그래프 그리기
아래 시각화 라이브러리를 설치합니다.
pip install matplotlib
pip install seabornjupyter notebook 사용시 아래 매직 명령어를 참고해주세요.
막대 그래프
import matplotlib.pyplot as plt
%matplotlib inline
# 그래프 데이터
subject = ['English', 'Math', 'Korean', 'Science', 'Computer']
points = [40, 90, 50, 60, 100]
# 축 그리기
fig = plt.figure() #도화지(그래프) 객체 생성
ax1 = fig.add_subplot(1,1,1) #figure()객체에 add_subplot 메소드를 이용해 축을 그려준다.
# 그래프 그리기
ax1.bar(subject, points)
# 라벨, 타이틀 달기
plt.xlabel('Subject')
plt.ylabel('Points')
plt.title("Yuna's Test Result")
# 보여주기
plt.savefig('./barplot.png') # 그래프를 이미지로 출력
plt.show() # 그래프를 화면으로 출력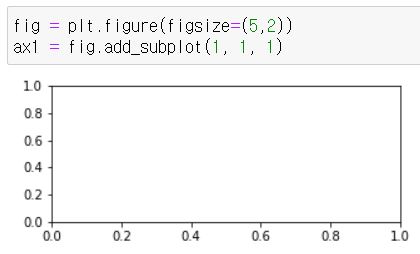
선 그래프
사용할 데이터 - 과거 아마존 주가 데이터
from datetime import datetime
import pandas as pd
import os
# 그래프 데이터
csv_path = os.getenv("HOME") + "/aiffel/data_visualization/data/AMZN.csv"
data = pd.read_csv(csv_path ,index_col=0, parse_dates=True)
price = data['Close'] # Pandas의 Series
# 축 그리기 및 좌표축 설정
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
price.plot(ax=ax, style='black')
# 좌표축 범위 설정
plt.ylim([1600,2200])
plt.xlim(['2019-05-01','2020-03-01'])
# 주석달기
important_data = [(datetime(2019, 6, 3), "Low Price"),(datetime(2020, 2, 19), "Peak Price")]
for d, label in important_data:
# 그래프 안에 추가적으로 글자나 화살표 등 주석을 그릴 때 annotate() 메소드 사용
ax.annotate(label, xy=(d, price.asof(d)+10), # 주석을 달 좌표(x,y)
xytext=(d,price.asof(d)+100), # 주석 텍스트가 위차할 좌표(x,y)
arrowprops=dict(facecolor='red')) # 화살표 추가 및 색 설정
# 그리드, 타이틀 달기
plt.grid()
ax.set_title('StockPrice')
# 보여주기
plt.show()plot 사용법 상세
plt.plot()으로 그래프 그리기
figure() 객체를 생성하고 add_subplot()으로 서브 플롯을 생성하며 plot을 그리는데 이 2가지 과정을 생략할 수 있습니다.
plt.plot()명령으로 그래프를 그리면 matplotlib은 가장 최근의 figure객체와 그 서브플롯을 그립니다. 만약 서브플롯이 없으면 서브플롯 하나를 생성합니다.
plt.plot() 의 인자로 x데이터, y데이터, 마커옵션, 색상 등의 인자를 이요할 수 있습니다.
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x), 'o')
plt.plot(x, np.cos(x) '--', color='black')
plt.show()
# plt.subplot을 이용해 서브 플롯을 추가합니다.
plt.subplot(2,1,1)
plt.plot(x, np.sin(x),'orange','o')
plt.subplot(2,1,2)
plt.plot(x, np.cos(x), 'orange')
plt.show()linestyle, marker옵션
라인 스타일은 plot()의 인자로 들어갑니다.
x = np.linspace(0, 10, 100)
plt.plot(x, x + 0, linestyle='solid')
plt.plot(x, x + 1, linestyle='dashed')
plt.plot(x, x + 2, linestyle='dashdot')
plt.plot(x, x + 3, linestyle='dotted')
plt.plot(x, x + 0, '-g') # solid green
plt.plot(x, x + 1, '--c') # dashed cyan
plt.plot(x, x + 2, '-.k') # dashdot black
plt.plot(x, x + 3, ':r'); # dotted red
plt.plot(x, x + 4, linestyle='-') # solid
plt.plot(x, x + 5, linestyle='--') # dashed
plt.plot(x, x + 6, linestyle='-.') # dashdot
plt.plot(x, x + 7, linestyle=':'); # dottedPandas로 그래프 그리기
Pandas도 plot() 메소드를 통해 여러 가지 그래프를 그릴 수 있습니다.
pandas.plot메서드 인자
- label: 그래프의 범례이름.
