
글을 시작하기 전
프로젝트 기간
2022-10 ~ 2023-02
코드가 길어 Github에 업로드 합니다.
Github
Front-End
Back-End
Scraping Server
기술 스택
Front-End : React, Websocket
Back-End : Redis, Docker
MiddleWare : FastAPI
WebScrapingServer : Websocket, Selenium, BeautifulSoup4, Python Request
Language : Python, JavaScript
제작 의도
용산에서 한창 일할 때
Selenium으로 네이버 쇼핑 데이터 수집 봇을 만들어달라고 하셨던 사장님께서
새로운 무언가를 만들어 보고 싶으셨다 하셨고 해외직구 물품을 자동으로 검색해 주고 최저가를 한눈에 보이면 좋겠다는 아이디어를 주셨다.
처음 들었을 땐 네이버 쇼핑이 너무 압도적으로 최저가를 잘 찾아주어서 이게 가능할까 싶었는데 네이버 쇼핑뿐만 아니라 다양한 오픈마켓에서 일일이 발품 뛰는 내 모습을 보면서 이 과정을 자동으로 해줬으면 좋겠다는 생각으로 제작하게 되었다.
스카이스캐너 같은 최저가 항공권을 찾게 해주는 서비스처럼 만들어 보면 재밌을 것 같았다.
마침 겜린더로 FastAPI와 Redis를 공부도 했겠다, 내가 공부했던 기술들을 모두 이용하면 만들 수 있을 것 같아
새로운 사이드 프로젝트를 시작하게 되었다.
견적
어떤 기술을 사용해야 할지 스스로 견적을 맞춰보았다.
조건
1. 데이터 수집 시 무조건 백엔드 단에서 모든 것을 수행해야 한다.
2. 한 사람만 사이트를 사용하는 것이 아니기 때문에 데이터 수집 할 때 싱글 쓰레드나 프로세스가 아닌 멀티 쓰레드 혹은 프로세스를 이용해야 한다.
3. 검색어 자동 완성 기능이 무조건 있어야 한다.
4. 같은 시간대에 중복 검색어 방지를 위한 최소한의 방어 수단이 있어야 한다.
Front-End
-
React : 이번엔 최초로 웹 페이지를 만들어 보기로 했다. 겜린더를 통해 React Native를 해서 그나마 익숙한 React로 제작하는 것이 개발에 유리하다고 생각하였다.
-
WebSocket : DB에 만약 데이터가 없을 때 스크래핑 서버와 통신하기 위해서 WebSocket을 사용하였다.
당장 생각나는 게 웹 소켓밖에 없었다...
Back-End
-
Redis (Redis-Stack) : 겜린더에서도 사용했던 Redis를 활용할 예정이다. Memory 기반 DBMS라서 읽기, 쓰기 속도가 빠른 것도 있고 상대적으로 성능이 좋지 못한 하드웨어에서도 준수한 성능을 내줄 수 있을 것으로 생각했다.
-
Docker : 겜린더를 만들었을 때 Docker를 이용해서 Local로 돌리고 있는데 Container로 분리가 되어 사용이 편리할 것 같아 개발환경에선 Docker를 사용하게 되었다.
MiddleWare
- FastAPI : 이것도 겜린더에서 사용했었지만, 성능도 좋고 내가 현재 구현하려는 선에서 FastAPI가 역할을 훌륭하게 수행해 줄 것 같아 적용하였다.
Web Scraping Server
-
Selenium : 대부분의 웹 페이지가 동적 웹페이지여서 원활하게 데이터를 받아오려면 직접 브라우저를 조작해 가며 데이터를 수집해야 한다고 생각하였다.
-
BeautifulSoup4 : Selenium으로도 HTML 태그를 불러올 수 있지만 BS4가 좀 더 속도가 빠른 것 같아 같이 사용할 것이다.
-
WebSocket : Front-End에서 전송한 텍스트 데이터를 받아와서 스크래핑을 실행하게 해주는 역할을 할 것이다.
