원-핫 인코딩(One-Hot Encoding)
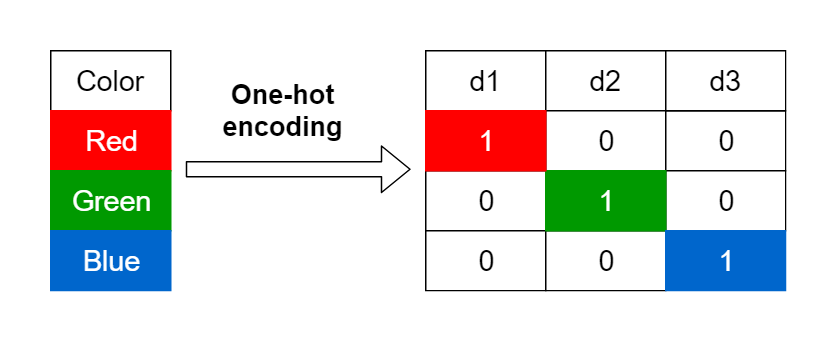
원-핫 인코딩이란? 기계가 문자를 이해할 수 있게끔, 문자를 숫자로 바꿔주는 과정
- 인코딩 과정
- 인코딩 할 문장을 가져오기
!pip install datasets
from datasets import load_dataset
dataset = load_dataset('nsmc')
gen = iter(dataset['train'])- 형태소 분석을 위한 konlpy 설치
import os
import tensorflow as tf
cwd = os.getcwd()
path_mecab_zip = tf.keras.utils.get_file(
'mecab-0.996-ko-0.9.2.tar.gz', origin='https://bitbucket.org/eunjeon/mecab-ko/downloads/mecab-0.996-ko-0.9.2.tar.gz',
extract=True)
path_mecab_dic_zip = tf.keras.utils.get_file(
'mecab-ko-dic-2.1.1-20180720.tar.gz', origin='https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.1.1-20180720.tar.gz',
extract=True)
os.chdir(os.path.join(os.path.dirname(path_mecab_zip),'mecab-0.996-ko-0.9.2/'))
!./configure
!make
!make check
!sudo make install
os.chdir(os.path.join(os.path.dirname(path_mecab_zip), 'mecab-ko-dic-2.1.1-20180720/'))
!sudo ldconfig
!ldconfig -p | grep /usr/local
!./configure
!make
!sudo make install
!pip install mecab-python3
!apt-get update
!apt-get install g++ openjdk-8-jdk python-dev python3
!pip3 install JPype1-py3
!pip3 install konlpy
!JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64"
%cd {cwd}- 원-핫 인코딩 함수 만들기
def one_hot_encoding(tokens : List[str], vocabulary : Dict[str, int], length : int = 10)
base = np.zeros((length, len(vocabulary)))
for i, token in enumerate(tokens):
col = vocabulary.get(token)
if col is not None:
base[i, col] = 1
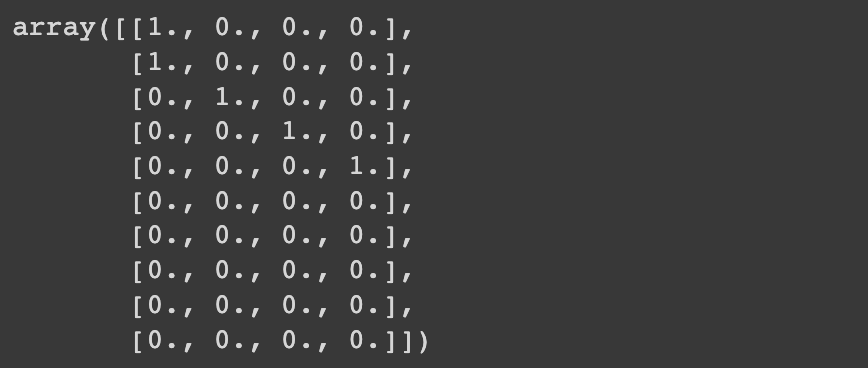
return base- 함수 실행해보기
inp = ['아', '아', '더빙..', '진짜', '짜증나네요', '목소리']
vocab = {'아' : 0, "더빙.." : 1, "진짜" : 2, "짜증나네요" : 3}
one_hot_encoding(inp, vocab, length=10)