- ax: 그래프를 그릴 matplotlib의 서브플롯 객체.
- style: matplotlib에 전달할 'ko--'같은 스타일의 문자열
- alpha: 투명도 (0 ~1)
- kind: 그래프의 종류: line, bar, barh, kde
- logy: Y축에 대한 로그스케일
- use_index: 객체의 색인을 눈금 이름으로 사용할지의 여부
- rot: 눈금 이름을 로테이션(0 ~ 360)
- xticks, yticks: x축, y축으로 사용할 값
- xlim, ylim: x축, y축 한계
- grid: 축의 그리드 표시할 지 여부
pandas의 data가 DataFrame일때 plot 메서드 인자
- subplots: 각 DataFrame의 칼럼을 독립된 서브플롯에 그린다.
- sharex: subplots=True면 같은 X축을 공유하고 눈금과 한계를 연결한다.
- sharey: subplots=True면 같은 Y축을 공유한다.
- figsize: 그래프의 크기, 튜플로 지정
- title: 그래프의 제목을 문자열로 지정
- sort_columns: 칼럼을 알파벳 순서로 그린다.
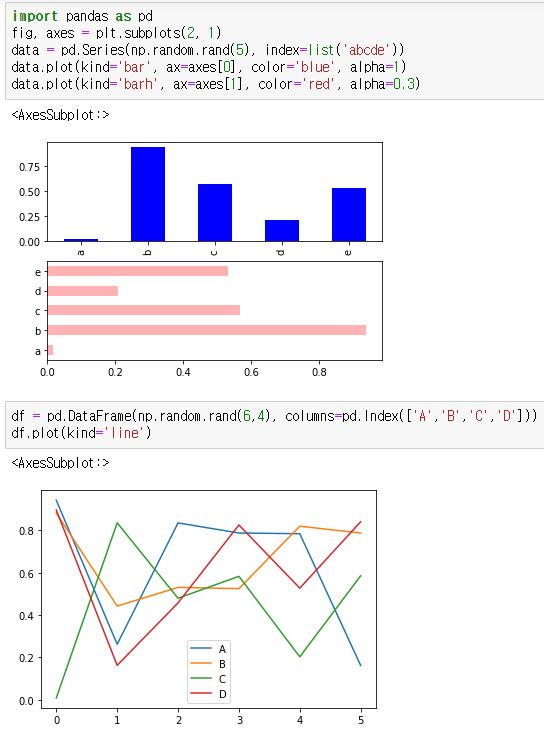
파이썬 기반의 시각화 라이브러리인 Pandas, Matplotlib, Seaborn 모두 그래프를 그리는 방식이 유사합니다.
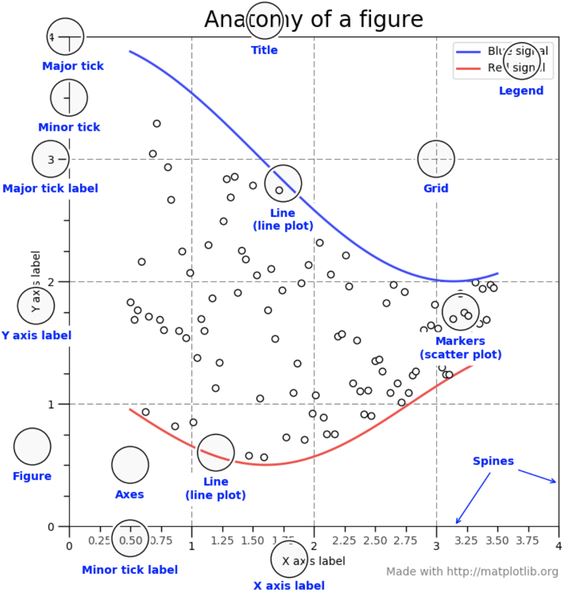
아래 그림은 각 그래프 요소별 명칭입니다.
자주 사용되는 그래프
1. 데이터 준비
1) 데이터 불러오기
Seaborn의 load_dataset() 메소드를 이요하면 API를 통해 손쉽게 유명한 예제 데이터를 다운로드 받을 수 있습니다.
아래 repo의 데이터는 모두 csv파일로 되어 있어 연습용으로 좋습니다.
import seaborn as sns
tips = sns.load_dataset("tips")tips 데이터는 종업원들이 tip을 얼마 받았는지에 대한 데이터가 있는 파일입니다.
2) 데이터 살펴보기 (EDA)
Pandas의 Dataframe을 이용합니다.
df = pd.DataFrame(tips)
df.head()
df.shape
df.describe()
df.info()본 데이터에서는 결측 값이 없으므로 따로 처리할 필요는 없습니다.
