데이터베이스 트랜잭션과 격리 수준은 다중 사용자가 동시에 데이터를 액세스할 때 일관성과 무결성을 유지하기 위해 매우 중요합니다. 트랜잭션 격리 수준은 동시에 실행되는 트랜잭션 간에 어떤 현상(예: Dirty Read, Non-repeatable Read, Phantom Read)을 허용하거나 방지할지를 결정합니다. 현대 RDBMS들은 이러한 격리를 구현하기 위해 다중 버전 병행 제어 (MVCC, Multi-Version Concurrency Control) 같은 기법을 사용하여, 읽기와 쓰기가 충돌 없이 수행되도록 합니다. 한편, 애플리케이션 개발 관점에서 JPA(Java Persistence API)와 Hibernate 같은 ORM 프레임워크는 쓰기 지연(write-behind) 전략을 사용하여 트랜잭션 내에서 SQL 실행을 지연시키고 있습니다. 이번 글에서는 MVCC를 기반으로 하는 RDBMS의 트랜잭션 처리 방식과 JPA의 쓰기 지연 및 flush 메커니즘이 어떻게 연관되는지 알아보겠습니다. 이를 통해 DB 트랜잭션 격리와 JPA 영속성 컨텍스트가 함께 작동하는 방식을 이해하고, 성능 최적화와 일관성 유지 측면에서 어떤 고려사항이 있는지 살펴보겠습니다.
1. MVCC란 무엇인가?
트랜잭션 격리 수준 개요
전통적으로 데이터베이스는 4가지 트랜잭션 격리 수준을 제공합니다 (낮은 수준에서 높은 수준 순): READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE. 각각의 수준은 허용하는 비일관성 현상이 다릅니다. 예를 들어, READ UNCOMMITTED는 Dirty Read(다른 트랜잭션이 커밋하지 않은 변경사항을 읽음)를 허용하지만, READ COMMITTED는 이를 허용하지 않습니다. REPEATABLE READ는 한 트랜잭션 내에서 같은 쿼리를 두 번 실행할 때 Non-repeatable Read(중간에 다른 트랜잭션이 수정한 변경으로 결과가 달라지는 현상)를 방지합니다. SERIALIZABLE은 가장 엄격한 수준으로, 팬텀 리드(Phantom Read)까지 포함하여 모든 비일관성 현상을 막아줍니다.
격리 수준을 높일수록 트랜잭션 간 간섭은 줄어들지만, 잠금으로 인한 동시성 제어 비용은 증가할 수 있습니다. 이를 해결하기 위해 많은 RDBMS가 MVCC 기법을 도입하였습니다. MVCC를 사용하면 잠금을 최소화하면서도 트랜잭션 격리를 확보할 수 있습니다.
MVCC의 개념 및 동작 방식
MVCC (Multi-Version Concurrency Control)란 데이터베이스가 동시에 여러 버전의 레코드(row)를 유지함으로써, 읽기 작업이 쓰기 작업을 블로킹하지 않고도 일관된 데이터를 조회할 수 있게 하는 기법입니다. 간단히 말해, 데이터베이스는 업데이트가 발생할 때마다 기존 레코드의 이전 버전을 보존하고 새로운 버전을 생성합니다. 읽는 트랜잭션은 자신이 시작할 때의 시점(snapshot)을 기준으로 데이터 일관성을 유지하며, 그 이후 다른 트랜잭션이 데이터 값을 변경하더라도 자신의 트랜잭션이 보는 데이터는 변하지 않도록 보장받습니다. 이를 통해 읽기와 쓰기 간의 충돌 없이 동시에 처리가 가능해집니다.
MVCC의 작동을 이해하기 위해, 트랜잭션 ID와 버전 관리를 살펴보겠습니다. 트랜잭션이 시작되면 데이터베이스는 해당 트랜잭션에 고유한 트랜잭션 ID (XID)를 부여합니다. 각 데이터베이스 레코드(행)에도 최종 수정한 트랜잭션 ID와 Undo 로그 포인터 등의 메타정보가 숨겨져 저장됩니다. InnoDB와 같은 MVCC 지원 스토리지 엔진에서는, 데이터를 읽을 때 현재 트랜잭션의 XID와 각 레코드 버전의 XID를 비교하여 해당 트랜잭션이 볼 수 있는 적절한 버전을 선택합니다. 예를 들어:
- 레코드의 XID가 현재 트랜잭션의 XID보다 오래되었다면(해당 레코드 변경이 현재 트랜잭션 시작 전에 커밋됨), 그 버전은 현재 트랜잭션에 보이는 유효한 버전입니다.
