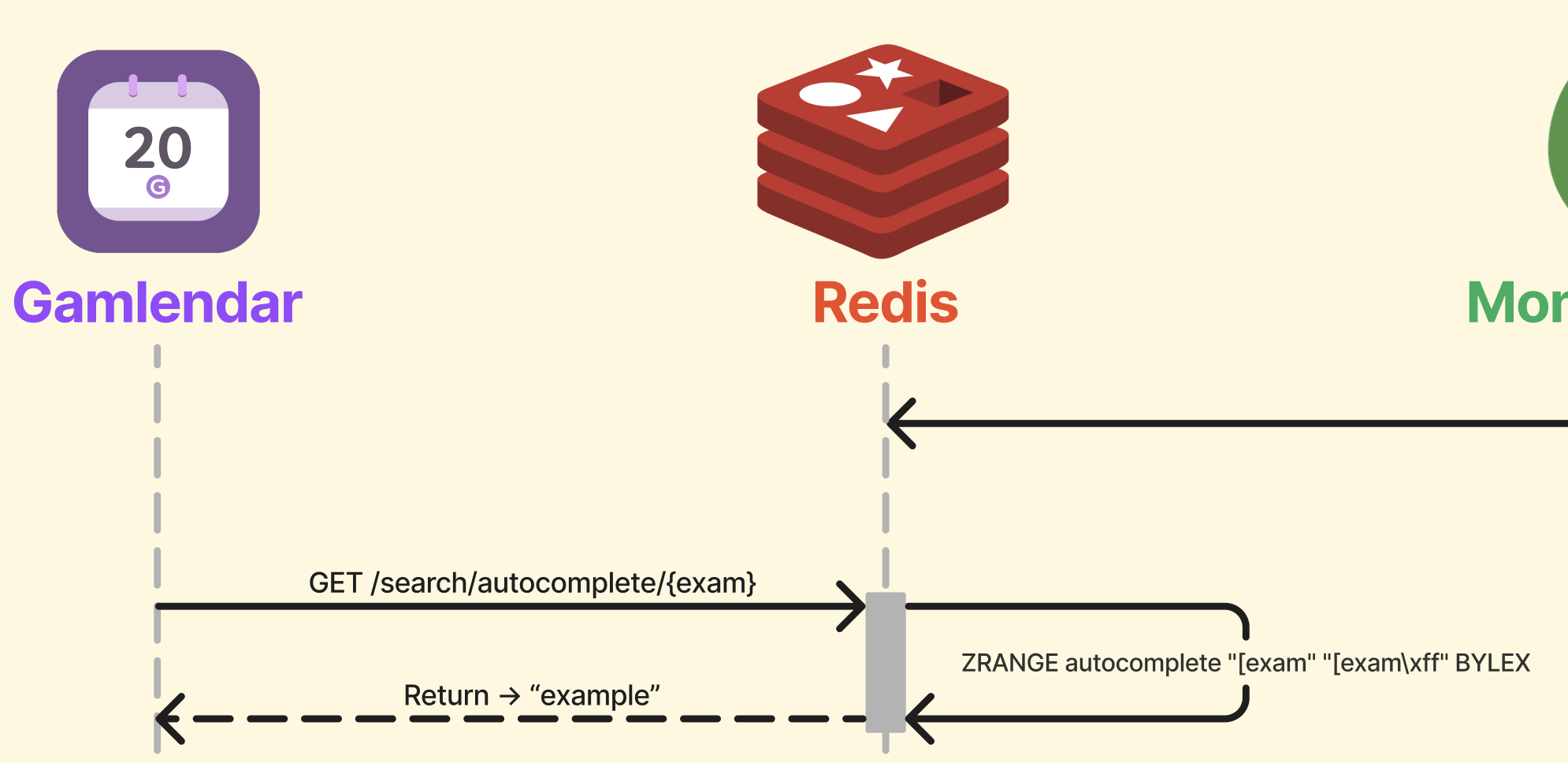
사용자는 겜린더에 "exam"이라는 텍스트만 입력했을 때를 가정하고
ZRANGE를 통해 "exam"이 포함된 텍스트를 찾게 됩니다.
