이번에 사용할 패키지는 Pillow, OpenCV, Matplotlib입니다.
pip install pillow opencv-python matplotlib
사용할 데이터셋은 CIFAR-100 입니다.
디지털 이미지
색상을 가지는 점 하나를 화소(pixel, picture element)라고 하며 각 화소는 RGB로 색상을 표현합니다.
빨강, 초록, 파랑 세 가지 색의 강도로 표현하는 점들로 구성된 디지털 화면에 표시될 이미지를 저장하는 방법 중 가장 단순한 방법은, 각 점 하나하나의 색상 값을 저장하는 방식입니다.
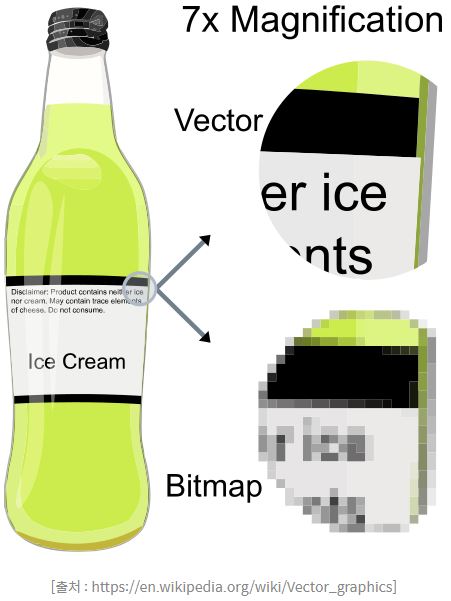
이를 래스터(raster) 또는 비트맵(bitmap) 방식의 이미지라고 하며, 보통 한 점마다 각 색상별로 8비트를 사용하여 0~255 사이의 값(으로 해당 색의 감도를 표시합니다.
반면에 벡터(vector) 방식의 이미지는 상대적인 점과 선의 위치를 방정식으로써 기록해 두었다가, 확대 및 축소에 따라 디지털 화면의 각 화소에 어떻게 표현될지를 재계산하기에 깨짐이 없습니다. 우리가 주로 다루는 파일들 중에는 사진 파일들이 래스터 방식이며, 확대 축소가 자유로이 가능한 글꼴들이 주로 벡터 방식입니다.
색상을 출력하는 방식은 RGB뿐만아니라 다양한 방법으로 표현할 수 있습니다. 예를 들어 흑백(grayscale) TV 시절에서 컬러 TV로 넘어가던 시절에는, 인간의 눈이 색상의 차이보다는 음영에 더 민감한 것을 역이용하여, 기존 흑백 채널에다가 그보다 1/4의 해상도를 가진 두 색상 채널을 덧붙여서 송출하는 YUV 방식(아래 사진)이 사용되었습니다.

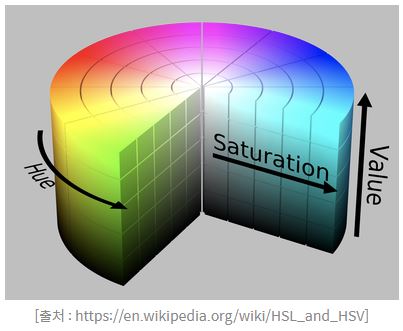
또한 디지털 화면에서 색감을 수치적으로 조작할 때 조금 더 직관적으로 이해할 수 있는 HSV(Hue 색상, Saturation 채도, Value 명도)도 자주 사용됩니다. 이외에 인쇄 매체의 경우에는 색의 강도를 높일수록 어두워진다는 특성과, 또한 자주 사용되는 검은색을 표현할 때 각 색을 조합하면 잉크의 낭비가 심하다는 현실적인 이유 때문에, RGB가 아닌 CMYK(Cyan, Magenta, Yellow, Black) 네 가지 색상을 사용합니다.
이렇게 색을 표현하는 다양한 방식을 각각 컬러 스페이스(color space, 색 공간)라고 하며, 각 컬러 스페이스를 구성하는 단일 축(RGB에서의 각각 R, G, B)을 채널(channel)이라고 합니다.