데이터 변수들 중에서 sex, smoker, day, time이 범주(category)형 데이터고 tips, total_bill, size는 수치형 데이터입니다. 그러나 size는 테이블 인원을 의미하므로 범주형 데이터로 봐야합니다.
# 범주형 변수의 카테고리별 개수 확인
print(df['sex'].value_count())
print(df['time'].value_count())
print(df['smoker'].value_count())
print(df['day'].value_count())
print(df['size'].value_count())2. 범주형 데이터
Pandas와 Matplotlib를 활용한 방법
matplotlib에 데이터를 인자로 넣기 위해선 pandas 데이터를 바로 이용할 수는 없습니다. 데이터를 x에 series 또는 list, y에 list 형태로 각각 나눠주어야 합니다.
# pandas의 groupby 메소드를 활용합니다.
# 각 성별 그룹에 대한 정보(총합, 평균, 데이터 량 등)가 grouped 객체에 저장됩니다.
grouped = df['tip'].groupby(df['sex'])
grouped.mean() # 성별에 따른 팁의 평균
grouped.size() # 성별에 따른 데이터 량(팁 횟수)
# 성별에 따른 팁 액수의 평균을 막대그래프로 나타냅니다.
sex = dict(grouped.mean())
x = list(sex.keys())
y = list(sex.values())
plt.bar(x = x, height = y)
plt.ylabel('tip[$]')
plt.title('Tip by Sex')Seaborn과 Matplotlib을 활용한 방법
Seaborn을 이용하면 더 쉽게 나타낼 수 있습니다.
# 성별에 대한 tip 평균을 출력합니다.
sns.barplot(data=df, x='sex', y='tip')
# Matplot과 함께 사용하여 figsize, title을 정하는 등 다양한 옵션을 넣을 수 있습니다.
plt.figure(figsize=(10,6)) # 도화지 사이즈를 정합니다.
sns.barplot(data=df, x='sex', y='tip')
plt.ylim(0, 4) # y값의 범위를 정합니다.
plt.title('Tip by sex') # 그래프 제목을 정합니다.
# 요일에 따른 tips의 그래프입니다.
plt.figure(figsize=(10, 6))
sns.barplot(data=df, x='day', y='tip')
plt.ylim(0, 4)
plt.title('Tip by day')
# Subplot을 활용할 수도 있고, 범주형 그래프를 나타내기에 좋은 violineplot을 사용할 수도 있습니다.
# palette 옵션을 주어 더 예쁜 색상을 사용할 수도 있습니다.
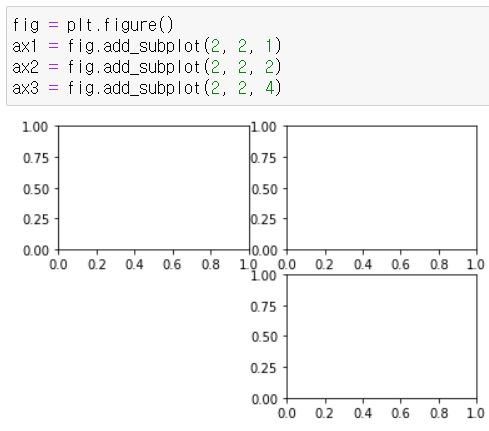
fig = plt.figure(figsize=(10,7))
ax1 = fig.add_subplot(2,2,1)
sns.barplot(data=df, x='day', y='tip',palette="ch:.25")
ax2 = fig.add_subplot(2,2,2)
sns.barplot(data=df, x='sex', y='tip')
ax3 = fig.add_subplot(2,2,4)
sns.violinplot(data=df, x='sex', y='tip')
ax4 = fig.add_subplot(2,2,3)
sns.violinplot(data=df, x='day', y='tip',palette="ch:.25")
# catplot을 사용하여 나타낼 수도 있습니다.
sns.catplot(x="day", y="tip", jitter=False, data=tips)3. 수치형 데이터
수치형 데이터를 나타내는 데 가장 좋은 그래프는 산점도 혹은 선 그래프입니다.
1) 산점도 (scatter plot)
sns.scatterplot(data=df, x='total_bill', y='tip', palette='ch:r=-.2,d=.3_r')
# 요일(day)에 따른 tip과 total_bill의 관계를 시각화합니다.
sns.scatterplot(data=df, x='total_bill', y='tip', hue='day')2) 선 그래프(line graph)
plot의 기본은 선 그래프입니다.