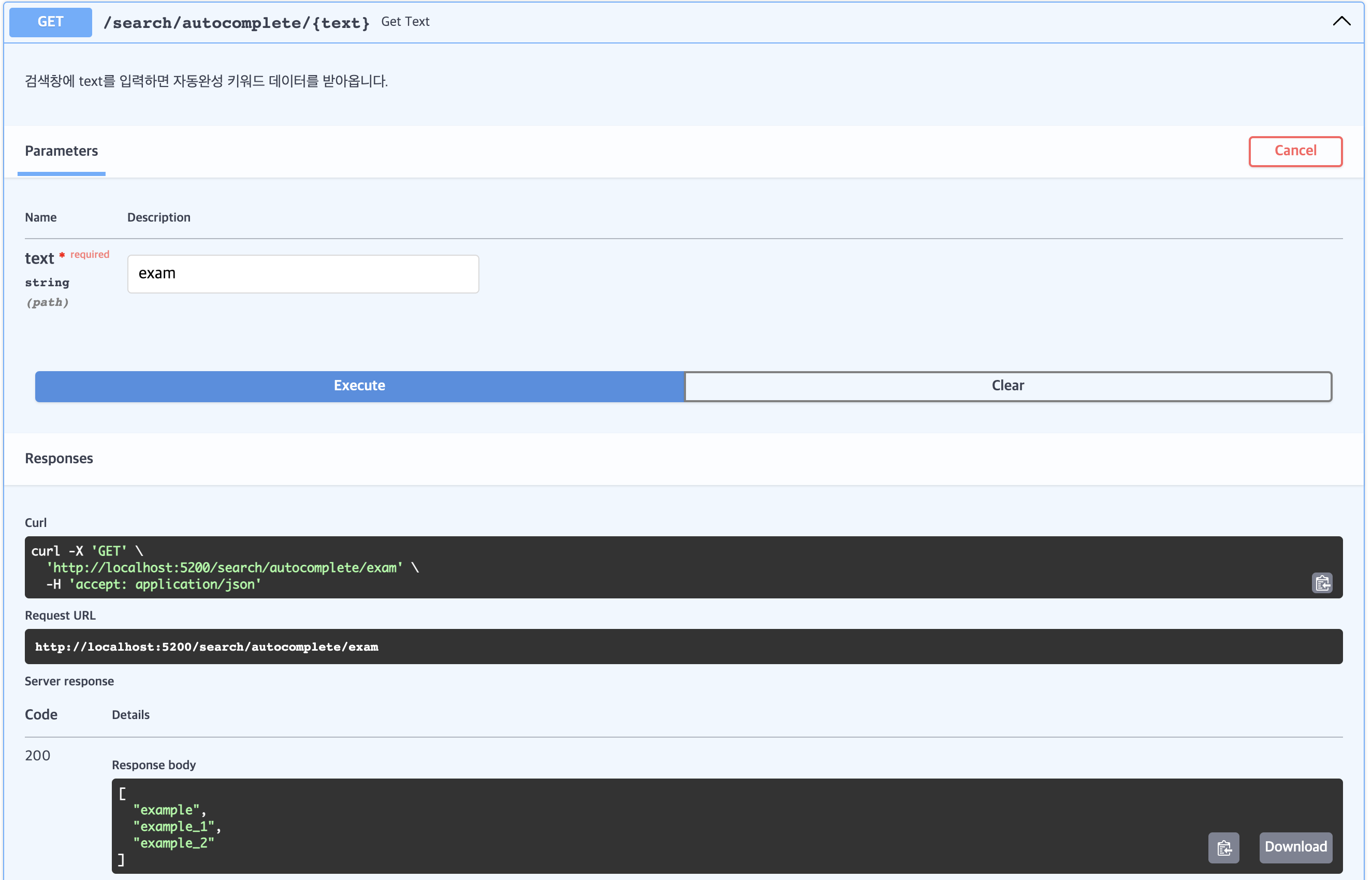
이미지 하단에 Response body을 보면 전에 추가한 example, example_1, example_2까지 전부 나오게 됩니다.
