
논문 정보
- Title: Histograms of Oriented Gradients for Human detection
- Authors: Navneet Dalal, Bill Triggs
- Conference / Journal: International Conference on Computer Vision & Pattern Recognition (CVPR '05)
- Published Date: 2005.06
- Paper Link: https://inria.hal.science/inria-00548512/document
- Code Review (GitHub): https://github.com/Groovy52/Image-Processing/tree/main/Gradient%20filter
리뷰 배경
- HOG 논문은 딥러닝 이전의 객체 인식(검출)의 시초가 되는 논문으로, Histograms of Oriented Gradients(HOG)라는 통계적 기법에 기반하여 견고한 객체 인식을 위한 feature를 추출한다.
- 해당 논문은 SVM 등의 머신러닝 기법과 접목하여 이전과 다른 괄목할 만한 성능 향상이 있었기 때문에, 딥러닝 기반의 객체 검출 네트워크를 공부하기 전 읽어두면 좋을 논문이라 생각되어 논문 리뷰와 코드 구현을 진행하였다.
사전지식
1. SVM
- SVM(Support Vector Machine): 머신러닝의 지도 학습 알고리즘으로 주로 분류(classification), 회귀(regression), 이상치 탐지(outliers detection)에 사용된다.
분류 문제에 사용된다면, 서로 반대되는 두 클래스의 가장 가까운 데이터 포인트 사이의 마진을 최대화하는 최적의 hyperplane을 찾아 두 클래스를 구분한다.
hyperplane에 가장 가짜이 있는 데이터 포인트들을 support vectors라고 부른다.- 출처:
2. Feature Descriptor
- Feature Descriptor: 이미지나 영상에서 객체를 대표하는 특징(데이터 패턴)들을 수치화하여 표현한 벡터.
원본 이미지의 모든 픽셀 값을 그대로 쓰는 것이 아니라, 각 픽셀 주변의 의미 있는 정보(예: 경계, 방향, 강도 등)를 추출해 그 객체를 특징짓는 숫자 벡터로 변환한 것을 의미한다.
HOG (Histogram of Oriented Gradients)에서의 Feature Descriptor- HOG라는 이름 자체가 "이미지에서 edge와 형태(shape) 정보를 잡아내기 위해 gradient 방향의 분포를 히스토그램 형태로 정리한 feature descriptor"이다.
- 그 외 유명한 descriptor로는 HOG, SIFT, SURF 등이 있다.
Summary
- 본 논문에서는 테스트 케이스로 Linear SVM 기반 사람 검출을 채택해, 강력한 시각적 객체 recognoition을 위한 feature set 문제를 연구한다.
- 기존의 경계(edge) 및 gradient descriptor들보다 HOG(Histograms of Oriented Gradient) descriptor의 grid가 사람 검출에서 훨씬 우수한 성능을 보임을 실험적으로 보여준다.
- 각 스케일의 성능 계산에 대한 영향은 fine-scale gradients, fine orientation binning, 상대적으로 덜 미세한;거친(coarse) spatial binning 및 겹치는 descriptor block의 고품질 로컬 대비 정규화가 모두 좋은 결과를 위해 중요하다
- 이 새로운 접근법은 기존의 MIT 보행자 database와 거의 완벽하게 분리된다.
- 그래서 다양한 자세 변형과 배경을 가진 1800개 이상의 주석이 달린 human images가 포함된 보다 까다로운 dataset를 도입한다.
1. Motivation
기존 방법론의 한계는 무엇인가?
- 사람은 포즈나 외형이 다양하고, 배경이나 조명 상황도 복잡해서 단순한 feature로는 robust하게 검출하기 어렵다.
왜 이 문제를 해결해야 하는가?
- 기존 feature (예: wavelets)보다 HOG가 우수하다는 점을 실험적으로 입증했기 때문에 이 문제는 중요하며,
- 기존 keypoint 기반 방법조차도 본 연구의 방식보다 오탐률이 최소 1~2배 이상 높을 가능성이 있다.
이 논문이 제안한 해결 방법의 필요성은?