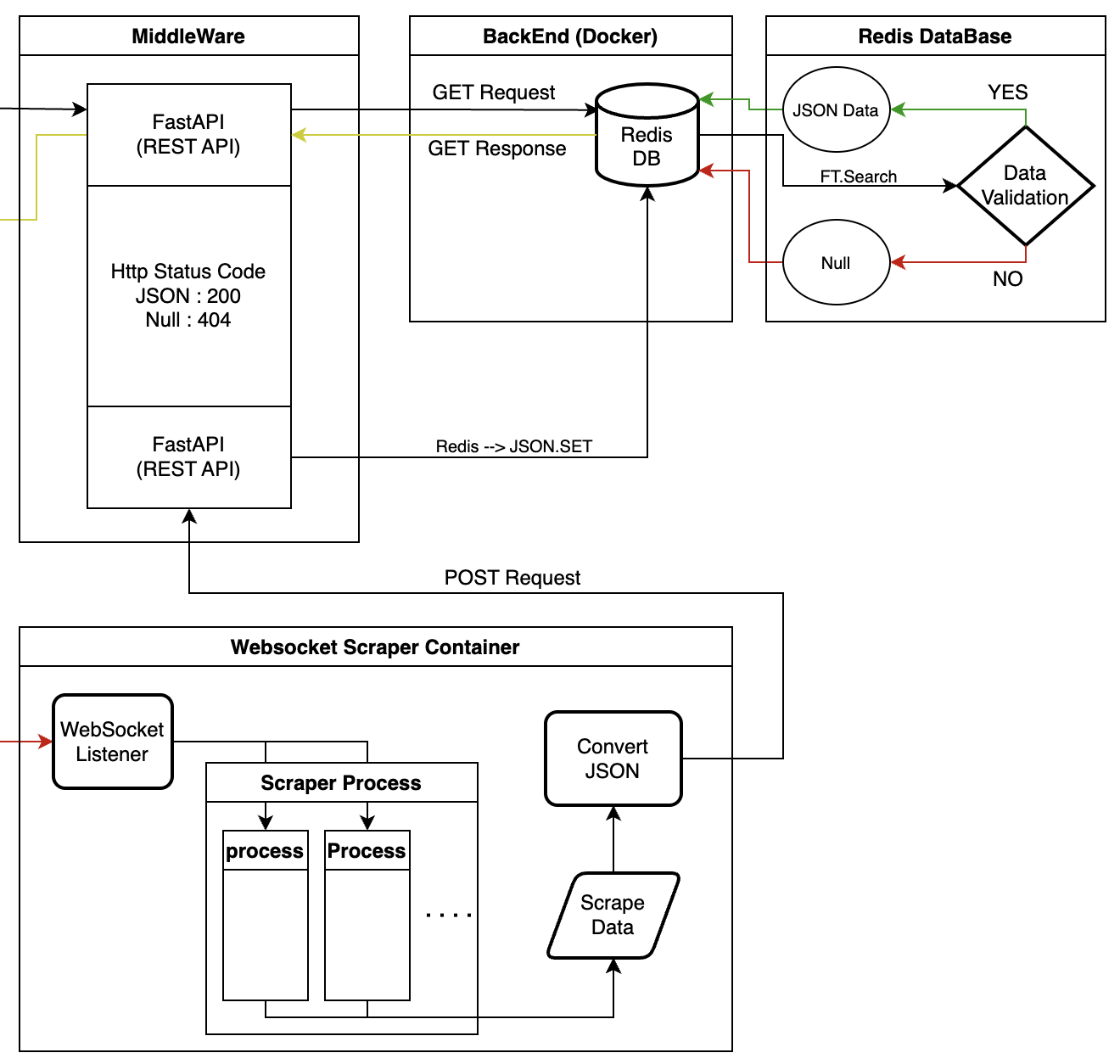
설계

기존에 노트에 단순하게 적었던 설계를 구체화시켰다. 만들다보니 MiddleWare에 각각의 기능들이 의존하는 형태가 마치... SOA(Service Oriented Architecture) 형식처럼 나오게 되었다.
설계한 부분을 하나씩 설명해 볼까 한다.
(분명 복잡하지 않은데 플로우차트가 복잡하게 나왔다...)
Front-End
React 개발한 Front-End는 엄청 단순하게 검색, 결과 이렇게 2가지의 페이지로 구성하였다.
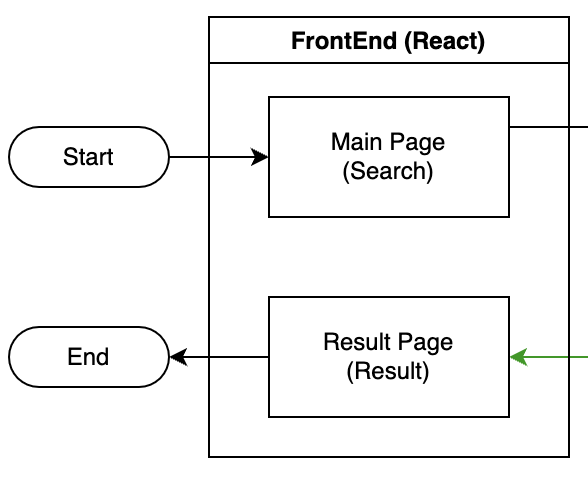
Main Page

단순하게 만들었고 아까 조건 중 3번 조건인 검색어 자동 완성 기능을 만들었다.