코드 구현
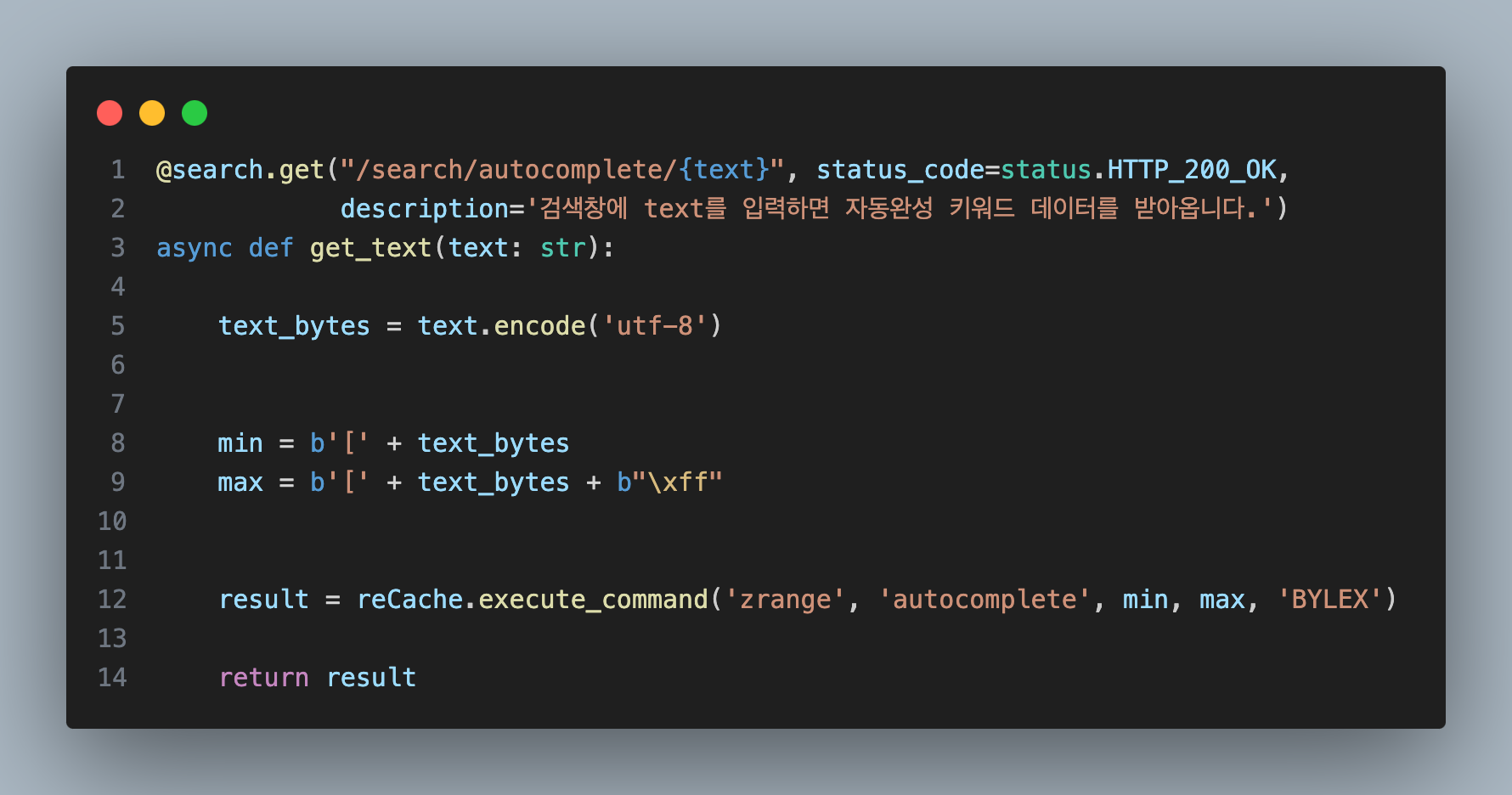
유의할 점
Redis는 항상 결과물이 utf-8형식으로 콘솔에 출력이 됩니다.
영어로 검색할 때는 크게 문제가 되지 않지만 한국어는 제대로 검색되지 않는 문제가 발생하기 때문에 text를 utf-8로 인코딩을 먼저 거쳐야 합니다.