하지만 이러한 색상 정보를 그대로 저장하기에는 생각보다 많은 용량을 차지합니다. 따라서 사진 저장에 흔히 쓰이는 JPEG 이미지 형식의 경우 근처에 있는 화소들을 묶어, 비슷한 색들을 뭉뚱그리는 방식으로 이미지를 압축합니다.
이러한 방식에는 색상 정보의 손실이 있기에, 저장할 때 압축률을 높이거나, 여러 번 다시 저장하는 등 재압축이 일어나게 될 경우, 흔히 디지털 풍화라고 불리는 색상이 지저분해지는 현상을 볼 수 있습니다.
이와 반대로 스크린샷 등에 많이 사용되는 PNG 이미지 형식의 경우 색상의 손실 없이 이미지를 압축하는데, 이미지에 사용된 색상을 미리 정의해두고 그를 참조하는 팔레트 방식을 사용할 수 있기에, 사용된 색상이 적은 단순한 이미지의 경우 동일한 해상도의 JPEG 파일보다도 용량이 작을 수 있지만, 사진과 같이 이미지에 사용된 색상이 많아지면 JPEG 파일보다 쉽게 더 많은 용량을 차지합니다. 이외에 움짤로 익숙한 GIF 형식의 이미지는 이미지 내에 여러 프레임을 두어 이를 움직이게 만들 수 있고, 또한 색상 정보를 손실 없이 저장하나, 256개의 색상만 기억할 수 있는 팔레트 방식으로 제한됩니다.
Pillow 사용법
예전에 PIL(Python Image Library)가 있었으나 2011년 마지막 커밋을 이후로 개발이 중단되었습니다. 대신 Pillow가 현재까지 개발되고 있습니다.
간단한 이미지 작업에 Pillow는 Numpy와 결합하여 간편하게 사용할 수 있는 도구입니다.
이미지는 배열 형태의 데이터입니다. 데이터 타입을 uint8 (부호가 없는 8비트 정수)이 되어 0~255( 사이의 값을 나타내도록 합니다.
import numpy as np
from PIL import Image
data = np.zeros([32, 32, 3], dtype=np.uint8)
image = Image.fromarray(data, 'RGB')
image
data[:,:] = [255, 255, 255] # 흰색 이미지로 바꾸기만들어진 배열을 PIL.Image.fromarray()를 통해 바로 이미지 객체로 변환한 뒤 화면에 표시합니다. 단, jupyter notebook이 아닌 IDE 혹은 개발환경에서 이미지를 표시하려면 .show() 메서드를 사용합니다.
from PIL import Image
import os
# 연습용 파일 경로
image_path = os.getenv('HOME')+'/aiffel/python_image_proc/data/pillow_practice.png'
# 이미지 열기
img = Image.open(image_path)
img
# width와 height 출력
print(img.width)
print(img.height)
# JPG 파일 형식으로 저장해보기
new_image_path = os.getenv('HOME')+'/aiffel/python_image_proc/data/jpg_pillow_practice.jpg'
img = img.convert('RGB')
img.save(new_image_path)
# 이미지 크기 변경
resized_image = img.resize((100,200))
resized_image.save(resized_image_path)
# crop으로 눈 부분만 잘라내어 저장
box = (300, 100, 600, 400)
region = img.crop(box)
region.save(cropped_image_path)Pillow를 활용한 데이터 전처리
CIFAR-100여기서 CIFAR-100 python version을 다운받습니다. 압축 해제하면 이미지 파일들이 아니라 meta, test, train이 있습니다. 여기서 train 파일만 사용합니다.
import os
import pickle
from PIL import Image
dir_path = os.getenv('HOME')+'/aiffel/python_image_proc/data/cifar-100-python'
train_file_path = os.path.join(dir_path, 'train')
with open(train_file_path, 'rb') as f:
train = pickle.load(f, encoding='bytes')
print(type(train))
print(train)
print(train.keys()) # 각 키들이 문자열(`str`)이 아닌 `bytes`로 되어있습니다.
print(type(train[b'filenames']) # 결과: list
print(train[b'filenames'][0:5]
print(train[b'data'][0:5]) # 결과: nummpy 배열
print(train[b'data'][0].shape # 결과: (3072,)
# 위에서 나온 3072는 RGB 3채널 x 1024(=32*32)씩 각 화소에 해당합니다.주의사항
앞 1024바이트는 빨강(R), 그다음 1024는 녹색(G), 마지막 1024는 파랑(B)로 되어 있습니다. 이를 32x32에 채우는 것을 3번 반복하는 형식의 reshape이 되어야 합니다.
