Epoch(에폭)
전체 데이터가 모두 학습한 단위
Ex) 60,000개의 데이터를 모두 학습 → 1Epoch
30Epoch = 60,000개의 데이터에 대하여 30번 학습
Loss(Error)
정답값과의 오차
낮을수록 좋음
Accuracy(acc)
정확도
Supervised Learning
- 지도 학습 : 입/출력 데이터가 존재
- 분류 Classification (시험 중 2, 3, 4번)
- 사람/사물 분류
- 스팸 메일 분류
- 지문, 홍채 인식 판별 - 회귀Regression (시험 중 1, 5번)
- 연속된 수치 예측
- 부동산/주식 가격 예측
- 출산 인구 예측
- 분류 Classification (시험 중 2, 3, 4번)
- 비지도 학습
- 입력 데이터만 존재
- 군집 Clustering
- 입력 데이터만 존재
Input/Output Data
Input Data = X = Features
Output Data = Y = Labels
딥러닝 학습 순서
- import: 필요한 모듈(라이브러리)를 import
- 전처리: 학습에 필요한 데이터 전처리를 수행
- 모델링(model): 모델 정의 = Sequential을 통해 (함수형 모델링은 Functional)
- 컴파일(compild): 모델 생성 = optimizer, loss ...
- 학습(fit): 모델 학습 (X, Y data를 넣어서...)
--- 예측(predict): 구글 채점 서버가... 할 예정
선형함수와 오차
y = w * x + b
x = input data, y = output data, w = weight, b = bias
손실함수 Loss Function
오차의 총합 = y예측값 - (y실제값)
y예측값 = w * x + b = (wx + b) - (y실제값)
- 단순 오차의 총합은 우연히 0이 나올 수 있기 때문에 문제가 있다.
- MAE(Mean Absolute Error) 오차 절대값 평균
- MSE(Mean Squared Error) 오차 제곱 평균
Dense Layer (Fully Connected Layer=FC)
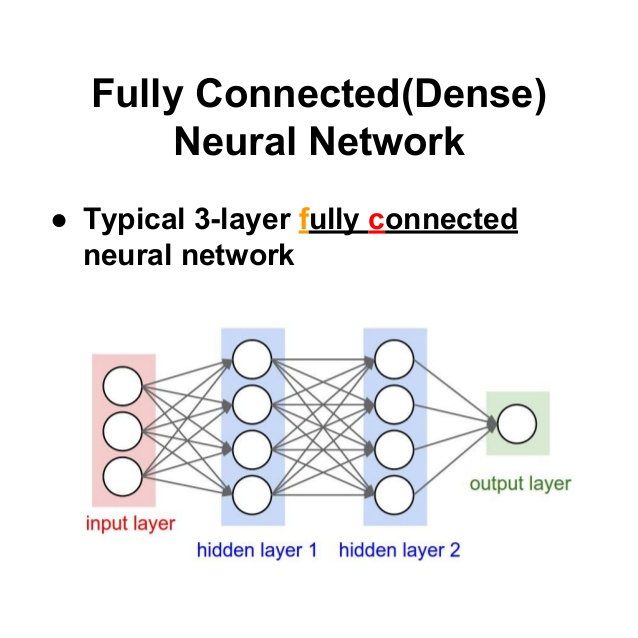
-
노드(뉴론)가 완전히 연결되어 있음
-
각각의 노드가 가중치를 갖고 있음
-
input layer는 data가 어떻게 들어오는지 모른다.
따라서, input_shape를 지정해주어야 함. → 데이터가 어떤 모양인지 지정 -
output layer는 결과값
과대 적합 (over-fitting)과 과소 적합 (under-fitting)

- 과대 적합 over-fitting : sample에 모델이 과하게 적합되어 있는 상태 (train set의 acc는 높지만, 실제 적용시 acc가 크게 감소한다)
- 과소 적합 under-fitting : train set의 패턴을 모두 잡아내지 못하는 상태 (모델 성능이 낮다)
- 우리가 바라는 것은 실제 데이터를 적용했을 때 예측 성능이 좋은 것! (80~90%)
Model Checkpoint
Validation loss가 감소할 때의 weight 값을 저장해둠... → my_checkpoint.ckpt
가장 좋은 성적이 나왔던 모델을 저장할 수 있도록 해준다.
