배운 점
새로운 키워드
- 효율적인 시각화 원칙(Separability): 위치 + 색상(Fully separable), 크기 + 색상(Some interference), 길이/너비(significant interference), 빨강 + 초록(major interference) 등...
- 범주형 데이터에는 구분이 주인 명목형 데이터(성별, 국가), 순서가 존재하는 순서형 데이터(영화 별점)가 있다.
인사이트
-
AI 모델링은 AI Product에 있어 매우 일부분: 부스트캠프에 참여하면서 동료들과 토론하고 올라오는 질문을 보면 모델의 구조를 매우 디테일하게 살펴보았다. 그들 덕분에 쉽사리 넘어갔던 개념을 깊게 다시 볼 수 있는 이정표가 됐다. 하지만, 나는 개발자들이 보는 개발자가 되고 싶기 보다는 문제를 해결하는 개발자가 되고 싶다. 더 나아가서는 문제를 정의하는 개발자가 되고 싶다. 강의에 나온 이런 인사이트는 내가 목표한 길에서 흔들리는 나에게 경종을 울렸다.
-
데이터 업계의 장애물: 목적 부재 혹은 오설정, 데이터 및 리소스 부재, 데이터 만능주의
-
데이터 문해력 역량: 좋은 질문, 데이터 선별 및 검증, 유의미한 결론 도출, A/B 테스트로 결과 판단, 분석 결과 표현(ex) 시각화), 전체 그림 제시 및 분석 결과로 실행하게 하는 역량
-
데이터와 정보는 다르다!
-
bar plot: 카테고리에 따른 데이터 값을 보기 위함, 데이터 값의 범위가 다양할 때 세로 축에 표기, 축의 시작은 0, 복잡하면 오히려 가독성 ↓
-
line plot: 추세를 보기 위함, 이중 축 지양 → 두개의 plot
-
scatter plot: 상관 관계 확인(군집, 값의 차이, 이상치)
-
색상: 범주형: 일반적으로 7개 이상 구분이 어려움, 연속형: 깃허브 잔디밭, 발산형: 평균 기온 데이터
-
명목형 데이터 전처리 방법
label encoding: 순서가 존재해서 모델에 영향을 줄 수도 있다.
one-hot encoding: 범주에 따라 메모리를 많이 차지
embedding, hashing: 자연어 처리, 순서 정보를 아예 없앰 -
순서형 데이터: 명목형 데이터 전처리 모두 사용 가능하다.
-
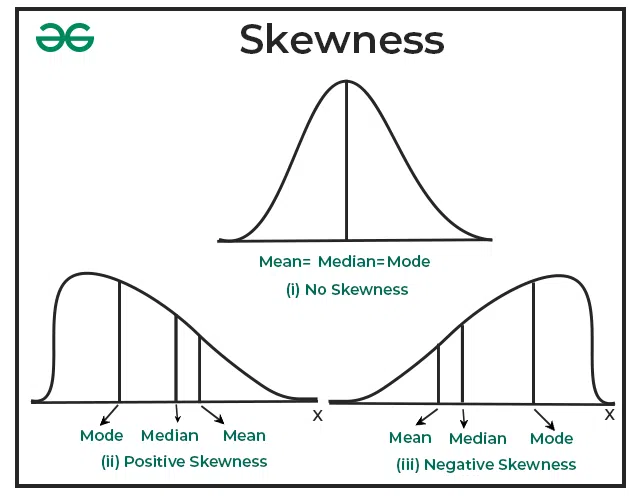
이산형 데이터: 구간형(온도, 시간), 비율형(인구수, 횟수) → skewness, kurtosis 등의 척도로 분석 가능
-
정규화 vs 표준화 기준: 데이터의 범위가 중요하거나, 분포가 균일하지 않은 경우 → 정규화, 데이터가 정규분포를 따르거나 서로 다른 단위 혹은 크기를 가지고 있을 때 → 표준화
-
negative skewness: square/power trans, exponential trans
-
positive skewness: log, sqrt trans → 0 이상 혹은 양수라는 조건 ++ Box-Cox trans
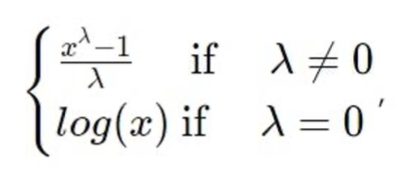
-
결측치 비율에 따른 EDA
결측치가 과반수인 경우: 데이터 유무만 사용 or 해당 열 제외
5% 보다 많을 경우: 결측치가 유의미한 정보인지 파악 → 대푯값 전략
매우 적은 경우: 결측치 행 제외 or 대푯값 계산 -
결측치 대푯값: 규칙 기반, 집단 대푯값, 모델 기반
-
이상치: IQR, DBSCAN: 밀도 기반 클러스터링
좋았던 점
- 데이터 엔지니어링에 대해서 전반적인 개념을 훑어봤다! 데이터 엔지니어링과 ML/DL 엔지니어링과 차이점이 모호했는데, 조금은 구분할 수 있는 것 같다. inference와 의사 결정을 유도하는 것!
아쉬운 점
- matplotlib 문법 숙지가 덜 됐다. 암기를 다 해야 하나?