# np.random.randn 함수는 표준 정규분포에서 난수를 생성하는 함수입니다.
# cumsum()은 누적합을 구하는 함수입니다.
plt.plot(np.random.randn(50).cumsum())
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x), 'o')
plt.plot(x, np.cos(x))
plt.show()
# Seaborn을 활용하면 다음과 같이 그릴 수 있습니다.
sns.lineplot(x, np.sin(x))
sns.lineplot(x, np.cos(x))3) 히스토그램
히스토그램은 도수분포표를 그래프로 나타낸 것입니다.
- 계급: 변수의 구간, bin (or bucket) - 가로축
- 도수: 빈도수, frequency - 세로축
전체 총량: n
다음과 같은 데이터의 히스토그램을 만듭니다.
- x1은 평균은 100이고 표준편차는 15인 정규분포를 따릅니다.
- x2는 평균은 130이고 표준편차는 15인 정규분포를 따릅니다.
- 도수를 50개의 구간으로 표시하며, 확률 밀도가 아닌 빈도로 표기합니다.
#그래프 데이터
mu1, mu2, sigma = 100, 130, 15
x1 = mu1 + sigma*np.random.randn(10000)
x2 = mu2 + sigma*np.random.randn(10000)
# 축 그리기
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
# 그래프 그리기
patches = ax1.hist(x1, bins=50, density=False) #bins는 x값을 총 50개 구간으로 나눈다는 뜻입니다.
patches = ax1.hist(x2, bins=50, density=False, alpha=0.5)
ax1.xaxis.set_ticks_position('bottom') # x축의 눈금을 아래 표시
ax1.yaxis.set_ticks_position('left') #y축의 눈금을 왼쪽에 표시
# 라벨, 타이틀 달기
plt.xlabel('Bins')
plt.ylabel('Number of Values in Bin')
ax1.set_title('Two Frequency Distributions')
# 보여주기
plt.show()예제 데이터의 히스토그램
tips 데이터의 total_bill과 tips에 대해 히스토그램을 만듭니다.
sns.distplot(df['total_bill'], label='total_bill')
sns.displot(df['tip'], label='tip').legend() # legend()를 이용하여 label을 표시해 줍니다.
# 전체 결제 금액 대비 팁의 비율을 나타내는 히스토그램을 그립니다.
df['tip_pct'] = df['tip'] / df['total_bill']
df['tip_pct'].hist(bins=50)
df['tip_pct'].plot(kind='kde') # 확률 밀도 그래프(kde)로 나타냅니다.- 밀도 그래프: 연속된 확률분포를 나타냅니다.
- 일반적으로는 kernels메서드를 섞어서 이 분포를 근사하는 식으로 그립니다.
- 이것은 좀 더 단순하고 친숙한 정규분포(가우시안)로 나타낼 수 있습니다
- 위 밀도 그래프는 KDE(Kernel Density Estimate) 커널 밀도 추정 그래프입니다.
- KDE에 대한 설명 참고
시계열 데이터 시각화
1. 데이터 가져오기
csv_path = os.getenv("HOME") + '/gseung/flights.csv'
data = pd.read_csv(csv_path)
flights = pd.DataFrame(data)2. 그래프 그리기
sns.barplot(data=flights, x='year', y='passengers')
sns.pointplot(data=flights, x='year', y='passengers')
sns.lineplot(data=flights, x='year', y='passengers')
# 달별로 나누어 보기위해 hue인자에 'month'를 할당합니다.
sns.lineplot(data=flights, x='year', y='passengers', hue='month', palette='ch:.50')
plt.legend(bbox_to_anchor=(1.03, 1), loc=2) # legend 그래프 밖에 추가하기
# 히스토그램
sns.distplot(flights['passengers'])Heatmap
Heatmap은 방대한 양의 데이터와 현상을 수치에 따른 색상으로 나타낸 것으로, 데이터 차원에 대한 제한은 없으나 모두 2차원으로 시각화하여 표현합니다.
예제 데이터의 연도와 달에 대해 탑승객 수를 heatmap으로 나타냅니다.
Heatmap을 그리기 위해 데이터를 pivot해야 하는 경우가 있습니다.
pivot이란 어떤 축, 점을 기준으로 바꾸다란 뜻입니다. 데이터 표를 재배치 할때도 pivot이라는 단어를 사용합니다. (엑셀, Database에도 등장하는 용어입니다.)
pandas의 dataframe의 pivot() 메소드를 사용합니다.
flights(DataFrame)을 탑승객 수를 year과 month로 pivot 합니다.
pivot = flights.pivot(index='year', columns='month', values='passengers')
pivot
sns.heatmap(pivot)
# 그밖에 다양한 옵션이 있습니다.
sns.heatmap(pivot, linewidths=.2, annot=True, fmt="d")
sns.heatmap(pivot, cmap="YIGnBu")