아마존의 자동 완성 기능을 이용하였는데
상품 검색 위주의 내 프로젝트에선 아마존의 자동 완성 기능은 매우 적합했다.
Result Page
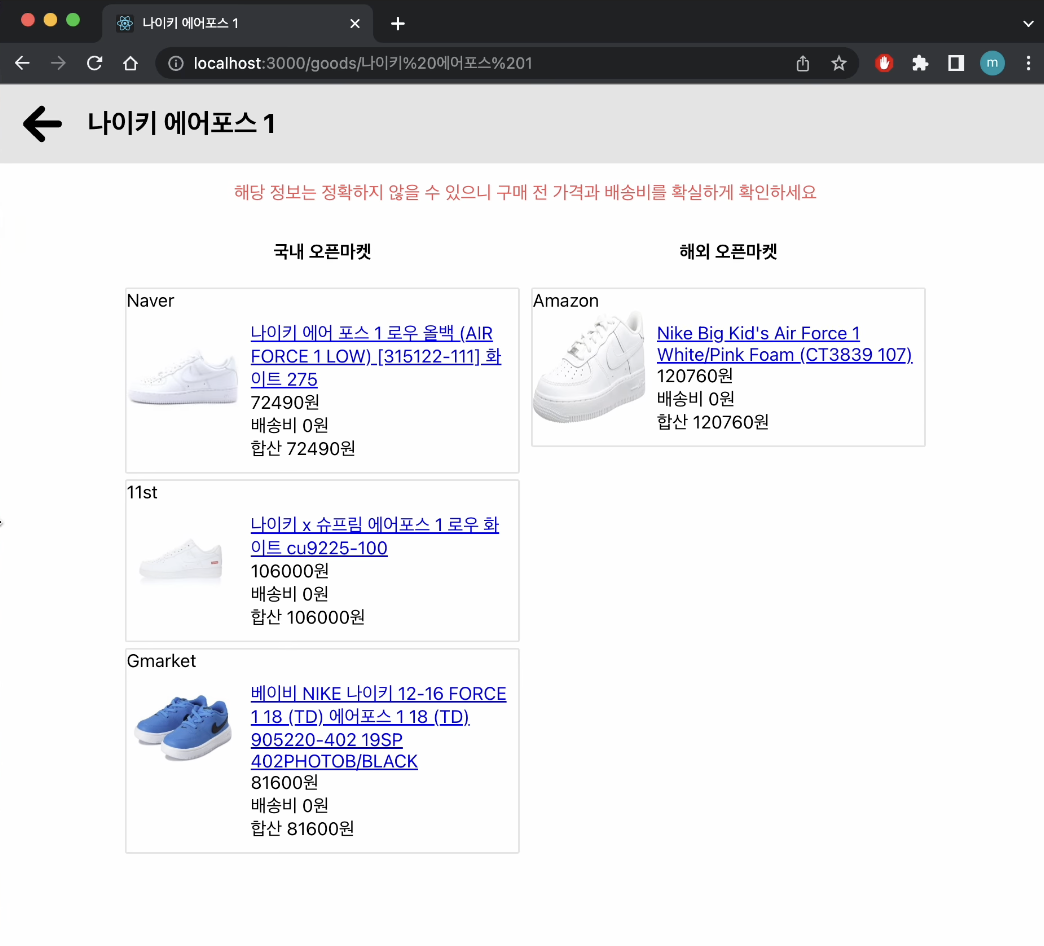
결과 페이지는 국내, 해외 오픈마켓으로 구역을 나눠서 나오게 하였고, 배송비로 가격을 올리는 업체도 있어 배송비도 데이터 수집을 해 합산 가격이 나오도록 만들어 보았다.
