논문 정보
- Title: EfficientDet: Scalable and Efficient Object Detection
- Authors: Mingxing et al.
- Conference: CVPR 2020
- Posted: March 16, 2022.
Abstract
본 논문은 객체 검출(Object Detection)에서 정확도뿐 아니라 모델 효율성(Parameters, FLOPs, Latency)이 점점 더 중요해지고 있다는 문제의식에서 출발한다. 이를 위해 저자들은
- 가중치 기반 양방향 Feature Pyramid Network(BiFPN)
- Backbone·Feature Network·Prediction Head·Input Resolution을 동시에 확장하는 Compound Scaling
을 제안한다.
이 두 가지 핵심 설계를 EfficientNet backbone과 결합하여 EfficientDet이라는 새로운 detector 계열을 제시하며, COCO benchmark에서 훨씬 적은 연산량으로 SOTA 성능을 달성한다.
1. Introduction
기존 SOTA detector들은 높은 정확도를 달성했지만,
- 매우 큰 파라미터 수
- 과도한 FLOPs
로 인해 로봇, 자율주행 등 실시간·자원 제한 환경에 적용하기 어렵다.
(*Flops: 실제 계산량을 나타내는 단위, 얼마나 빨리 계산을 처리할 수 있는지에 대한 단위
- 파라미터와 함께 모델이 얼마나 큰지, 효율적인지를 나타내는 계산량, 덧셈, 곱셈을 하나의 연산으로 본다
- MAC = a*x+b연산이 몇 번 실행되었는지 세는 단위,
- 고로, FLOPs = 0.5 * MAC
FLOPs(FLoating point OPerations) ↔ FLOPS(FLoating point OPerations per Second, flop/s))
본 논문은 다음 질문을 중심으로 한다.
“넓은 자원 제약 범위(수 B ~ 수백 B FLOPs)에서 동시에 정확하고 효율적인 detector를 만들 수 있는가?”
이를 위해 one-stage detector 구조를 기반으로 feature fusion 방식과 모델 스케일링 전략을 체계적으로 재설계한다.
2. Related Work
- One-stage Detectors: SSD, YOLO, RetinaNet 등은 효율적이지만 정확도 한계 존재
two-stage detectors가 좀 더 정확하고, flexible하지만, one-stage detector가 좀 더 단순하고 높은 효율성을 갖기 때문에 본 논문은 1-stage detector를 차용하였다.
그 후 정확도를 위해 다른 아이디어들을 결합하였다.
-
Multi-scale Feature Fusion: FPN, PANet, NAS-FPN 등이 제안되었으나
- 단방향 정보 흐름
- 불필요한 노드
- 높은 연산 비용
문제가 존재
-
Model Scaling: 기존 방식은 backbone 또는 input resolution만 키우는 단일 차원 스케일링에 집중
3. BiFPN (Bidirectional Feature Pyramid Network)
3.1 Problem Formulation
Multi-scale feature fusion의 목표는 서로 다른 해상도의 feature들을 효과적으로 결합하는 것이다.
입력 feature 집합은 다음과 같이 정의된다.
여기서 는 pyramid level 에서의 input feature를 의미한다.
출력 feature는 변환 함수 를 통해 다음과 같이 정의된다.
Conventional FPN Formulation
Top-down FPN에서의 multi-scale feature aggregation은 다음과 같이 정의된다.
3.2 Cross-Scale Connections
기존 FPN은 one-way (top-down) 정보 흐름만을 가지며, 이는 표현력에 한계가 있다.
이를 개선하기 위해 BiFPN은 다음과 같은 구조적 최적화를 수행한다:
- 단일 입력만 가지는(입력이 하나뿐인) 노드 제거 -> 불필요한 연산 감소
- 동일 pyramid level 간 shortcut 연결 추가
- Top-down + Bottom-up을 하나의 layer로 정의 후 반복 적용
-> 결과적으로 단순하면서도 강력한 양방향 feature fusion 구조 형성
3.3 Weighted Feature Fusion
서로 다른 해상도의 feature들은 동일한 중요도를 가지지 않는다.
이를 반영하기 위해 각 입력 feature에 학습 가능한 가중치 를 도입한다.
Unbounded Fusion
- : 학습 가능한 scalar weight
- 단점: weight가 unbounded -> 학습 불안정 가능
Softmax-based Fusion
- 각 weight를 확률 분포로 정규화
- 단점: softmax 연산으로 인한 GPU latency 증가
Fast Normalized Fusion (최종 채택)
- 는 ReLU를 통해 보장된다.