# 모델 체크 포인트 만드는 법
checkpoint_path = "my_checkpoint.ckpt" # 파일명
checkpoint = ModelCheckpoint(filepath = checkpoint_path, # 저장 파일 경로
save_weights+only = True, # 가중치만 저장
save_best_only = True, # False면 모든 epoch마다 다 저장함
monitor = 'val_loss', # best model을 정할 기준
verbse = 1) # 로그 출력 여부 (1: 출력, 0: 미출력)# 모델 적용법
history = model.fit(x_train, y_train,
validation_data = (x_valid, y_valid),
epochs = 20,
callbacks = [checkpoint], # list 형태로 callback을 넣을 수 있음
)# checkpoint를 저장한 파일을 load 해야 한다!!! 중요!! (자동 load 안됨)
# 학습 종료(model.fit) 후 해당 코드 필수
model.load_weights(checkpoint_path)이미지 데이터 전처리
정규화 Normalization
-
모든 픽셀값을 0~1으로 정의한다(최대값으로 나눠서!) = Normalization
-
데이터가 얼마나 넓게 퍼져 있는지... = 분산
-
정규화는 이 분산값을 줄여서 학습 수렴의 속도를 빠르게 만든다. = 성능 향상
-
무조건적으로 정규화 하는 것은 위험하므로 데이터를 살펴야 한다...
하지만 이미지는! 정규화 해도 됨!
원핫인코딩 One Hot Encoding
각각 값에 대한 컬럼을 만들어준 다음, data에 해당하는 값만 1로 두고 나머지는 0으로 채운다.
활성함수 Activation function
선형함수만 층을 쌓으면 선형×선형=선형관계 라서... 층을 깊게 하는 의미가 줄어든다.
복잡한 문제를 풀기 위한 딥러닝의 의미가 퇴색.
∴ 선형함수 사이에 선형이 아닌 함수를 끼워넣게 된다!! → 이것이 바로 활성함수
선형×비선형×선형관계가 되면 좀더 복잡한 문제를 풀 수 있다.
- Dense = 선형함수
- relu
- sigmoid = y값이 무조건 0~1
- softmax = 모든 애들을 합치면 1
tf 시험에서 분류 문제를 풀 때 중간에는 relu, 마지막에는 sigmoid/softmax을 사용
이진 분류 vs 다중 분류
- 이진 분류: 2개의 클래스를 분류하는 문제
- 다중 분류: 3개 이상의 클래스를 분류하는 문제

정형 데이터 분류기
feature 데이터로 4개
텐서 플로우 data sets 호출
import tensorflow_datasets as tfdsBatch 와 Batch Size
default = 32
모델들이 학습을 하며 가중치를 조정...
이 가중치의 update 시점 = 1개의 Batch가 끝나는 시점
한 번에 학습할 수 없으므로, 학습 단위를 쪼갠다... => Batch를 만든다 = group을 만듦
ex)
10,000장의 data를 100장씩 묶었을 경우
Batch Size = 100장, Batch = 100개, 가중치 update = 100번
10,000장의 data를 200장씩 묶었을 경우
Batch Size = 200장, Batch = 50개, 가중치 update = 50번
Batch Size, Batch에 따라 가중치 update 횟수가 달라진다. (1 Epoch당)
Batch Size가 너무 작으면 느리다.
Batch Size가 너무 크면 속도는 빠르지만, out-off-memory 오류가 발생하거나 정교하게 도달하지 못하고 gap이 생길 수 있다.
→ 모델의 성능이 달라질 수 있다!
이미지 분류 (3번 문제)
Type A (Image Data Generator)
Image Augmentation (이미지 변형)
각도를 틀 거나 좌우 이동, 굴절, Zoom In/Out 등 학습 데이터에 변형을 주어 모델이 다양한 학습 데이터를 학습할 수 있도록 한다.
training_datagen = ImageDataGenerator(
rescale = 1. / 255, # 이미지 픽셀 값 조정
rotation_range = 40, # 1보다 큰 숫자라면 0도부터 40도 사이에 랜덤한 각도로 회전
width_shift_range = 0.2, # 0.2 = 20%, 똑같이 0~20% 사이 랜덤한 이동
height_shift_range = 0.2,
shear_range = 0.2, # 이미지 굴절
zoom_range = 0.2, # 이미지 확대
horizontal_flip = True, # 횡방향 이미지 반전
fill_mode = 'nearest', # 가장 근처에 있는 픽셀들로 채우기
validation_split = 0.2, # 가위바위보(rps) 할 때 씀... 주로 train set 밖에 없을 때! 0.2=20% 는 검증 set, 나머지 80%는 train set으로 간다
)flow_from_directory
로컬에 .png, .jpg 등등... array로 변환해서 memory에 올려야 한다.