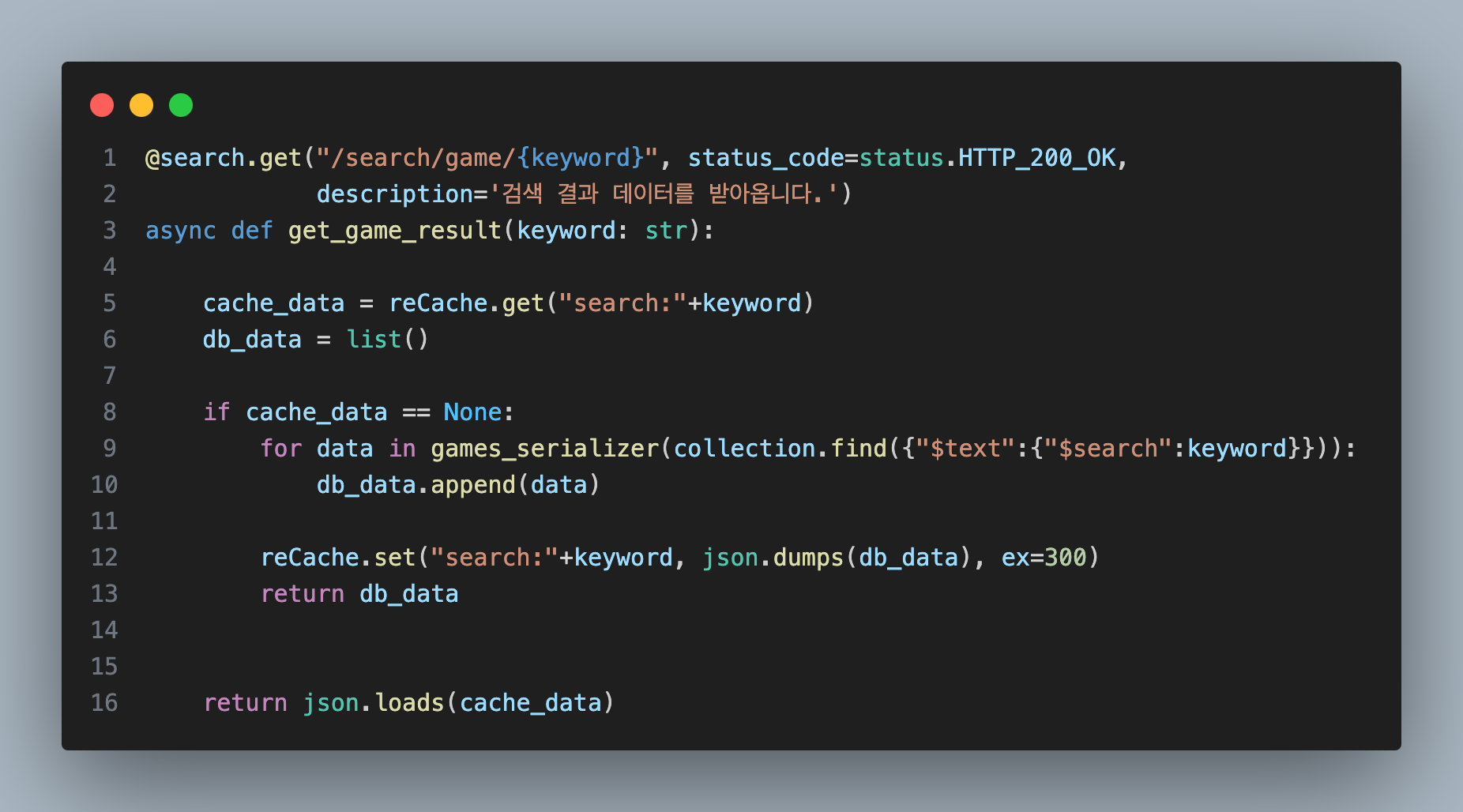
불러온 키워드로 검색하고 캐싱 하기

example를 사용자가 선택해 검색을 시도하면 바로 MongoDB를 통해 "example"을 검색합니다.
검색 결과를 Redis에 5분 동안 캐싱 하는 작업을 거쳐 최종적으로 사용자에게 결과를 보여주게 됩니다.