앞선 차원부터 데이터를 채우는 방식의 reshape을 위해 order 인자를 사용합니다.
image_data = train[b'data'][0].reshape([32, 32, 3], order='F') # order를 주의하세요!!
image = Image.fromarray(image_data) # Pillow를 사용하여 Numpy 배열을 Image객체로 만듭니다.
image
# x축과 y축이 뒤집어져 있으므로 축을 바꿔줍니다.
image_data = image_data.swapaxes(0, 1)
image = Image.fromarray(image_data)데이터셋에 파일명과 파일 데이터 배열이 순서를 따라 저장되어있으므로 차례로 Numpy 배열로 읽고 이미지 파일로 저장해줍니다.
(참고) tqdm을 사용하면 반복 작업의 진행 상황을 시각화해서 체크해 볼 수 있습니다.
import os
import pickle
from PIL import Image
import numpy
from tqdm import tqdm
dir_path = os.getenv('HOME')+'/aiffel/python_image_proc/data/cifar-100-python'
train_file_path = os.path.join(dir_path, 'train')
# image를 저장할 cifar-100-python의 하위 디렉토리(images)를 생성합니다.
images_dir_path = os.getenv('HOME')+'/aiffel/python_image_proc/cifar-images'
if not os.path.exists(images_dir_path):
os.mkdir(images_dir_path) # images 디렉토리 생성
# 32X32의 이미지 파일 50000개를 생성합니다.
with open(train_file_path, 'rb') as f:
train = pickle.load(f, encoding='bytes')
for i in tqdm(range(len(train[b'filenames']))):
filename = train[b'filenames'][i].decode()
data = train[b'data'][i].reshape([32, 32, 3], order='F')
image = Image.fromarray(data.swapaxes(0, 1))
image.save(os.path.join(images_dir_path, filename))OpenCV
OpenCV(튜토리얼는 오픈소스로 제공되는 컴퓨터 비전용 라이브러리입니다. C++, Python, Java, MATLAB 등 다양한 언어에서 호출하여 사용할 수 있으며, 영상 처리에 대한 다양한 고급 기능들이 사용하기 쉽도록 구현되어 있습니다.
파이썬 튜토리얼 페이지에서 이미지의 특정 색을 가진 영역만 추출하는 예제를 봅시다.
이미지는 [너비, 높이, 채널] 형태를 가지는 배열입니다. 위 예제에서는 이미지를 읽어 들이고, 파란색을 찾기 쉽도록 컬러스페이스를 BGR(RGB)에서 HSV로 변환한 뒤, 해당 색상과 맞는 영역만 표시하는 작업이 진행됩니다.
!주의: OpenCV에서는 RGB가 아닌 BGR 순서를 사용합니다.
import os
import pickle
from PIL import Image
dir_path = os.getenv('HOME')+'/aiffel/python_image_proc/data/cifar-100-python'
train_file_path = os.path.join(dir_path, 'train')
with open(train_file_path, 'rb') as f:
train = pickle.load(f, encoding='bytes')
print(type(train))imread 함수 설명: OpenCV 공식 문서 사이트
cvtColor: 컬러 스페이스 변환(convert)을 위한 함수입니다.
OpenCV: Color Space Conversions
hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
숫자로 파란색이라는 부분을 정의하고, 이 값들을 기준으로 이미지에서 마스크를 생성하는 과정입니다. 마스크란 원하는 부분만을 떼어낼 수 있도록 하는 역할입니다.