Back-End
유효한 데이터가 있는지 판단
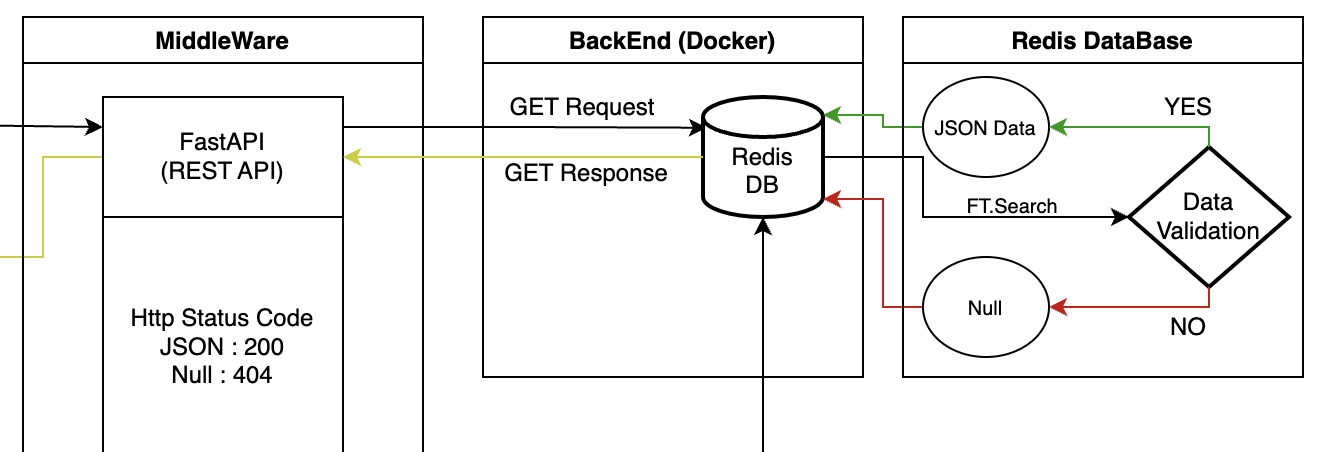
FastAPI를 통해 검색어를 받은 Redis에선 FT.Search를 통해 데이터가 있는지를 확인한다. 데이터가 있으면 JSON 형식의 Data를 출력하고 없으면 Null을 출력한다.
전체적인 설계 Flow 설명
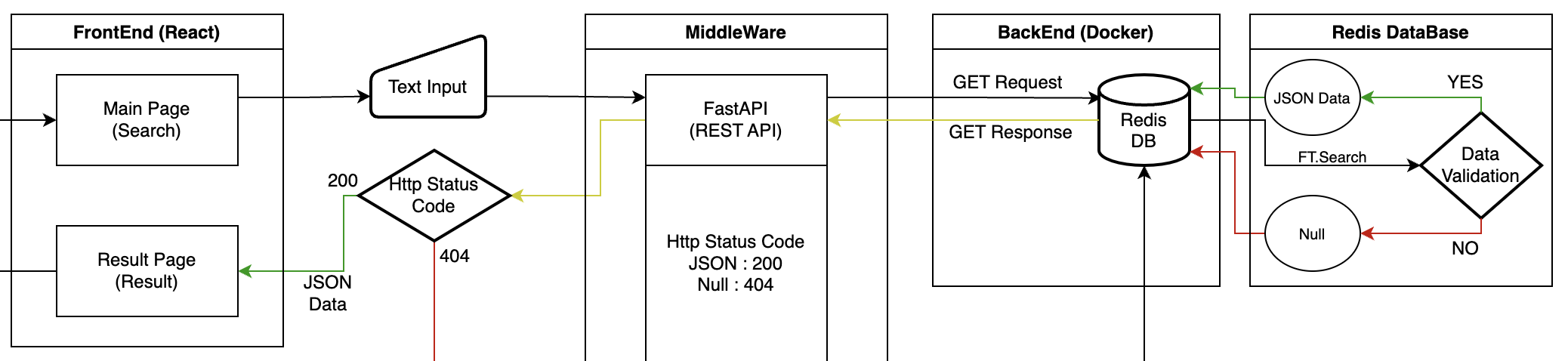
- Main Page에서 입력한 검색어를 FastAPI를 통해 GET 요청을 한다.
- FastAPI에선 Redis DB에 접속 후 FT.SEARCH 명령어를 통해 검색어에 맞는 유효한 데이터가 있는지 확인한다.
- 데이터가 있으면 JSON 형식의 Data 보내고 없으면 Null을 보내준다.
- 데이터를 받은 FastAPI는 유효한 데이터면 Status Code 200, Null이면 404를 Return 할 수 있게 하였다.
- Status Code 200인 경우 Result 페이지를 보여준다.
그럼 404면 어떻게 될까?
