
논문 정보
- Title: You Only Look Once: Unified, Real-Time Object Detection
- Authors: Joseph Redmon et al.
- Conference: CVPR 2016
- Posted: March 15, 2022
Abstract
YOLO는 객체 검출(Object Detection) 문제를 기존의 복잡한 파이프라인 방식이 아닌 단일 회귀(regression) 문제로 재정의한 모델이다.
기존 객체 검출 모델(R-CNN 계열, DPM 등)은 다음과 같은 다단계 파이프라인을 가진다.
- Region Proposal 생성
- Bounding Box별 Feature Extraction
- Classification
- Bounding Box Refinement
- Post-processing (NMS 등)
반면 YOLO는 하나의 신경망이 이미지 전체를 단 한 번만 보고 다음을 동시에 예측한다.
- Bounding Box 좌표
- Class Probability
이로 인해 End-to-End 학습이 가능하며, 실시간 객체 검출이 가능할 정도로 매우 빠르다.
- YOLO: 약 45 FPS
- Fast YOLO: 약 155 FPS
1. Introduction
1.1 기존 객체 검출 방식의 한계
(1) Deformable Parts Model (DPM)
- Sliding Window 방식
- 이미지 전체를 탐색해야 하므로 연산량이 매우 큼
(2) R-CNN 계열
- Region Proposal -> CNN -> Classifier -> Bounding Box Regression
- 파이프라인이 복잡하고 단계별 독립 학습 필요
- 실시간 처리 불가
문제점 요약
- 파이프라인이 복잡함
- End-to-End 최적화 불가
- 속도가 느림
1.2 YOLO의 핵심 아이디어
YOLO는 객체 검출을 다음과 같이 정의한다.
이미지 픽셀 -> Bounding Box 좌표 + Class Probability
이를 하나의 회귀 문제로 통합하여, "You Only Look Once" 라는 이름이 붙었다.
YOLO의 주요 특징은 다음과 같다.

1. Single CNN으로 모든 예측 수행 -> 매우 빠름
2. 이미지 전체를 보며 학습 -> Context 정보 활용
3. Background Error가 Fast R-CNN 대비 약 2배 적음
4. 자연 이미지뿐 아니라 예술 작품 등 새로운 도메인에도 강건
단점으로는 당시 SOTA 모델 대비 mAP가 다소 낮다는 점이 있다.
2. Unified Detection
Grid Cell 개념
입력 이미지를 grid로 분할한다.
-
객체의 중심(center) 이 포함된 grid cell이 해당 객체를 책임
-
각 grid cell은 다음을 예측
- 개의 Bounding Box
- 각 Bounding Box의 Confidence Score
- 개의 Conditional Class Probability
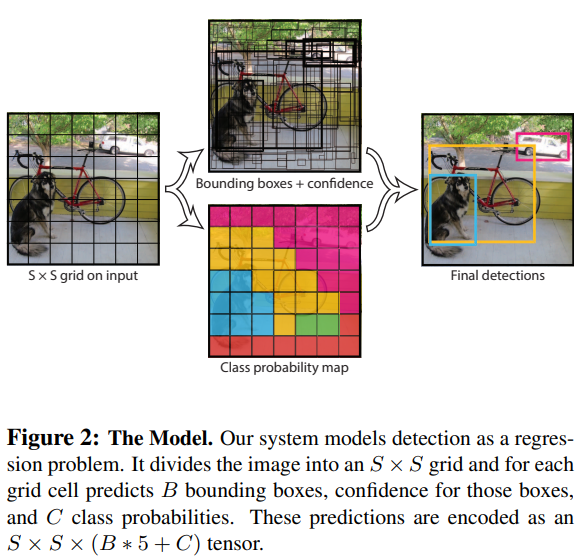
Bounding Box 표현
각 Bounding Box는 다음 5개의 값으로 표현된다.
- : grid cell 내 상대 중심 좌표 (0~1)
- : bounding box의 상대 너비와 높이 (0~1)
- : 객체 존재 여부 및 박스 정확도
Confidence Score는 다음과 같이 정의된다.
Class Probability
각 grid cell은 하나의 클래스만 예측한다.