- 기존 descriptor들(SIFT, shape contexts 등)과는 달리 HOG 의 경우, 균일하게 간격이 있는 셀의 조밀한 그리드에서 계산되고 성능 향상을 위해 중첩된 local contrast normalizations를 사용해 훨씬 더 강력하다.
- HOG는 조명 변화, 위치 변화에 강인하고, 사람 형태처럼 국소 구조가 중요한 경우 특히 적합하다.
2. Data Sets and Methodology
(논문 4. Data Sets and Methodology)
Datasets.
-
첫 번째는 MIT 보행자(pedestrian) 데이터베이스로, 도시 풍경 속 보행자의 509개 훈련 이미지와 200개 테스트 이미지(좌우 반사 이미지 포함)를 담고 있다.
- 정면 또는 후면 이미지만 포함되어 있으며 포즈 범위도 비교적 제한적이다.
- 본 연구 방법은 이 데이터 세트에서 거의 완벽한 결과를 보여주었기 때문에, 훨씬 더 까다로운 새로운 데이터 세트인 'INRIA'를 제작해 추가적으로 실험했다.
-
두번째는 INRIA 데이터 베이스로, 다양한 개인 사진에서 잘라낸 1805개의 64×128 크기 사람 이미지로 구성되어 있다.
-
Figure. 2는 몇 가지 샘플을 보여준다.
 [그림 2. 이미지의 객체들은 항상 똑바로 선 자세로, 일부 객체 폐색(occlusions)을 갖고 있다. 포즈와 외형, 옷, 조명, 배경의 다양성을 가진다.]
[그림 2. 이미지의 객체들은 항상 똑바로 선 자세로, 일부 객체 폐색(occlusions)을 갖고 있다. 포즈와 외형, 옷, 조명, 배경의 다양성을 가진다.]
Methodology.
- Training positive & negative set
- 1239개의 이미지를 양성(positive) 훈련 샘플로 선택했으며, 여기에 해당 이미지의 좌우 반전된 버전을 추가하여 총 2478장의 이미지를 확보했다.
- 또한, 1218개의 사람 없는(person-free) 훈련 이미지에서 무작위로 샘플링된 12180개의 패치를 고정된 세트로 구성하여 초기 음성(negative) 세트를 제공하였다.
- 각 detector와 파라미터 조합에 대해 preliminary detector를 학습시키고, 위의 1218개의 음성 훈련 이미지들을 거짓 양성(false positives)을 찾기 위해 철저히 탐색하여 ‘어려운 예제(hard examples)’를 수집한다.
- 그런 다음 이 보강된 데이터 세트(초기 12180개 + hard examples)를 이용해 탐지기를 다시 학습(re-train)시켜 final detector를 생성한다.
- 성능 평가
- detector의 성능을 정량화하기 위해 로그-로그(log-log) 스케일에서 Detection Error Tradeoff (DET) 곡선을 계산하였다.
- miss rate (1 - Recall = FalseNeg / (TruePos + FalseNeg)) 대 FPPW (False Positives Per Window)를 나타낸다. 값이 낮을수록 좋다.
- DET 곡선은 NIST 평가에서 광범위하게 사용되며, ROC(Receiver Operating Characteristics) 곡선과 동일한 정보를 제공하지만, 작은 확률값의 구분을 더 용이하게 해준다.
3. Core Idea
(논문 3. Overview of the Method)
- 본 방법은 밀도가 높은 그리드에서 이미지 gradient 방향의 잘 정규화된 local histogram을 평가하는 데 기반한다.
- 기본 아이디어는 local object의 appearance과 shape이 해당 gradient나 edge 위치에 대한 정확한 지식이 없어도 local intensity gradients 또는 edge 방향의 분포에 의해 다소 잘 특성화 될 수 있다는 것이다.
- 실제로는 이미지 window를 작은 공간 영역("cells")으로 나누고, 각 cell에 대해 cell의 pixel에 걸쳐 gradient 방향 또는 edge 방향의 local 1차원 histogram을 누적한다.
=> 이러한 histogram 항목들을 결합하여 표현을 생성한다. - 조명, 그림자 등에 대한 불변성을 높이기 위해 local response를 사용하기 전에 contrast-normalize하는 것도 유용하다.