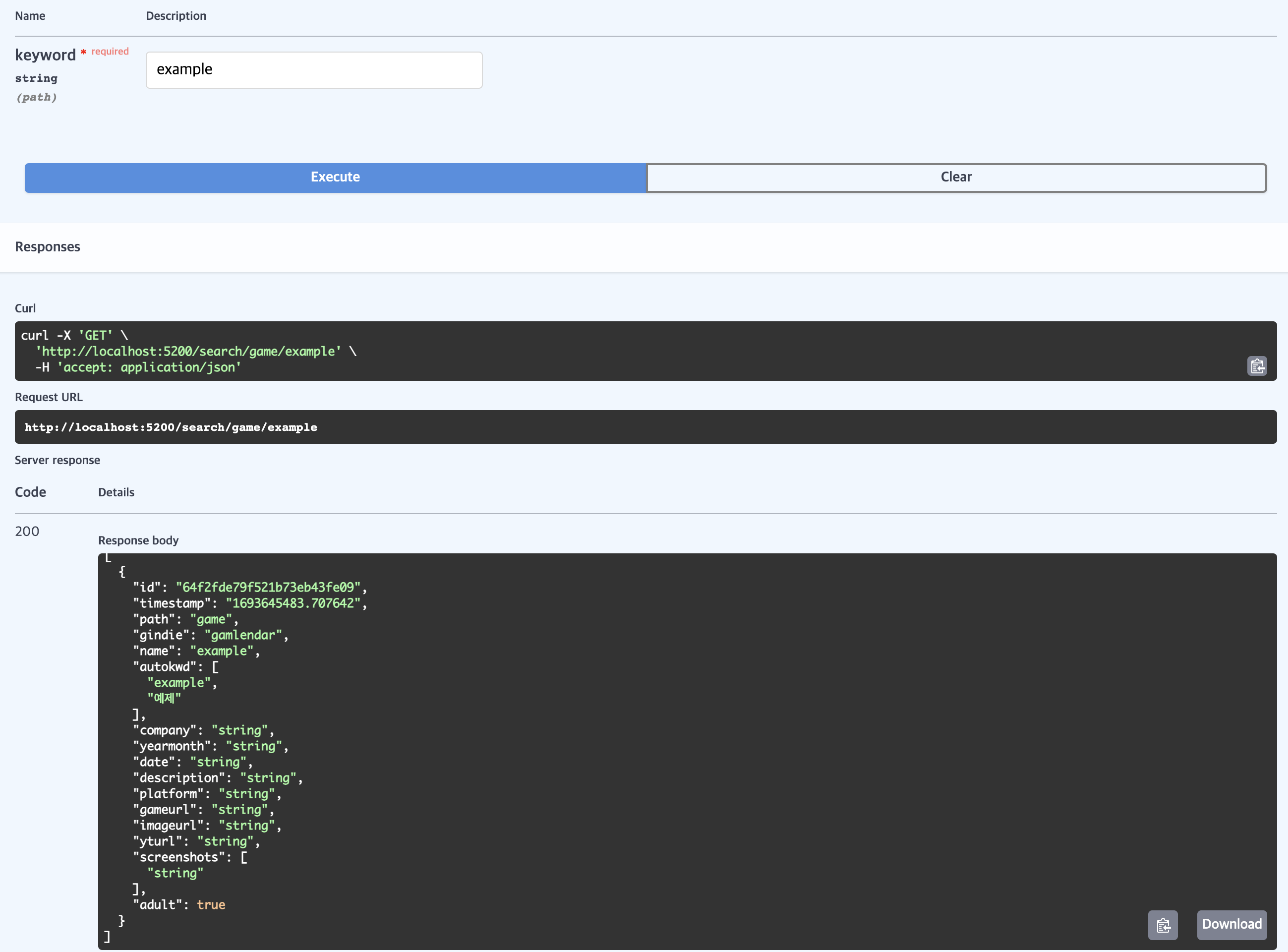
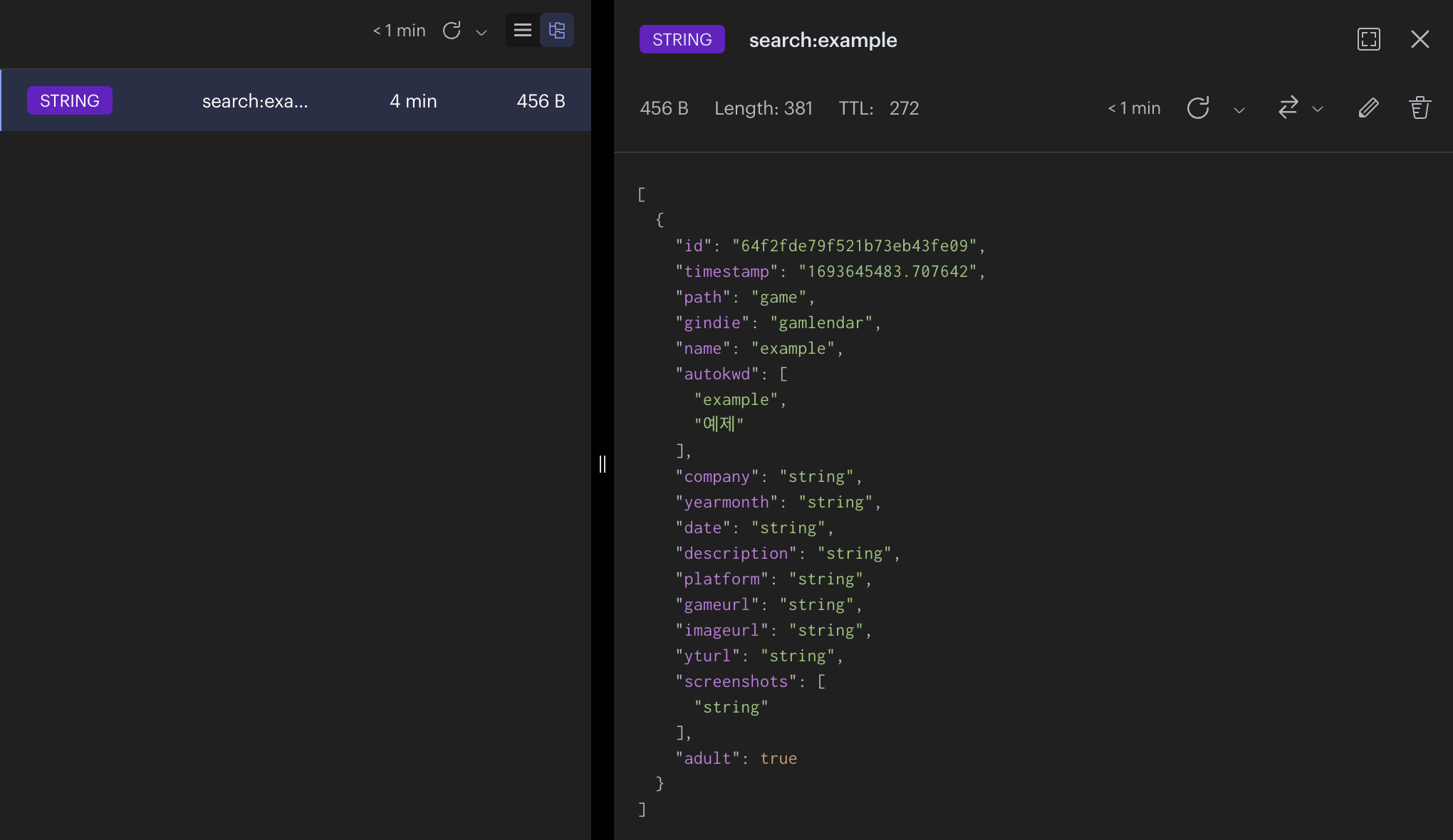
이렇게 캐싱을 하게 되면 순간적으로 검색어가 몰려 검색 시도가 발생할 때 MongoDB에 부하를 줄일 수 있다고 생각했습니다.
코드 구현
성능 개선 정리
-
기존 Redis JSON은 DB와 자동완성 기능 둘 다 수행했기 때문에 큰 트래픽이 발생하면 두 기능 전부 작동이 안됄 수 있었던 부분 개선
-
JSON 데이터가 아닌 Sorted Set 형태로 저장해 용량 문제도 개선
-
만약 위에서 제시한 Cache Warming 작업으로 시도했다면 똑같이 JSON을 Indexing 해서 결과물을 찾아야 했기 때문에 성능이나 비용적으로 비효율적
-
캐싱 작업을 통해 MongoDB의 부하를 대폭 감소
-
Redis-Stack을 사용하지 않아도 된다! Redis-Stack에 대한 의존성 낮추기...
후기
뭔가 별거 없어 보이지만, Redis를 개인적으로 공부하고
공부한 내용을 잘 활용해서 문제를 해결했다는 점이 정말 뿌듯했습니다.
물론 로직이 바뀌면서 프론트도 다시 작업을 해야 하지만
무조건 개선해야 할 부분이었고 적절하게 트레이드오프 했다고 생각합니다.
다음 글은 최종적으로 백엔드를 어떻게 설계했고,
기존 백엔드와 성능 비교 테스트도 해보면서 정리하는 글을 작성할 예정입니다.

좋은 글 감사합니다!