테스트 시 특정 bounding box가 클래스 일 확률은 다음과 같다.
최종 출력 텐서 구조
논문에서 사용한 설정은 다음과 같다.
따라서 최종 출력 텐서의 차원은
2.1 Network Design

YOLO 네트워크는 다음과 같은 구조를 가진다.
- Convolutional Layers: 이미지 특징 추출
- Fully Connected Layers: Bounding Box와 Class 예측
GoogLeNet 구조에서 영감을 받았지만, Inception 모듈 대신
- Reduction Layer
- Convolution
의 조합을 사용한다.
2.2 Training
Pretraining
- ImageNet 1000-class 분류 문제로 사전 학습
- 전체 24개 Conv layer 중 20개만 사용
Detection Training
- Conv 4개 + FC 2개 layer 추가
- 입력 해상도:
Activation Function
- 마지막 Layer: Linear Activation
- 나머지 모든 Layer: Leaky ReLU
Loss Function
YOLO는 SSE (Sum-Squared Error) 를 사용한다.
기존 SSE의 문제점
- Localization Loss와 Classification Loss를 동일 가중치로 처리
- Large Box와 Small Box에 동일한 패널티 부여
- 대부분 grid cell이 background → 학습 불균형 발생
개선 기법
(1) Width, Height에 Square Root 적용
→ 큰 박스의 loss 영향 감소
(2) Loss 가중치 도입
2.3 Inference
- 테스트 시에도 단 한 번의 네트워크 연산
- 이미지 당 98개의 Bounding Box 예측
- Non-Maximum Suppression(NMS) 적용
2.4 Limitations of YOLO
-
Spatial Constraint
- 하나의 grid cell당 하나의 객체만 검출 가능
- 작은 객체가 밀집된 상황에 취약
-
Aspect Ratio 일반화 문제
- 학습하지 않은 종횡비에 약함
-
Localization Precision 한계
- 작은 객체에서 IOU 변화에 민감
3. Comparison to Other Detection Systems
Deformable parts models.
Deformable parts models(DPM)은 sliding window 방식을 통해 detection을 수행한다. DPM은 정적 feature을 추출하고 영역을 분류하며 점수가 높은 영역에 대한 bounding box를 예측하는데 분리된 파이프라인을 사용한다. 이에 반해 YOLO는 이 모든 부분을 단일 컨볼루션 신경망으로 대체한다. 네트워크는 feature 추출, bounding box 예측, NMS 및 contextual reasoning을 동시에 수행한다.
R-CNN.
R-CNN과 그 변형은 이미지에서 object를 찾기 위해 region proposal을 사용한다. Selective search는 잠재적 bounding box를 생성하고, CNN 추출 기능을 생성하고, SVM은 상자에 점수를 매기고, 선형 모델은 bounding box를 조정하며, NMS 기능은 중복된 탐지를 제거한다. 이 복잡한 파이프라인의 각 단계는 독립적으로 fine-tuning해야 하며 매우 느려서 시험 시간에 이미지당 40초 이상이 걸린다.
YOLO는 각 그리드 셀이 bounding box를 예측하고 그 box에 대해 점수를 계산한다는 부분에서 R-CNN과 유사하다. 하지만 YOLO는 각 그리드 셀의 공간적 제약 때문에 하나의 object가 여러 번 검출되는 경우가 R-CNN에 비해 적다. YOLO는 또한 selective search의 약 2000개에 비해 이미지당 98개로 훨씬 적은 수의 bounding box를 제안한다. 마지막으로, 우리 시스템은 이러한 개별 구성 요소를 공동으로 최적화된 단일 모델로 결합한다.
4. Experiments
YOLO는 PASCAL VOC 2007 기준으로 다른 실시간 객체 검출 모델들과 성능을 비교한다.
또한 YOLO와 Fast R-CNN의 에러 유형 차이를 분석하고, 두 모델을 결합했을 때 성능이 어떻게 향상되는지를 보인다.
이후 VOC 2012 결과와 새로운 도메인(예술 작품) 에 대한 일반화 성능을 평가한다.