- 이것은 다소 큰 공간 영역("blocks")에 걸쳐 local histogram "energy" 측정값을 누적하고, 그 결과를 사용하여 block 내의 모든 셀을 정규화함으로써 수행한다.
- 정규화된 descriptor block들을 방 Histogram of Oriented Gradient (HOG) descriptors라고 부른다.
- detection window를 HOG descriptors의 밀도가 높은(실제로는 겹치는) grid로 tiling(타일링;이어붙이기)하고 기존의 SVM 기반 window classifier에서 결합된 feature 벡터를 사용한다.
Figure. 1은 위 과정을 도식화한 그림이다.
 [그림 1. feature extraction 과 object detection chaing에 대한 개요. detector window는 겹치는 블록들의 grid로 이루어져 있으며, 이 grid에서 HOG 특징 벡터가 추출된다. 추출된 벡터들을 결합하여 객체/비객체 분류를 위해 linear SVM에 입력된다. detection window는 이미지의 모든 위치와 크기에서 스캔되며, 출력 피라미드에 기존의 전통적인 NMS를 적용하여 객체 인스턴스를 검출한다. 하지만 본 논문에서는 feature 과정에 초점을 맞춘다.]
[그림 1. feature extraction 과 object detection chaing에 대한 개요. detector window는 겹치는 블록들의 grid로 이루어져 있으며, 이 grid에서 HOG 특징 벡터가 추출된다. 추출된 벡터들을 결합하여 객체/비객체 분류를 위해 linear SVM에 입력된다. detection window는 이미지의 모든 위치와 크기에서 스캔되며, 출력 피라미드에 기존의 전통적인 NMS를 적용하여 객체 인스턴스를 검출한다. 하지만 본 논문에서는 feature 과정에 초점을 맞춘다.]
Figure. 1의 각 단계에 대한 자세한 설명은 아래와 같다.
0. 실험 기본(default) 설정
- 감마 보정이 없는 RGB 색상 공간;
- 스무딩 없는 [−1, 0, 1] 그래디언트 필터;
- 0°–180° 범위에서 9개의 방향(bin)으로 선형 그래디언트 투표(linear gradient voting);
- 4개의 8×8 픽셀 셀로 구성된 16×16 픽셀 블록;
- σ = 8 픽셀의 가우시안 공간 윈도우(Gaussian spatial window);
- L2-Hys (Lowe 스타일의 클리핑된 L2 노름) 블록 정규화(block normalization);
- 블록 간격(stride)은 8 픽셀 (따라서 각 셀은 4배 중첩 커버됨);
- 64×128 검출 윈도우(detection window);
- 선형 SVM 분류기(linear SVM classifier).
1. Gamma/Colour Normalization
(논문 6. Implementation and Performance Study)
이미지 밝기를 조절하는 일종의 전처리 단계로 보여진다.
grayscale, RGB, LAB 색공간 및 감마 보정을 포함한 다양한 입력 픽셀 표현들을 실험했다.
-
이 보정들은 일반적으로 성능에 큰 영향을 미치지 않았으며, 주로 이후에 적용되는 descriptor 정규화가 효과를 발휘하기 때문으로 보인다.
-
RGB와 LAB 색상 공간은 비슷한 결과를 보였지만, grayscale로 제한하면 성능이 10⁻⁴ FPPW에서 1.5% 감소한다.
-
각 색상 채널에 대한 제곱근 감마 압축(Square root gamma compression)은 낮은 FPPW에서 성능을 향상시킨다 (10⁻⁴ FPPW에서 1% 향상), 그러나 로그 압축은 너무 강력하여 10⁻⁴ FPPW에서 성능을 2% 악화시킨다.
-
감마 보정의 목적
- 사람의 눈은 밝기를 선형적으로 인식하지 않고 비선형적으로 인식
- 카메라 센서는 빛을 선형적으로 측정하지만, 사람의 지각(시각) 은 비선형
- 이 둘을 맞추기 위해, 입력 값과 출력 값의 관계를 비선형(power‑law)로 만들어 주는 수식이 아래 수식임.