Web Scraping Server
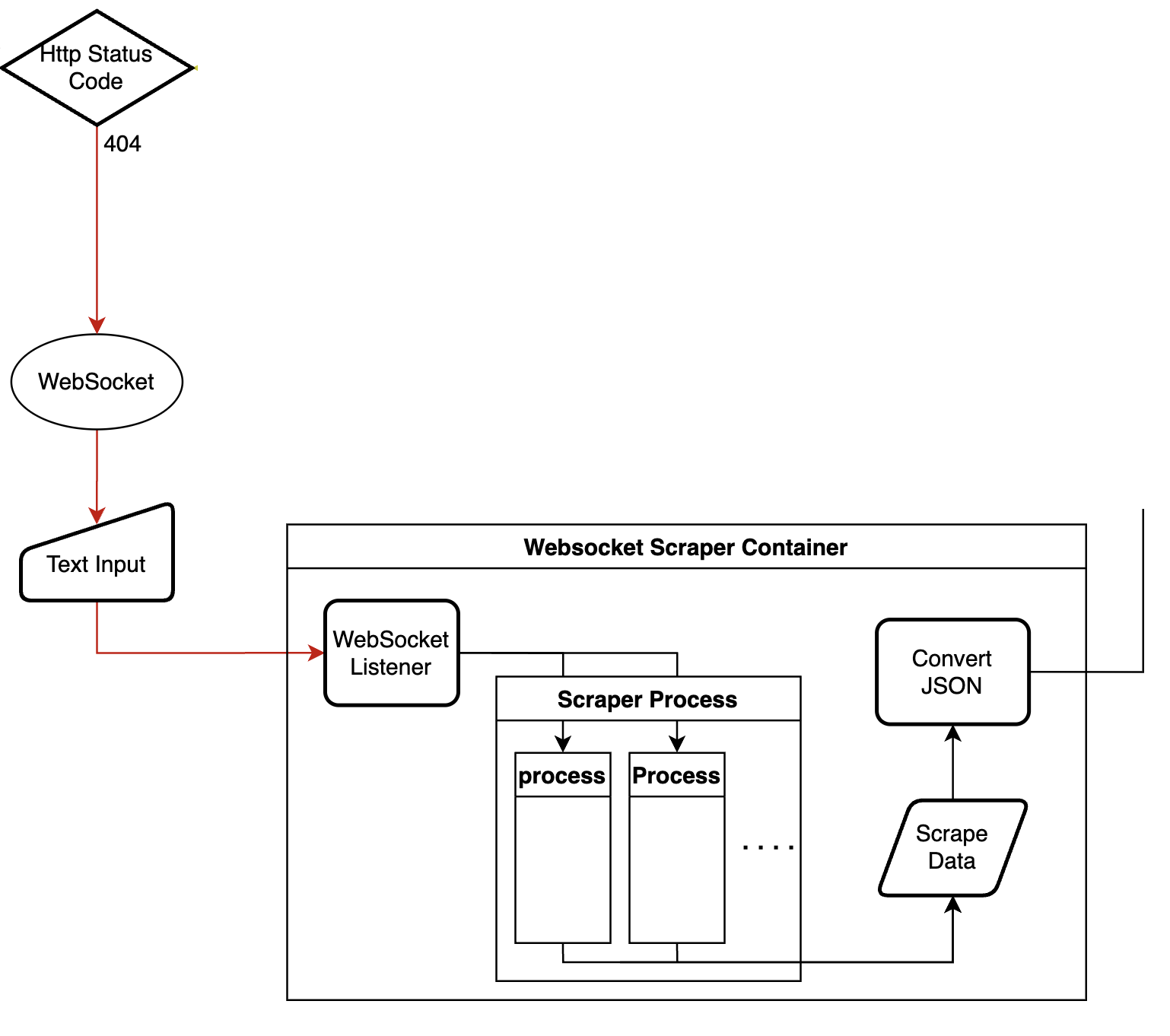
WebSocket Listener(Recevier)
FrontEnd에서 보내준 검색어를 받아 Scraper Process Container에 새로운 Process를 추가한다.
Scraper Process
글 위에 작성했던 조건 중 2번 조건인
"한 사람만 사이트를 사용하는 것이 아니기 때문에 데이터 수집 할 때 싱글 스레드나 프로세스가 아닌 멀티 스레드 혹은 멀티 프로세스를 이용해야 한다."
부분을 해결하였다.
Python의 Multiprocessing 라이브러리를 사용해 어떤 검색어가 들어와도 바로 스크래핑 봇을 실행해 다수의 일을 해결할 수 있게 만들었다.
테스트 영상.gif멀티 스레드 vs 멀티 프로세스
어떤 걸 사용해야 할까?
스크래핑 서버는 성능보다 안정성이 중요하다는 점을 고려하였을 때 멀티 스레드보다는 메모리 공간과 CPU 시간을 더 많이 사용하지만 독립된 구조로 작동하여 안정성이 높은 멀티 프로세스를 선택하였고, 무엇보다 문제가 발생해도 다른 프로세스에 영향을 주지 않는다는 점이 안정성에 도움이 될 것 같아 선택하게되었다.