이 작업을 쉽게 해주는 함수.
- first parameter : 이미지 경로 root
- batch_size : 너무 크면 OOM 발생하므로 값 줄이기
- target_size : 이미지 크기 맞추기... 문제가 지정해줌
- class_mode : Dense(2, 'softmax')면 'categorical', sigmoide 등이면 binary (마지막 층 보고 정하기)
- subset : 'training'/'validation' < validation_split 지정했을 때만 지정.
합성곱 신경망 Convolutaion Nenural Network
feature(들어오는 데이터)에 대한 특성 추출... (이렇게 추출된 data를 feature map이라고 함)
특성 추출 후 연산(Dense) 하게 됨...
Dense Layer = 모든 Node가 완벽히 연결되어 있음
But, 그러다 보면 정보와 무관한 background 등... 을 함께 추출+연산해야 해서 연산량과 속도가 증가함
→ Localization(지역 특성)을 먼저 추출한 뒤 연산
filter 갯수를 지정할 수 있음 => 서로 다른 feature map이 30개
→ filter의 값은 랜덤하게 다르기 때문에
Conv2D(필터의 갯수, (필터사이즈), activation='relu')Pooling Layer
이미지 사이즈를 줄여주는 레이어 → 연산량이 획기적으로 줄어듬
MaxPooling2D(Max값뽑을범위)output size는 1/4으로 줄어든다
AvgPooling2D(평균..)Pooling Layer는 보통 CNN과 함께 MaxPooling이 많이 사용됨
CNN+MaxPooling 후에는... 아직 2D로 구성되어 있기 때문에 Flatten()을 통해 1D 데이터로 변환시켜야 한다.
- Dropout(0.5) : 과대적합 방지용. 학습할 때만 동작. 0.5=50%만 학습하게 된다.
Train/Validation Set이 각각 나뉘어져 있을 경우
- train/Validation data set 경로를 각각... 별도로 지정해야 한다.
- IDG의 경우 rescale은 둘 다 적용하는 게 맞음. But, validation은 rescale만!
Type B (cats vs dogs)
tfds 사용하는 문제
전이학습 Transfer Learning
VGG 모델을 활용해서 우리 문제에 맞춰서 튜닝하는 것.
위의 장점을 살리고 우리 분류기 성능을 좋게 한다.
같은 구조라도 얼마나 학습했느냐에 따라 성능 달라짐
∴ 전이학습은 얘네가 학습한 가중치까지 가지고 온다. (= 성능향상)
자연어 처리 NLP
Sarcasm 데이터 셋
article_link = 신문기사 링크
headline = 기사 제목
is_sarcastic
비꼬는 기사인지 아닌지 판별하는... 2진 분류 문제
headline만 보고 파악 (atricle_link에 들어가 직접 기사를 긁어오면 좀 더 정확)
언어의 전처리
- 토큰화
문장을 수치화 하기 위해 선행되어야 하는 과정.
방법...
1. 문장 단위로 자르기
2. 단어 단위로 자르기
3. 알파벳 단위로 자르기
여기서는 단어 단위로 token화
방법
1. 단어 사전 만들기 : 단어 사전? index 매칭
2. 치환하기 : 단어 사전에 근간하여 치환
3. 길이 맞추기 : 기준이 되는 길이가 있어야 함... 보다 짧은 문장은 0으로 채우고 보다 긴 문장은 잘라냄
순환 신경망 Recurrent Neural Network
순차적으로 가중치 계산, 결과 계산, 가중치가 다음으로 전달됨
이렇게 순서를 반영한 것을 RNN이라고 부른다
가장 초기 버전 = Vanilla RNN
Vanishing / Exploding Gradient 문제가 발생
굉장히 긴 문장이 있을 때, 순차적으로 진행할 수록 주어 등의 중요도가 점점 낮아진다... (Gradient 소실 문제)
LSTM (Long Short Term Memory)
중요도가 다음까지 전달된다.
short term은 weight가 점점... 흐려진다.
그래서 중요한 단어는 long term에서 weight를 지켜준다. (중요하지 않다 싶으면 지울 수도 있음)
many to one (4번 문제)
문장(sequence)을 통해 단일 결과 예측
시리즈가 들어가서 단일이 나옴
리뷰 긍정/부정 평가 등
# many to one
tf.keras.layers.LSTM(64)many to many (5번 문제, 시계열/시퀀스 데이터)
문장(sequence)을 통해 시퀀스(sequence) 예측
시리즈가 들어가서 시리즈가 나옴
문장을 통한 다음 문장 예측
과거 20일 주가 데이터로 미래 20일 주가 예측
# many to many
tf.keras.layers.LSTM(64, return_sequences=True)return_sequences=True란 각각에 대한 weight를 return해다오
결과값이 many로 나오게 된다~
LSTM 레이어를 겹쳐서 사용할 땐 반드시 겹치는 부분에 return_sequences=True 옵션을 주어야 한다.