-
수식
- : 입력 밝기 또는 픽셀 값
- : 감마 보정된 출력 값
- : 스케일 계수 (보통 1로 설정)
- : 감마 지수 (보정 정도 조절)
 [좌, 우: 감마보정을 적용한 이미지, 가운데: 감마보정을 적용하지 않은 원본 이미지]
[좌, 우: 감마보정을 적용한 이미지, 가운데: 감마보정을 적용하지 않은 원본 이미지]
2. Gradient Computation
Gradient(기울기) 는 이미지에서 픽셀 밝기 변화의 방향과 크기를 나타낸다.
보통 한 픽셀에서 수평(x) 과 수직(y) 방향으로 밝기가 어떻게 변하는지를 계산한다.
- 먼저 가우시안 스무딩을 한 후 여러 이산 미분 마스크 중 하나를 사용하여 계산된 그래디언트를 테스트했다.
- 가우시안 스무딩: 노이즈를 줄이기 위해 이미지에 blur를 주는 처리.
- 논문에서는 σ=0 (즉 스무딩 없음) 부터 σ=2까지 여러 스케일을 실험했는데, σ=0 (스무딩 없음)이 가장 좋은 성능을 나타냈고, σ=2로 스무딩을 키우자 recall이 89%로 떨어졌다. (HOG는 세밀한 edge 구조를 캐치하는 것이 중요하기 때문에, 스무딩을 하면 이런 미세 edge 정보가 희석되어 성능이 떨어진 것으로 분석)
- 테스트된 마스크에는 다양한 1차원 포인트 미분 필터(비중심형 [-1, 1], 중심형 [-1, 0, 1], 그리고 3차 보정된 [-1, 8, 0, 8, -1])뿐 아니라 3×3 소벨 마스크, 그리고 2×2 대각 마스크가 포함되었다.
- 그중 가장 간단한 1 dimension [−1, 0, 1] masks at σ=0가 가장 뛰어난 성능을 보였으며 오히려 필터의 크기가 커질 수록 성능이 저하되었다.
- 컬러 이미지의 경우, 우리는 각 색상 채널에 대해 개별적으로 그래디언트를 계산하고, 노름(norm)이 가장 큰 것을 해당 픽셀의 그래디언트 벡터로 사용했다.
Computation 1: Gradient 계산
- 2차원 자료구조인 영상에서는 x 방향, y 방향으로 나누어 각각 미분식을 적용해 주면 되는데, 본 논문에서 가장 좋은 성능을 거둔 중심형 필터 [-1, 0, 1]의 적용 방법은 아래 이미지와 같다.
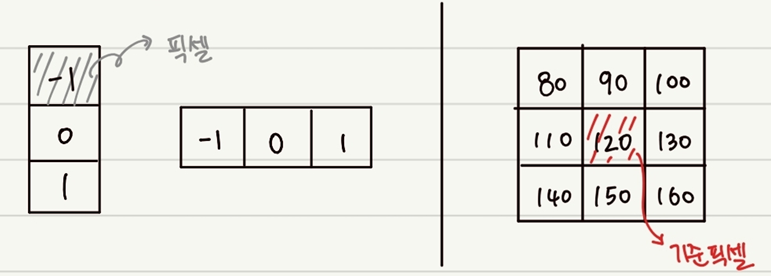 [좌: y방향 계산용 커널, x방향 계산용커널, 우: 3x3 이미지]
[좌: y방향 계산용 커널, x방향 계산용커널, 우: 3x3 이미지]
Computation 2: Gradient 계산값에 대한 Magnitude, Orientation 계산
Magnitude
- 그래디언트의 크기(magnitude)는 각 방향에 대한 증분의 Euclidian distance로 정의한다.
Orientation
-
Orientation은 각 증분이 이루는 각을 arctan라는 삼각함수를 이용하여 계산한다.
-
수식 인자
- : 각각 x 방향, y 방향 밝기 변화
- : 밝기 변화의 강도
- : 변화 방향(orientation)
3. Spatial / Orientation Binning
이미지의 각 점에서 가장자리의 방향을 확인한 다음, 비슷한 방향끼리 묶어서 정리하는 단계.