- (numerical stability)
- Softmax 대비 거의 동일한 정확도
- GPU 기준 최대 30% 속도 향상
BiFPN Level-wise Fusion Example (Level 6)
Top-down pathway에서의 중간 feature:
Bottom-up pathway에서의 출력 feature:
- : top-down intermediate feature
- :bottom-up output feature
모든 pyramid level은 동일한 방식으로 구성된다. 또한, 효율성을 위해 feature fusion 이후
- Depthwise Separable Convolution
- Batch Normalization
- Activation
을 적용한다.
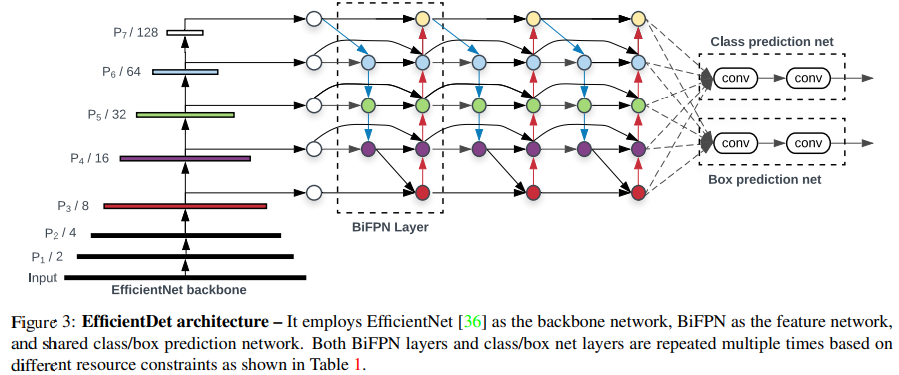
4. EfficientDet Architecture
4.1 Overall Architecture
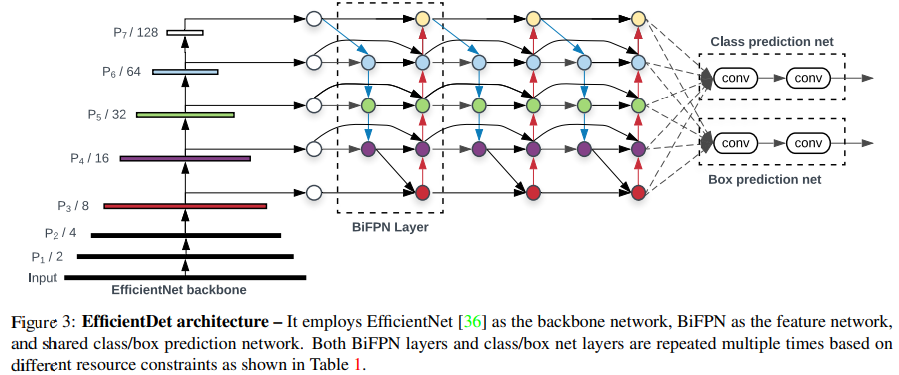
EfficientDet은 다음 구성으로 이루어진 one-stage detector이다.
- Backbone: EfficientNet (ImageNet pretrained)
- Feature Network: BiFPN (반복 적용)
- Prediction Head: Class / Box subnet
(모든 feature level에서 weight 공유)
4.2 Compound Scaling
단일 차원 스케일링의 한계를 극복하기 위해 compound coefficient 𝜙를 도입한다.
Backbone network
EfficientNet의 기존 scaling 규칙을 그대로 사용
BiFPN network
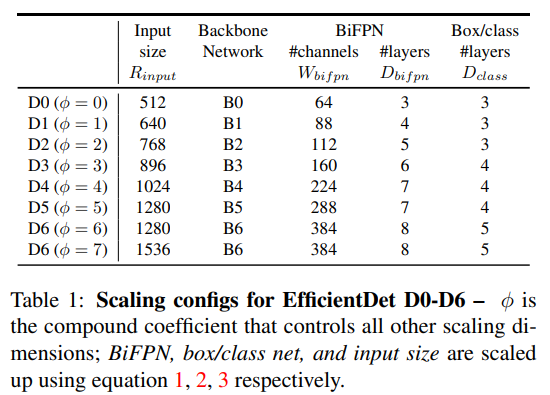
Box/class prediction network
Input Resolution Scaling
이를 통해 EfficientDet-D0 ~ D7 모델 패밀리를 구성한다.