4.1 Comparison to Other Real-Time Systems
기존 객체 검출 연구들은 속도 개선에 집중했지만, 실제로 실시간(30 FPS 이상)을 달성한 모델은 매우 적다.
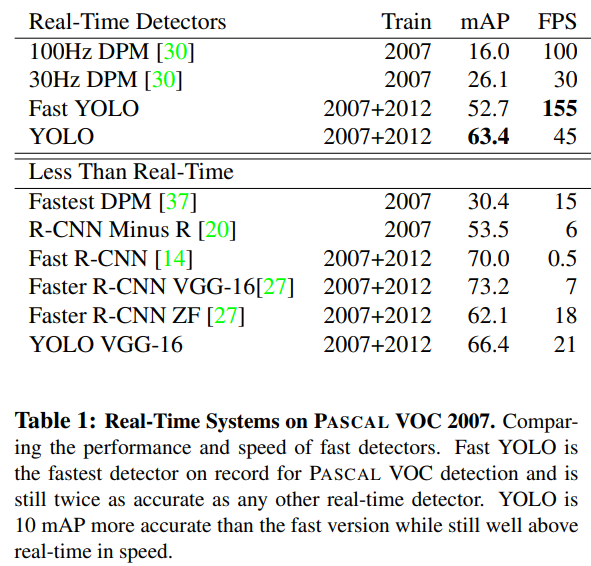
-
Fast YOLO
- PASCAL VOC 기준 가장 빠른 객체 검출기
- mAP 52.7%로 기존 실시간 모델 대비 2배 이상 정확
-
YOLO
- mAP 63.4%를 달성하면서도 실시간 성능 유지
- mAP 52.7%로
다른 모델들과의 비교 결과:
-
DPM 계열: 속도는 개선되었으나 실시간에는 미달, 정확도도 낮음
-
Fast R-CNN: mAP는 높지만 Selective Search로 인해 매우 느림 (0.5 FPS)
-
Faster R-CNN: Selective Search를 대체했으나
- 가장 정확한 모델은 YOLO보다 6배 느림
- 빠른 버전은 정확도가 낮음
YOLO는 속도와 정확도의 균형 측면에서 가장 실용적인 실시간 검출기임을 보여준다.
4.2 VOC 2007 Error Analysis
YOLO와 Fast R-CNN의 성능 차이를 이해하기 위해 에러 유형별 분석을 수행한다.
에러 유형 정의:
-
Correct: class 정확 + IOU > 0.5
-
Localization: class 정확, 0.1 < IOU < 0.5
-
Similar: 유사 클래스, IOU > 0.1
-
Other: 잘못된 클래스, IOU > 0.1
-
Background: IOU < 0.1
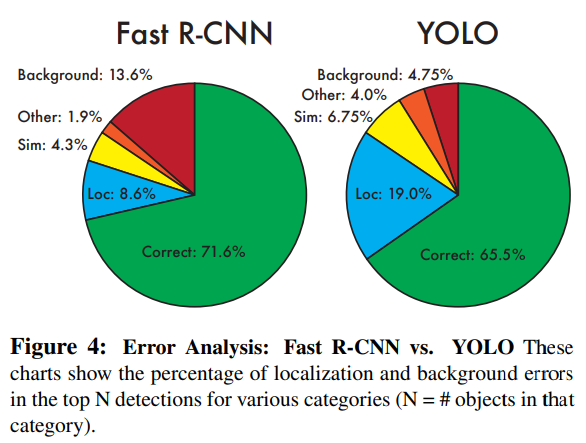
분석 결과:
-
YOLO는 Localization Error가 가장 큼 → 위치 정확도가 약함
-
Fast R-CNN은 Background Error가 매우 큼
-
상위 검출 중 13.6%가 실제 객체가 없는 false positive
-
YOLO보다 약 3배 더 자주 배경을 객체로 오인
-
YOLO와 Fast R-CNN은 서로 다른 종류의 실수를 한다는 점이 핵심이다.
4.3 Combining Fast R-CNN and YOLO
YOLO는 배경 오검출(background false positive) 이 매우 적다는 강점이 있다.
이를 활용해 Fast R-CNN의 검출 결과를 YOLO로 재평가(rescore) 하면 성능이 크게 향상된다.