# define range of blue color in HSV
lower_blue = np.array([100,100,100])
upper_blue = np.array([130,255,255])
# Threshold the HSV image to get only blue colors
mask = cv.inRange(hsv, lower_blue, upper_blue)위 코드에서는 HSV 색 공간에서 색상(Hue) 값 110~130 사이, 채도(Saturation) 및 명도(Value) 값 50~255 사이의 색들을 파란색이라고 정의하고 있습니다. 그리고 아까 img 를 변환한 hsv에다가 이 기준들(lower_blue, upper_blue)를 적용하여, 해당하는 픽셀들에는 1, 그렇지 않은 픽셀들에는 0을 찍어놓은 배열을 반환하는 것이 cv.inRange()의 역할입니다.
mask는 픽셀마다 1 또는 0만을 값으로 가졌기에 의 크기를 갖게 됩니다. 1을 흰색으로, 0을 검정색으로 표시하면 아래와 같이 됩니다.

이제 사진을 선택한 부분만 오려냅니다.
# Bitwise-AND mask and original image
res = cv.bitwise_and(img, img, mask=mask)cv.bitwise_and()에 대한 설명은 여기를 참고하세요.
이미지 두 장을 받아서 AND 비트 연산을 하는데, 이 기능이 필요한 게 아니니 두 장 다 같은 이미지(img, img)를 넣어서 결국 동일한 이미지가 나오게 합니다. 대신 중요한 mask를 같이 넣어줘서, 해당 영역만 따오도록 합니다. 따온 영역은 위 공식 문서 페이지의 함수 설명에 따라 dst가 주어진다면 그 위에, 아니면 새로 빈 검정색 영역 위에 이미지를 만들고 반환합니다.
출력을 진행합니다.
plt.imshow(cv.cvtColor(img, cv.COLOR_BGR2RGB))
plt.show()
plt.imshow(cv.cvtColor(mask, cv.COLOR_BGR2RGB))
plt.show()
plt.imshow(cv.cvtColor(res, cv.COLOR_BGR2RGB))
plt.show()OpenCV에서 RGB가 아닌 BGR순서를 사용하므로 plt로 이미지를 보여줄 땐 cv.cvtColor(res, cv.COLOR_BGR2RGB)함수를 통해 cv 이미지 객체의 컬러를 변환해줍니다.
카메라에서 받아온 이미지 img
파란색 영역만 골라낸 마스트 'mask'
이미지에 마스크를 적용한 결과 'res'
plt가 아니라 cv로도 이미지를 띄울 수 있습니다.
cv.imshow(res), PIL.Image.show()
실습
본 실습에서는 이미지에서 색상 히스토그램을 추출하고, 이를 서로 비교하는 기능들을 사용합니다.
히스토그램이란?
이미지에서 픽셀 별 색상 값의 분포입니다.
히스토그램을 통해 각 이미지의 색상 분포를 비교하여 서로 유사한 이미지를 판단하는 척도로 사용합니다.
0~255 사이 각 값에 해당하는 픽셀의 개수를 저장하기에는 계산량이 많아지므로, 단순화 측면에서 4개 구간(0~63, 64~127, 128~191, 192~255)로 나누어 픽셀 수를 셉니다.
OpenCV자체는 C++로 구현되어 있고, 이를 파이썬에서 불러 쓸 수 있도록 하는 패키지인 opencv-python를 설치해야 합니다. 또한 히스토그램을 실제로 화면에 표시하기 위해 matplotlib도 필요합니다.
$ pip install opencv-python matplotlib
# 파일명을 인자로 받아 해당 이미지 파일과 히스토그램을 출력해 주는 함수
def draw_color_histogram_from_image(file_name):
image_path = os.path.join(images_dir_path, file_name)
# 이미지 열기
img = Image.open(image_path)
cv_image = cv2.imread(image_path)
# Image와 Histogram 그려보기
f=plt.figure(figsize=(10,3))
im1 = f.add_subplot(1,2,1)
im1.imshow(img)
im1.set_title("Image")
im2 = f.add_subplot(1,2,2)
color = ('b','g','r')
for i,col in enumerate(color):
# image에서 i번째 채널의 히스토그램을 뽑아서(0:blue, 1:green, 2:red)
histr = cv2.calcHist([cv_image],[i],None,[256],[0,256])
im2.plot(histr,color = col) # 그래프를 그릴 때 채널 색상과 맞춰서 그립니다.
im2.set_title("Histogram")
draw_color_histogram_from_image('adriatic_s_001807.png')OpenCV: Histograms - 1 : Find, Plot, Analyze !!!