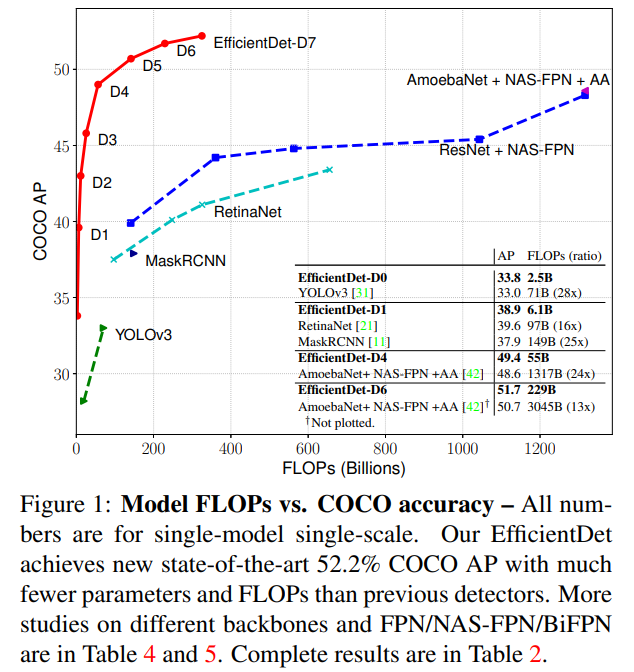
5. Experiments
5.1 EfficientDet for Object Detection
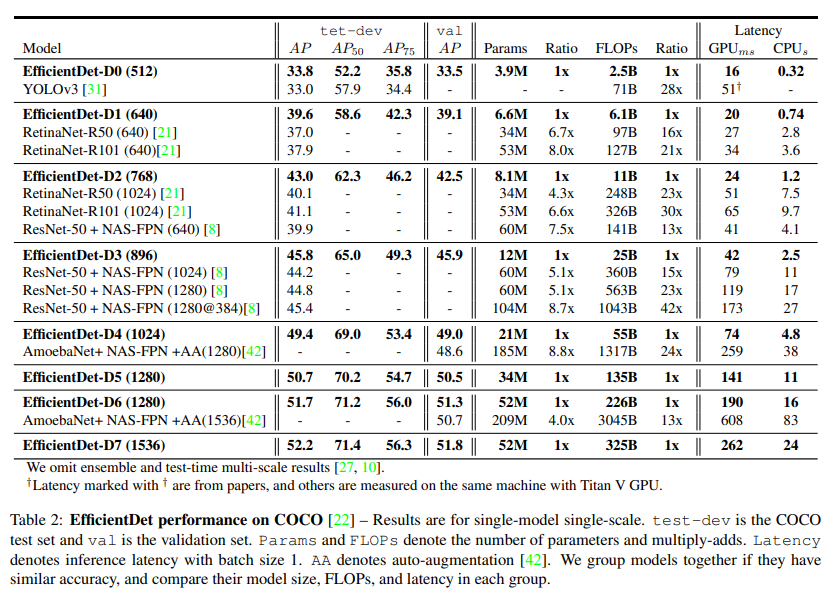
-
Single-model / Single-scale 기준
-
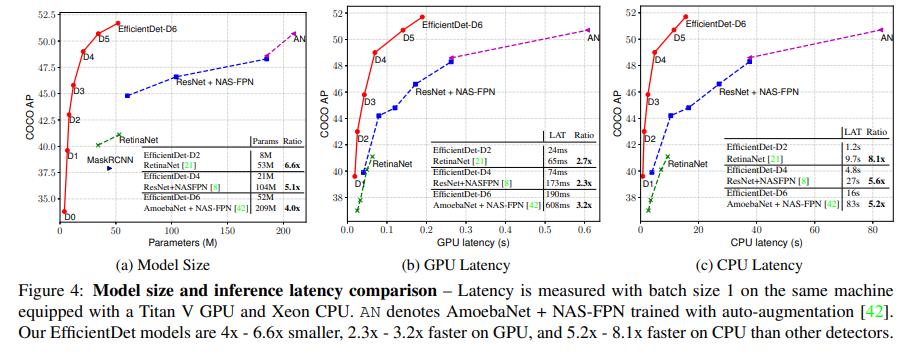
동일 정확도 대비
- 4×–9× 적은 파라미터
- 13×–42× 적은 FLOPs
-
EfficientDet-D7
- 52.2 AP (test-dev)
- 52M params / 325B FLOPs
- 기존 NAS-FPN 기반 모델 대비 압도적인 효율
5.2 EfficientDet for Semantic Segmentation
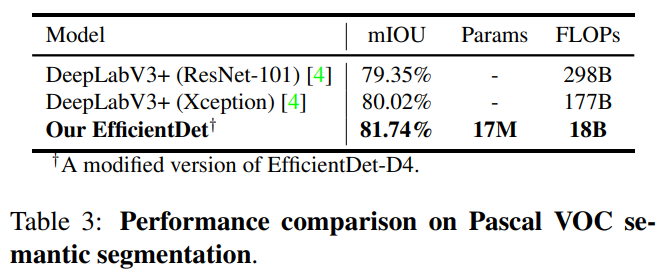
- EfficientDet-D4 기반 수정 모델
- 81.74% mIOU
DeepLabV3+ 대비
- +1.7% 정확도
- 9.8× 적은 FLOPs
-> EfficientDet의 범용성 입증
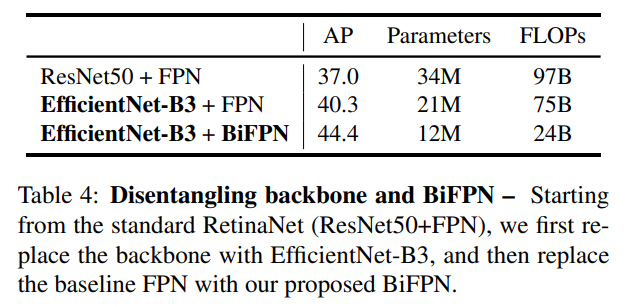
6. Ablation Study
- EfficientNet backbone + BiFPN 조합이 성능 향상의 핵심