예를 들어, 왼쪽 위에서 오른쪽 아래로 기울어진 선이 있으면 그건 ‘45도 방향’에 해당
- 이미지의 각 픽셀은 해당 위치에 중심을 둔 그래디언트 방향에 따라 히스토그램 채널에 가중치 투표를 한다.
- 이 투표들은 우리가 '셀(cells)'이라 부르는 지역적 공간 영역들 내에서 방향 bin들에 누적된다.
- 셀은 직사각형(rectangular)일 수도 있고, 방사형(radial)(로그-극 부채꼴)일 수도 있다.
- 이미지를 8x8 같은 작은 블록으로 나누고, 그 안에서 히스토그램을 만든다.
- 방향 bin들은 0°–180° 범위(‘부호 없는’ 그래디언트) 또는 0°–360° 범위(‘부호 있는’ 그래디언트)로 고르게 나뉘어 있다.
- 방향을 20도씩 나눠서 9칸을 만들고, 픽셀들은 자신이 속한 방향에 투표한다.
- aliasing을 줄이기 위해, 방향과 위치 양쪽에서 이웃하는 bin 중심들 사이에 대해 투표는 이중선형 보간(bilinear interpolation)된다.
- 투표는 픽셀에서의 그래디언트 크기의 함수이며, 이는 크기 자체이거나, 그 제곱, 혹은 제곱근이다. 또는 픽셀에서의 에지(edge)의 유무를 부드럽게 나타내는 잘린(clipped) 형태일 수 있다.
- 실제로는, 그래디언트 크기 자체를 사용하는 것이 가장 좋은 결과를 냈다(제곱근 취할 시-> 성능 다소 감소, binary edge presence voting 시 -> 10⁻⁴ FPPW에서 5% 감소)
 [8x8 셀 내의 Histogram of Gradients 계산]
[8x8 셀 내의 Histogram of Gradients 계산]
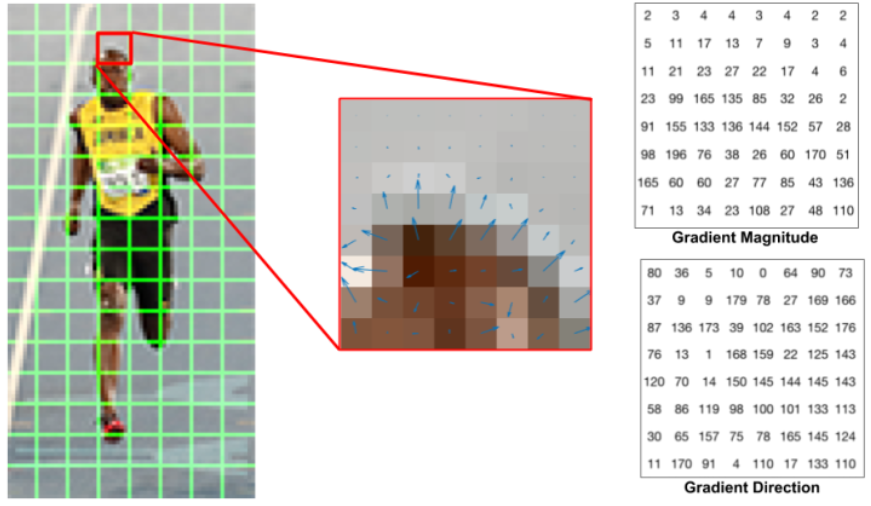 [화살표를 사용하여 나타낸 RGB 패치와 그래디언트]
[화살표를 사용하여 나타낸 RGB 패치와 그래디언트]
- Gradient Magnitude는 방향 강도, Direction은 방향 각도 정보를 나타냄
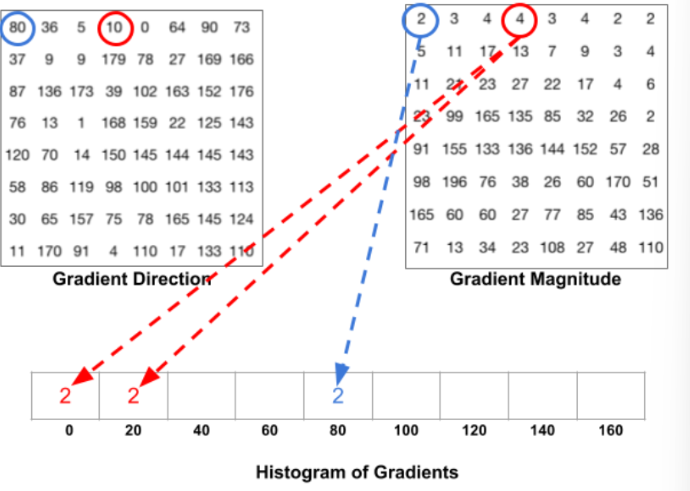 [Voting과 히스토그램을 만드는 과정]
[Voting과 히스토그램을 만드는 과정]
- 빈은 방향에 따라 선택되고 vote(빈에 들어가는 값)는 크기를 기반으로 선택된다.