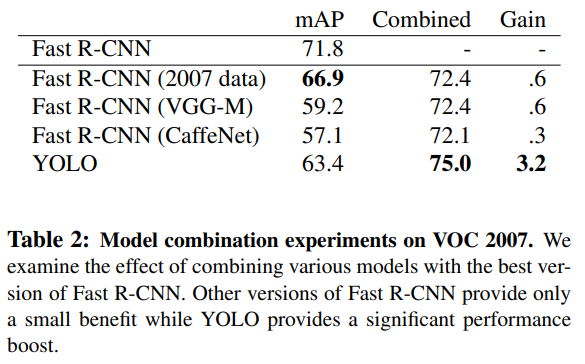
결과:
-
Fast R-CNN 단독: mAP 71.8%
-
Fast R-CNN + YOLO 결합 시 mAP 유의미하게 증가 (Table 2 참고)
중요한 점:
-
단순한 앙상블 효과가 아님
-
서로 다른 에러 특성을 가지기 때문에 시너지가 발생
속도 측면에서도:
-
YOLO가 매우 빠르기 때문에
-
Fast R-CNN에 추가적인 연산 부담이 거의 없음
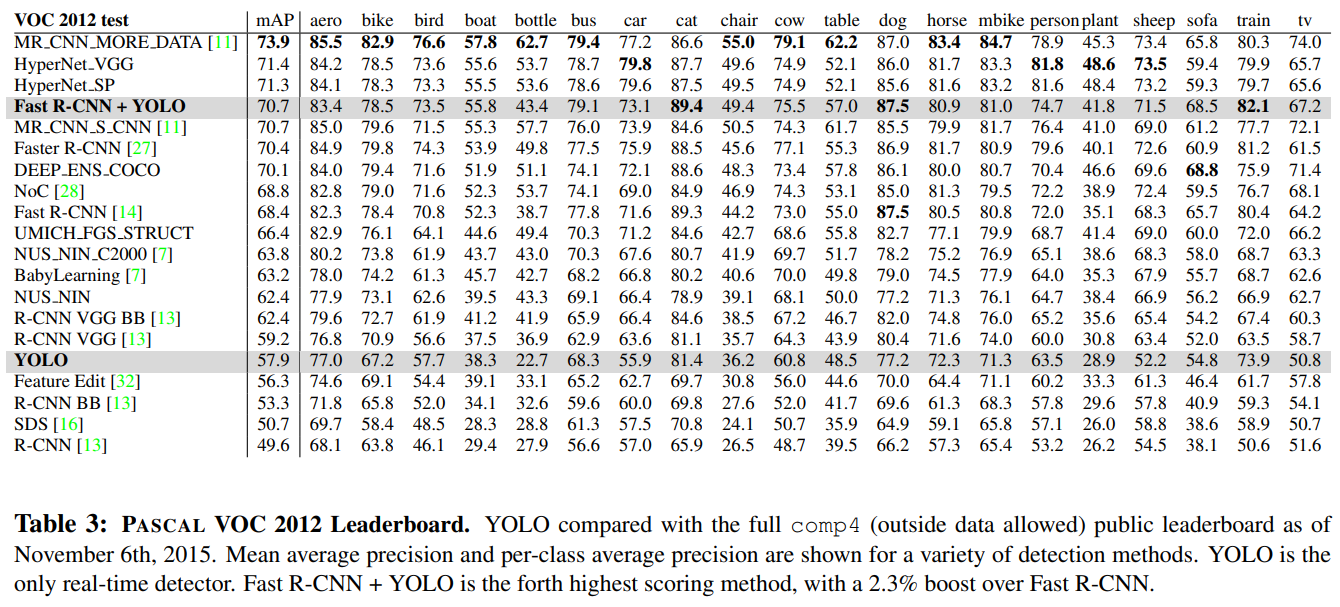
4.4 VOC 2012 Results
VOC 2012 테스트셋에서:
- YOLO 단독: 57.9% mAP
- 작은 객체(bottle, sheep, tv/monitor)에서는 성능이 낮음
- 큰 객체(cat, train)에서는 오히려 더 높은 성능
Fast R-CNN + YOLO 결합 모델:
- Fast R-CNN 대비 2.3% mAP 향상
- 공개 리더보드에서 5단계 상승
YOLO는 단독 성능보다 결합 시 진가를 발휘한다.