Scrape Data & Convert JSON
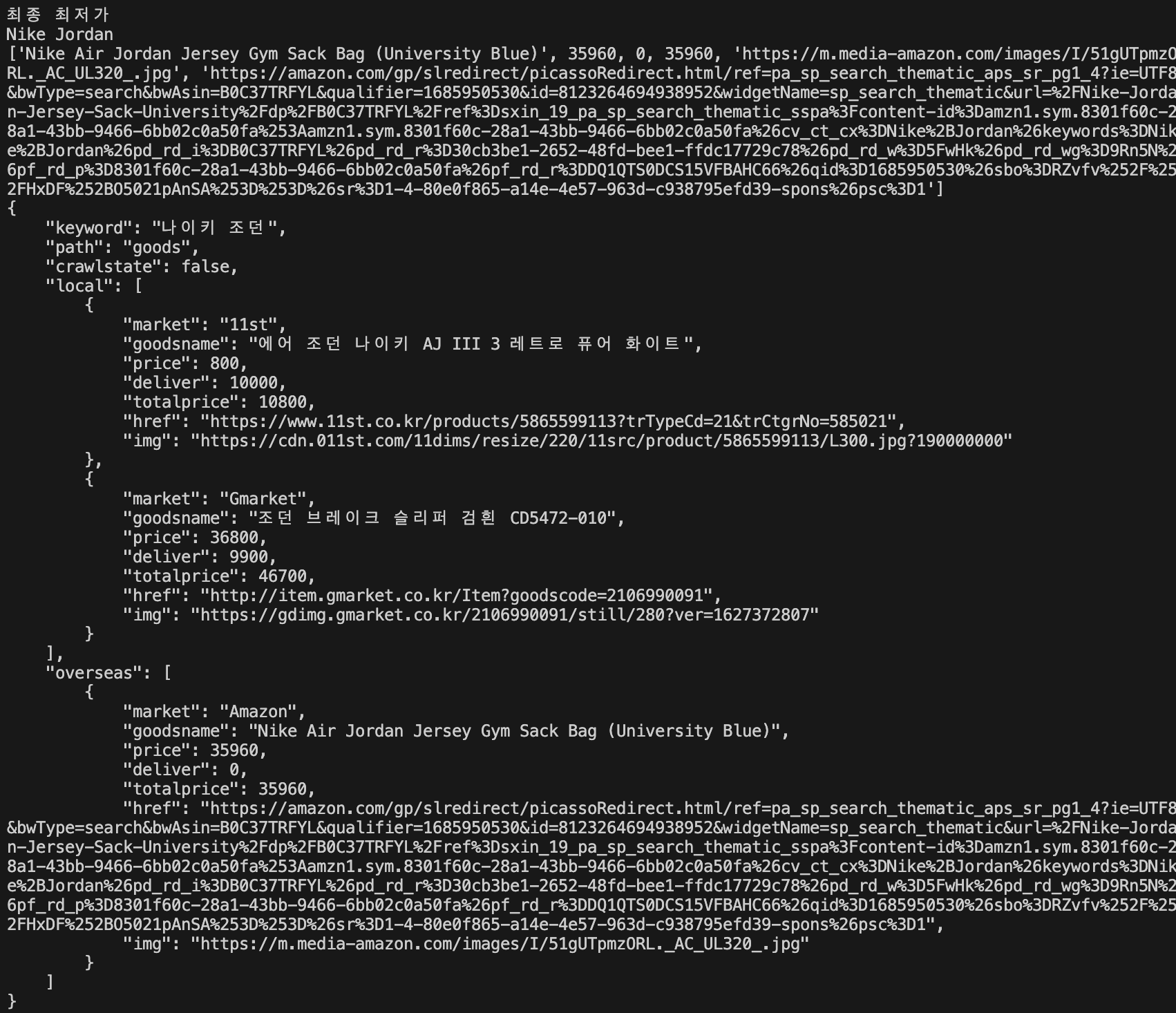
스크래핑한 데이터를 JSON 형식으로 변환하는 과정이다.