- 위 이미지의 파란색 원에 해당하는 픽셀은 방향(direction)이 80도이고, 크기(magnitude)가 2임.
- 따라서 9개의 균등한 빈으로 나눠진 것들 중 5번째 빈: 80 칸에 2를 추가함.
- 같은 방식으로 빨간색 원에 해당하는 픽셀은 방향값이 10인데, 이는 9개의 균등한 빈 중 어느 것에도 속하지 않고, 0과 20에 중간이므로 그 크이니 4를 0과 20의 두개의 균등한 빈으로 나눔.
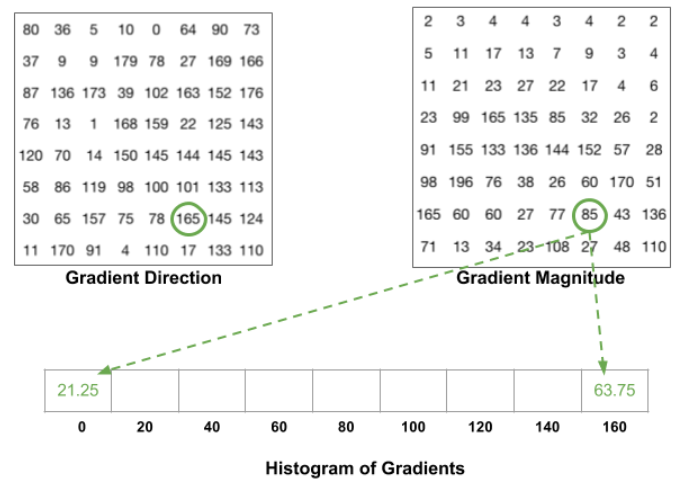 [8x8 셀 내의 모든 픽셀의 방향에 따른 크기 값을 누적 합산하여 만든 히스토그램 결과값]
[8x8 셀 내의 모든 픽셀의 방향에 따른 크기 값을 누적 합산하여 만든 히스토그램 결과값]
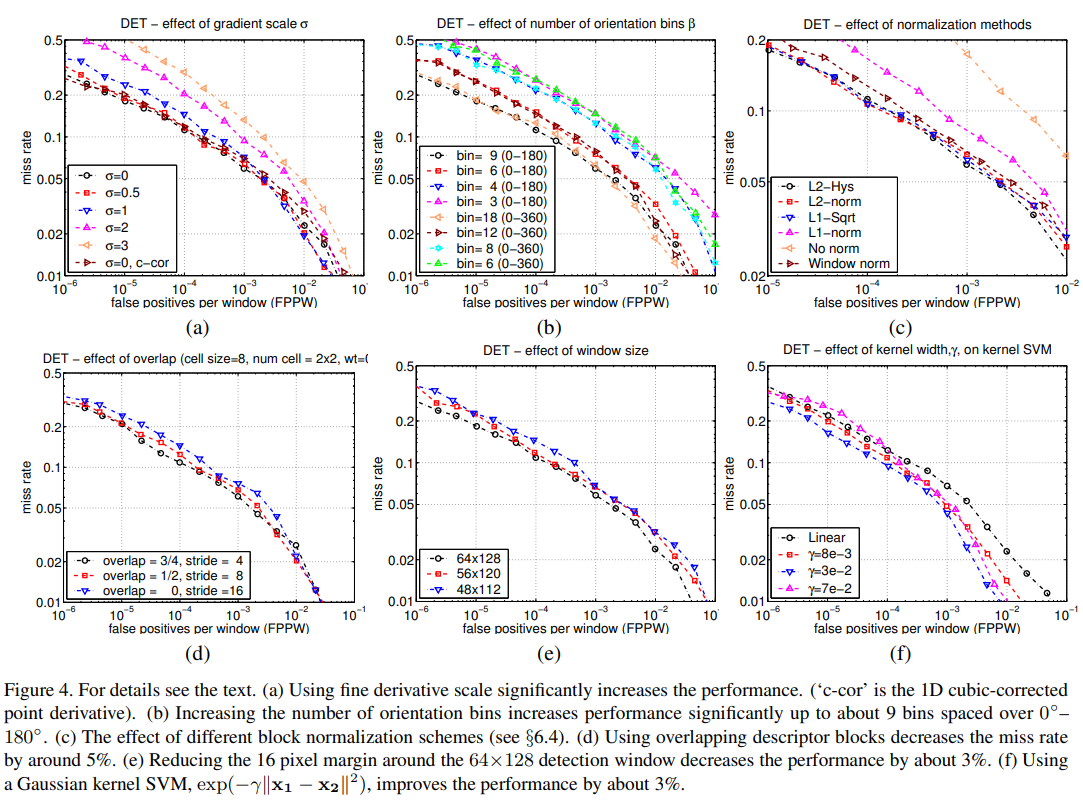
- 그림 4(b)가 보여주듯, 방향 bin의 개수를 약 9개까지 늘리면 성능이 유의미하게 향상되었지만, 이 이상에서는 성능 향상 효과가 거의 없었다. (이는 0°–180° 범위로 나뉜 bin에 대한 것이며, 즉 그래디언트의 ‘부호’는 무시된다.
=>사람의 경우, 의복과 배경 색상의 다양한 범위 때문에 대조의 부호가 유의미하지 않게 되는 것으로 보인다.그러나 부호 정보를 포함시키는 것은 자동차나 오토바이 같은 다른 객체 인식 과제들에서는 상당히 유용하다.
4. Normalization and Descriptor Blocks
- 국지적인 명암 차이(조명, 배경 등)에 따라 그래디언트 세기가 크게 달라질 수 있기 때문에, 이를 정규화(normaㄴlization)하여 일정하게 맞추는 것이 매우 중요하다.**
- 일반적으로는 여러 셀을 하나의 블록으로 묶고, 이 블록 내에서 정규화를 수행한다.