STEP 1. 개요
이미지 파일 경로 하나를 명령줄에서 입력으로 받아, 검색 대상 이미지들 중 비슷한 이미지들을 골라 화면에 표시하는 기능을 수행합니다.
히스토그램을 만들어주는 함수 cv2.calcHist()와 마찬가지로, 히스토그램끼리의 유사성을 계산해주는 기능 역시 OpenCV에서 제공해주는 cv2.compareHist()라는 함수를 사용해서 해결합니다.
이미지 파일 경로를 명령줄에서 입력으로 받는 것은 sys.argv를 사용합니다. 검색 대상 이미지는 CIFAR-100 이미지를 사용합니다.
STEP 2. 구체화
- 프로그램이 실행된다.
- 입력된 경로의 이미지 파일을 불러온다.
- 검색 대상 이미지들 중 불러온 이미지와 가장 비슷한 이미지 5개를 고른다.
- 검색 대상 이미지들을 불러온다.
- 입력 이미지와 비교하여 유사도를 기준으로 순서를 매긴다.
- 유사도 순서상으로 상위 5개 이미지를 고른다.
- 고른 이미지들을 표시한다.
- 프로그램이 종료된다.
# 모든 이미지 파일을 대상으로 히스토그램을 만듭니다.
def get_histogram(image):
histogram = []
# Create histograms per channels, in 4 bins each.
for i in range(3):
channel_histogram = cv2.calcHist(images=[image],
channels=[i],
mask=None,
histSize=[4], # 히스토그램 구간을 4개로 한다.
ranges=[0, 256])
histogram.append(channel_histogram)
histogram = np.concatenate(histogram)
histogram = cv2.normalize(histogram, histogram)
return histogram
# get_histogram() 확인용 코드
filename = train[b'filenames'][0].decode()
file_path = os.path.join(images_dir_path, filename)
image = cv2.imread(file_path)
histogram = get_histogram(image)
histogram
def build_histogram_db():
histogram_db = {}
#디렉토리에 모아 둔 이미지 파일들을 전부 리스트업합니다.
path = images_dir_path
file_list = os.listdir(images_dir_path)
for file_name in tqdm(file_list):
file_path = os.path.join(images_dir_path, file_name)
image = cv2.imread(file_path)
histogram = get_histogram(image)
histogram_db[file_name] = histogram
return histogram_db
histogram_db = build_histogram_db()
histogram_db['adriatic_s_001807.png']
def get_target_histogram():
filename = input("이미지 파일명을 입력하세요: ")
if filename not in histogram_db:
print('유효하지 않은 이미지 파일명입니다.')
return None
return histogram_db[filename]
target_histogram = get_target_histogram()
target_histogram아래의 search 함수는 입력 이미지 히스토그램 target_histogram와 전체 검색 대상 이미지들의 히스토그램을 가진 딕셔너리 histogram_db를 입력으로 받습니다. 입력부에 유사도 순으로 몇 개까지 결과에 남길지 top_k=5라는 파라미터를 하나 추가해 줍니다.
def search(histogram_db, target_histogram, top_k=5):
results = {}
# Calculate similarity distance by comparing histograms.
for file_name, histogram in tqdm(histogram_db.items()):
distance = cv2.compareHist(H1=target_histogram,
H2=histogram,
method=cv2.HISTCMP_CHISQR)
results[file_name] = distance
results = dict(sorted(results.items(), key=lambda item: item[1])[:top_k])
return results
result = search(histogram_db, target_histogram)
result
# result를 입력받아 5개의 이미지를 화면에 출력하는 함수입니다.
def show_result(result):
f=plt.figure(figsize=(10,3))
for idx, filename in enumerate(result.keys()):
img_path = os.path.join(images_dir_path, filename)
im = f.add_subplot(1,len(result),idx+1)
img = Image.open(img_path)
im.imshow(img)
show_result(result)
# 검색할 이미지를 Input으로 받으면 즉시 가장 유사한 이미지가 화면에 출력됩니다.
target_histogram = get_target_histogram()
result = search(histogram_db, target_histogram)
show_result(result)참고자료