4.5 Generalizability: Person Detection in Artwork
현실 환경에서는 훈련 데이터와 테스트 데이터 분포가 다를 수 있음.
이를 검증하기 위해 예술 작품 데이터셋(Picasso, People-Art)에서 실험을 수행한다.
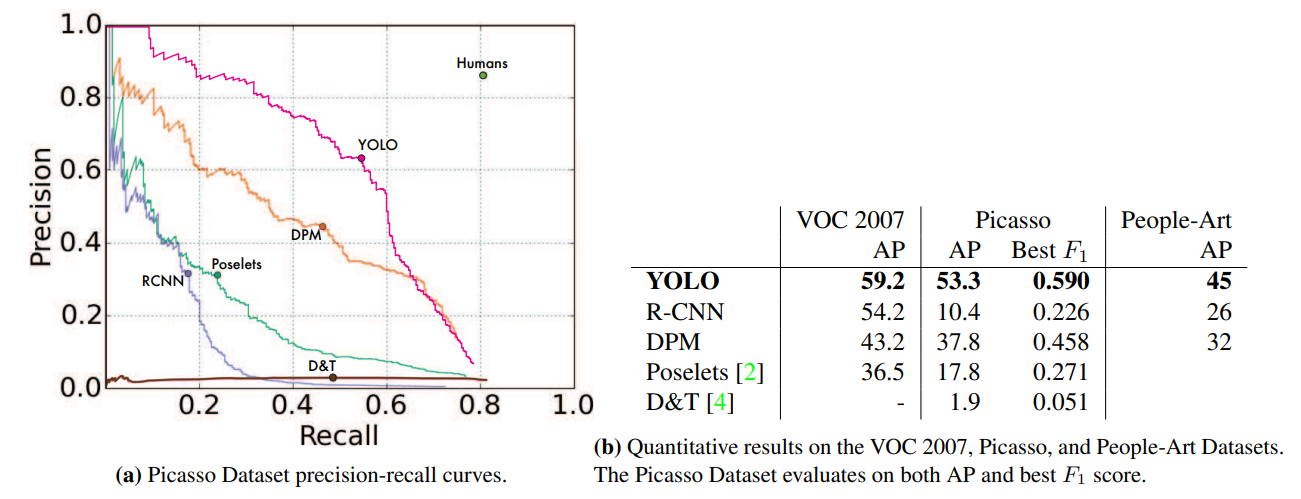
결과 요약:
- R-CNN: 자연 이미지에서는 강하지만 예술 작품에서는 성능 급락
- DPM: 성능 감소는 적지만 초기 정확도가 낮음
- YOLO:
- 자연 이미지에서도 성능이 높고
- 예술 작품에서도 성능 감소가 가장 적음
이유:
- YOLO는 픽셀 정보뿐 아니라
- 객체의 크기, 형태, 배치 관계까지 학습
- 예술 작품과 자연 이미지는 픽셀은 다르지만
- 객체의 구조적 특성은 유사함
YOLO는 새로운 도메인에 대한 일반화 성능이 뛰어남.
5. Real-Time Detection In The Wild

YOLO를 웹캠에 연결한 실험에서도:
- 이미지 입력, 추론, 시각화까지 포함해도 실시간 성능 유지
- 객체 이동에 따라 지속적으로 검출되어 트래킹처럼 동작
실제 응용 환경에서도 즉시 사용 가능한 모델임을 입증한다.
6. Conclusion
YOLO는 객체 검출을 단일 통합 모델(unified model) 로 해결한 최초의 접근이다.
핵심 정리:
- 전체 이미지를 입력으로 받아 End-to-End 학습
- 탐지 성능과 직접 연결된 loss로 학습
- Fast YOLO는 가장 빠른 범용 객체 검출기
- YOLO는 실시간 객체 검출의 새로운 기준을 제시
- 새로운 도메인에서도 강건하여 실제 응용에 적합