DB 저장
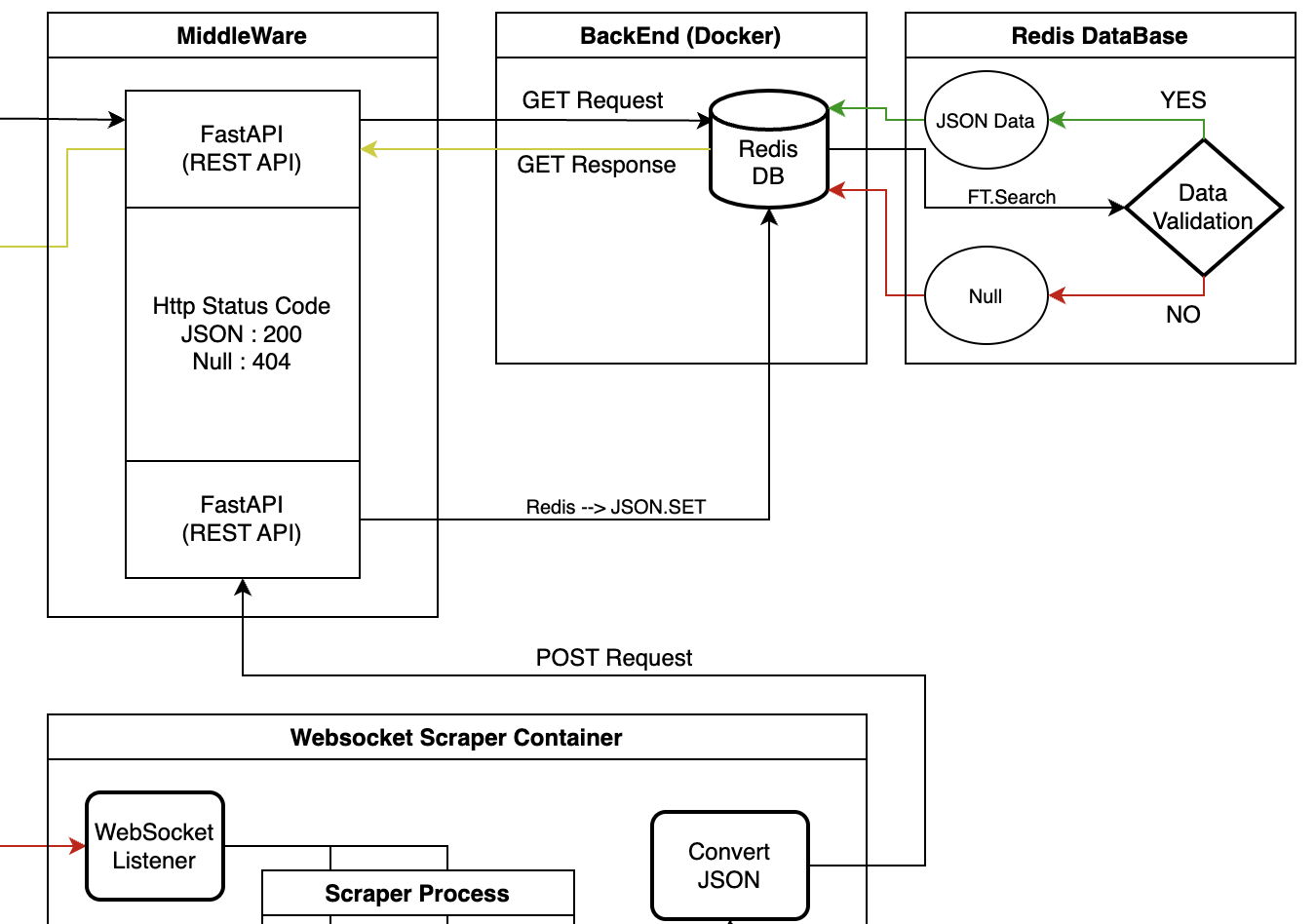
JSON Data를 POST 요청을 통해 FastAPI에선 Redis에 JSON.SET 명령어를 통해 DB에 저장하게 된다.
전제적인 Flow 설명
-
Front-End에서 WebSocket을 연결 후 검색어를 WebSocket Listener(Recevier)에 전송한다.
-
Scraper Process Container에 Process가 추가된다. (스크래핑 시작)
-
스크랩한 데이터를 JSON 형식으로 변환한다.
-
JSON 형식의 데이터를 FastAPI를 통해 데이터를 전송한다 (POST)
-
FastAPI에선 JSON.SET 명령어를 통해 Redis DB에 데이터를 저장한다.
-
저장한 데이터를 FrontEnd에서 다시 요청해 최종적으로
Status Code 200이 나오고 Reuslt 페이지가 나오게 된다.
결과
모든 조건을 해결했는가?
1. 데이터 수집 시 무조건 백엔드 단에서 모든 것을 수행해야 한다.
A. 데이터 수집과 저장 모두 백엔드 단에서 모든 걸 수행하게 되었다.
2. 한 사람만 사이트를 사용하는 것이 아니기 때문에 데이터 수집 할 때 싱글 쓰레드나 프로세스가 아닌 멀티 쓰레드 혹은 프로세스를 이용해야 한다.
Python의 MultiProcessing을 이용해 해결하였다.
3. 검색어 자동 완성 기능이 무조건 있어야 한다.
아마존의 자동 완성 기능을 이용해 해결하였다.
4. 같은 시간대에 중복 검색어 방지를 위한 최소한의 방어 수단이 있어야 한다.
여러 사용자가 같은 검색어를 입력하게 되면 중복된 데이터를 수집할 수 있는 시나리오를 예상했고
상품 가격이 실시간으로 급변하지 않기 때문에 수집한 데이터는 6시간 동안 유지되게 제작하였다.
즉, DB에 데이터가 있어도
6시간이 지나면 다시 데이터 수집을 해서 새로운 데이터로 유지할 수 있게 만들었다.