- 셀들은 겹쳐진 블록들에 포함되도록 구성되며, 겹침(overlap)은 성능 향상에 도움이 된다.**
- 우리는 R-HOG (직사각형 블록)과 C-HOG (원형 블록) 두 가지 형태를 평가했으며, R-HOG가 일반적으로 더 우수한 성능을 보였다.**
- 성능이 가장 좋았던 구성은: 3×3 블록, 각 셀이 6×6 픽셀, 방향 히스토그램 9개.
- 정규화 방식 중 L2-Hys, L2-norm, L1-sqrt 모두 좋은 성능을 보였고, 단순 L1-norm이나 정규화 생략은 성능을 많이 떨어뜨림.
5. Detector Window and Context
- 사람을 검출하기 위한 창(window)은 보통 64×128 픽셀로 설정되며, 이는 사람 주위에 16픽셀 여유 공간(margin)을 포함.
- 또한, 블록이 겹치며 정규화되는 구조 덕분에, 특정 셀(예: 머리, 발 위치)의 변화량이 상대적인 다른 블록에 의해 측정되며, 이게 사람을 구별하는 데 효과적.
작성 시 참고한 사이트 링크:
- https://hohodu.tistory.com/entry/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Histograms-of-Oriented-Gradients-for-Human-Detection
- https://m.blog.naver.com/koreadeep/222588894193
- https://velog.io/@pabiya/Histograms-of-Oriented-Gradients-for-Human-Detection
- https://studyingfox.tistory.com/5
- https://blog.naver.com/tommybee/221173056260