Bidirectional Layer
단어를 순서대로 읽으면 예측이 어려울 수 있다.
But 뒤에서 읽으면?! 후보군이 많이 줄어든다.
예측 방향에 따라서(앞/뒤) 상황이 달라질 수 있음...
이를 노려서 양방향 예측을 하는 것이 Bidirectional Layer!!
별도로 사용하는 게 아니라
Bidirectional(LSTM(32))이렇게 묶어서 사용한다~
위의 경우 앞에서 32개 뒤에서 32개로 총 64개가 추출됨
Sequences(sunspots) 와 시계열 Time Series
태양의 흑점 주기를 예측하는 회귀 문제
# Lambda : 간단한 연산을 마지막 값에 적용해보고 싶을 때 사용
tf.keras.layers.Lambda(lambda x: x * 400) 값이 너무 작게 나왔을 경우 Lambda layer를 통해 확대시켜줄 수 있다. (최적화, 성능 향상)
# 정규화(Normalization)
min = np.min(series)
max = np.max(series)
series -= min
series /= max
time = np.array(time_step)정규화를 해주면 시계열 데이터의 성능이 올라가는 경우가 있다.
이 두 경우는 건들지 않는 게 좋다.
Windowed Dataset
윈도우 계산
window_size = n # n일간의 데이터를 갖고 다음 단일 타겟을 예측
shift = n # n일씩 밀림
얘는 many to many로 계산
drop_remainder = True # 만들 수 있는 데까지만 만들고 stop
buffer_size # shuffle에 대한 buffer... buffer_size 만큼 묶어서 셔플하고 내보내기를 반복
구성방법
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
# series data가 1차원으로 들어왔을 때 2차원으로 확장
series = tf.expand_dims(series, axis = -1)
# data set으로 변환
ds = tf.data.Dataset.from_tensor_slices(series)
# y값 포함하는 범위(window_size+1)까지 잘라야 한다
ds = ds.window(window_size + 1, shift = 1, drop_remainder = True)
# 평평하게...? 위 범위와 w.batch 구성값만 맞춰주기
ds = ds.flat_map(lambda w: w.batch(window_size + 1))
ds = ds.shuffle(shuffle_buffer)
# X 데이터와 Y 데이터 분할
ds = ds.map(lambda w: (w[:-1], w[1:]))
# prefetch(1) : 1개의 배치를 더 만들어준다. --> 학습할 배치가 미리 준비되어 있다. (성능 개선, 속도 향상)
return ds.batch(batch_size).prefetch(1)Convolution 1D Layer
- 시계열 데이터/자연어 처리에 사용
- 합성곱 연산을 통해 진행
- 1차원 데이터에 대한 합성곱 추출
kernel_size # time_step 몇 개씩 확인할지
strides # 얼마나 이동하며 확인할지
padding = 'causal' # 패딩 넣어주기Optimizer 튜닝
Stochastic Gradient Descent (SGD)
경사 하강법. 경사를 타고 내려와 최저점(Loss최저값)에 도달하는 최적화 알고리즘
- learning rate 학습률 : 보폭
적절한 learning rate 는 한 번.. 테스트? 해보기
- Momentum 관성 : 0일 경우, 학습을 진행할 때 Local Minimum Value에 수렴해버린다. (전체 영역에서 최적이 아닌 근처 최적을 찾아버림)
SGD 알고리즘에서는 momentum을 줌 (0~1 사이값), adam 알고리즘은 보통 괜찮음
optimizer = tf.keras.optimizersSGD(lr=0.00001/*러닝레이트*/, momentum=0.9)
model.compile(loss=loss, optimizer=optimizer, metrics=["mae"])튜닝한 optimizer를 compile에 넣어준다
Huber Loss
- L1 loss = MAE loss (절대값 씌운 loss)
- L2 loss = MSE loss (제곱한 loss)
오차가 0에 가까울 수록 MSE(L2)
오차가 0에 멀어질 수록 MAE(L1)
Huber loss는 하이브리드 느낌
특정 임계값 안에는 L2 loss 적용, 임계값 바깥은 L1 loss 적용