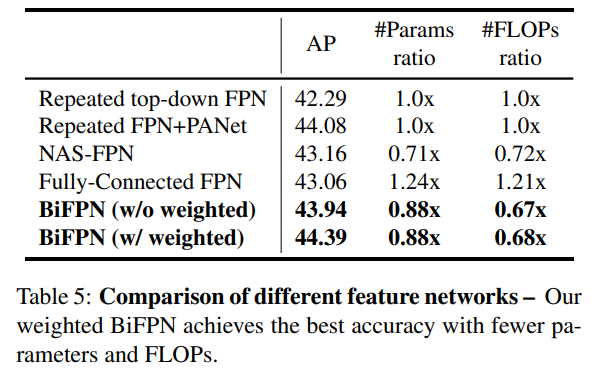
- BiFPN은
- FPN / PANet / NAS-FPN 대비
- 더 적은 연산으로 더 높은 AP
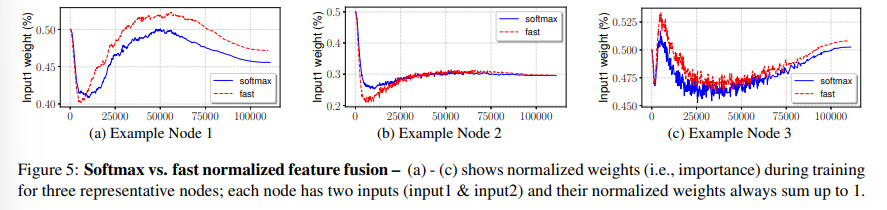
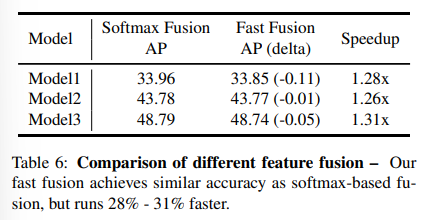
Fast Normalized Fusion
- Softmax 대비 정확도 거의 동일
- 1.26× ~ 1.31× 속도 개선
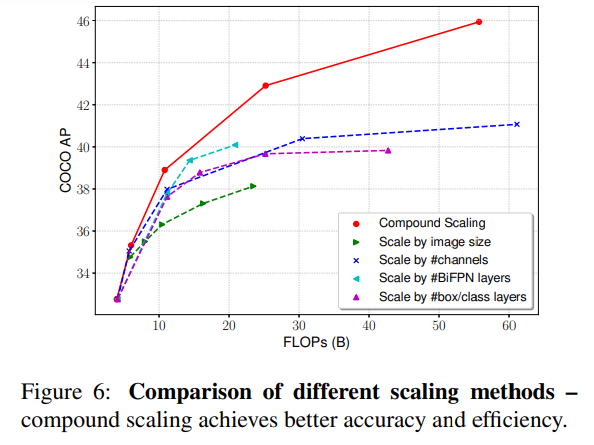
Compound Scaling
- 단일 차원 scaling 대비
- 가장 효율적인 accuracy–compute trade-off 달성
7. Conclusion
본 논문은 객체 검출에서의 효율성 중심 아키텍처 설계를 체계적으로 분석하고,
- BiFPN: 가중치 기반 양방향 multi-scale feature fusion
- Compound Scaling: detector 전체 구조를 균형 있게 확장
을 통해 EfficientDet이라는 새로운 detector 패밀리를 제안한다.
EfficientDet는 넓은 자원 제약 범위에서 일관되게 SOTA 성능을 달성하며,
실제 산업·로봇·엣지 환경에 적합한 객체 검출 모델 설계 방향을 제시한다.