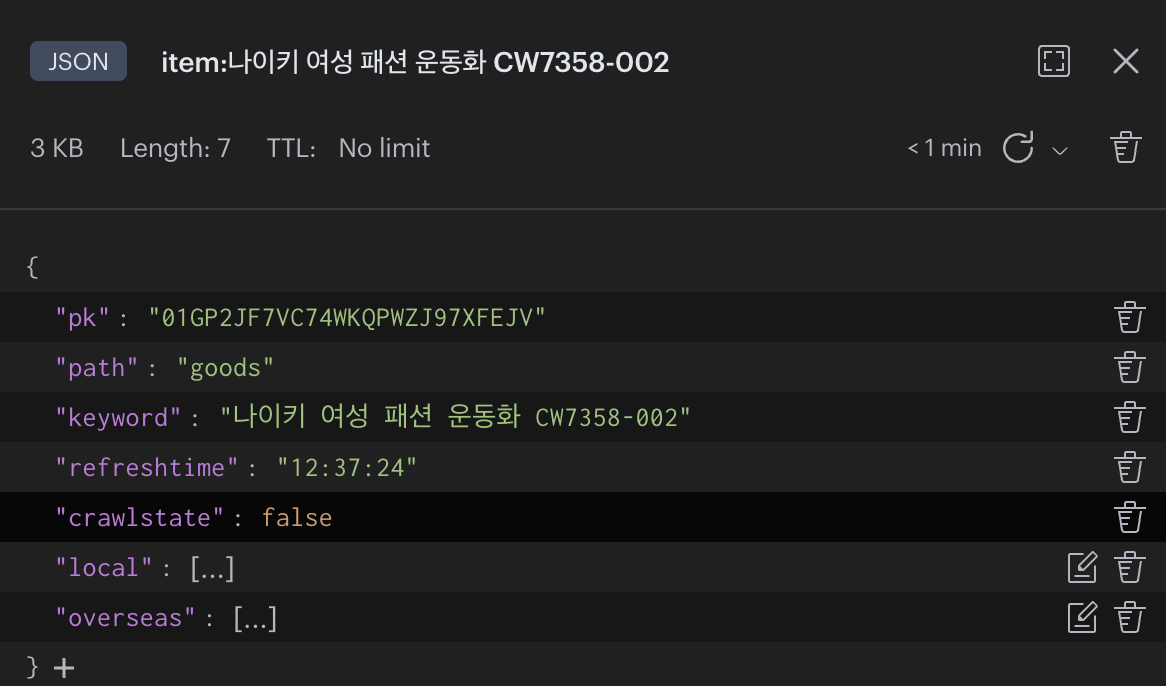
Redis의 Expire 기능을 사용하려 했으나 Expire을 사용하면 데이터가 아예 사라지기 때문에 refreshtime이란 키를 만들어 현재 시각과 비교해 데이터 수집의 판단 여부를 결정하게 했다.
아쉬운 점
1. 세상엔 다양한 상품명과 모델명 상품 코드들이 있어서 검색 정확도가 높지 못해 아쉬웠다.
이 부분은 ChatGPT를 활용해서 사전 필터링을 가져봤으면 좋았을 것 같은데 비용을 쓸 여력이 없어 패스 했다. 물론 정확도를 높이기 위해 슬라이딩 윈도우, 코사인 유사도 같은 문자열 유사도 AI나 알고리즘을 찾아봤지만 적용하지 못했었다.
2. 마감 기간이 정해져 있어 제대로 FrontEnd에 신경 쓰지 못한 점이 아쉬웠다.
2022년 10월에 시작한 프로젝트였는데 2023년 2월 초까지 프로토타입이 나와야 한다고 하셔서 Front-End에 신경 쓰지 못해 아쉬웠다.
3. 앱으로 제작하면 더 실용적이었을 것 같아 아쉬웠다.
이걸 앱으로 만들면 조금 더 실용적으로 만들 수 있었을 것 같다...
4. 여전히 부족한 기초 실력...
이런 사이드 프로젝트를 하면 할수록 기초가 정말 매우 부족하다는 것을 다시 한번 체감하게 된다. 특히 Redis 기초부터 제대로 공부해 보고 싶단 생각이 많이 들었다.
마무리
이번 사이드 프로젝트는 내가 원하는 기술로 전체적인 서비스를 만들어 볼 수 있어서 많이 배울 점이 많았던 프로젝트이다.
여기서 배운 것들을 실제로 겜린더에 적용한 것도 있고
여러모로 백엔드에 대한 이해도를 많이 높일 수 있었다.
조금 더 나은 개발자가 되기 위해 단순히 사이드 프로젝트만 진행하는 것이 아닌 꾸준하게
컴퓨터 사이언스를 공부해야겠다는 생각을 가지면서 글을 마친다.