- 레코드의 XID가 현재 트랜잭션 이후이거나 아직 커밋되지 않은 활성 트랜잭션의 ID라면, 해당 변경은 나중 시점의 것이므로 현재 트랜잭션에서는 볼 수 없습니다. 이 경우 InnoDB는 Undo 로그에 저장된 이전 버전 정보를 이용해, 현재 트랜잭션이 볼 수 있는 가장 최근 커밋된 버전을 구성하여 반환합니다.
- 데이터 변경이 일어날 때마다 InnoDB는 Undo 로그에 이전 버전을 기록하고 레코드의 롤백 포인터(roll pointer)를 통해 이전 버전들과 연결시켜 둡니다. 이를 통해 과거 특정 시점의 일관된 데이터 조회나 트랜잭션 롤백이 가능해집니다.
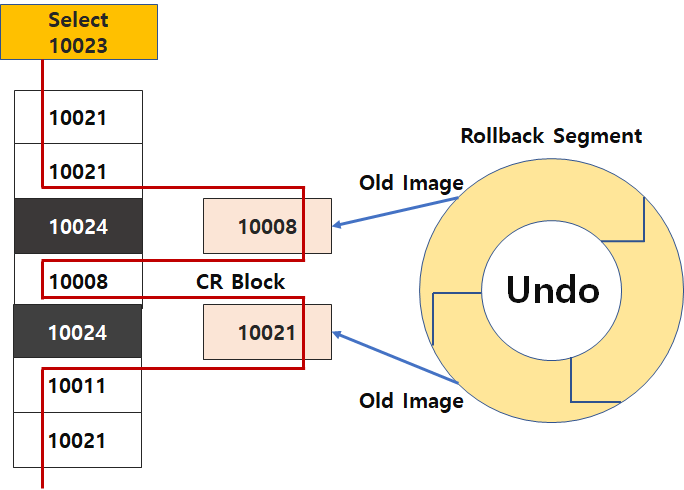
- 사용자가 특정 시점의 데이터를 읽으려 할 때(여기서는 버전 10023), 해당 데이터가 이미 다른 트랜잭션에 의해 변경된 최신 상태(10024, 10008)라면, 데이터베이스는 이 최신 데이터를 그대로 주지 않습니다.
- 대신 데이터베이스는 과거의 데이터를 가지고 있는 Undo 영역(Rollback Segment)에 접근하여, 사용자가 원하는 시점의 이전 데이터 버전(Old Image, 여기서는 10008과 10021)을 가져옵니다.
- 이렇게 가져온 과거 데이터를 이용해 일관된 읽기(Consistent Read) 를 위한 블록(CR Block)을 구성합니다.
즉, MVCC는 쓰기 작업과 읽기 작업의 충돌을 방지하고, 트랜잭션 간의 격리를 보장하기 위해 최신 데이터가 아닌, 필요한 시점의 과거 데이터를 Undo를 통해 제공하는 것입니다.
이러한 MVCC 동작을 통해 읽기 시 일관성(consistency)과 격리(isiolation)가 유지됩니다. 예를 들어, MySQL InnoDB에서 기본 격리 수준인 REPEATABLE READ인 경우, 트랜잭션 시작 시점에 스냅샷(Read View)을 생성하여 그 트랜잭션 내내 일관된 데이터 보기를 제공합니다. 트랜잭션이 진행되는 동안 다른 트랜잭션이 데이터를 수정하고 커밋하더라도, 현재 트랜잭션은 트랜잭션 시작 시점의 데이터베이스를 스냅샷 떠서 보는 것과 같은 효과를 누립니다. 반면 READ COMMITTED 격리 수준에서는 각 SQL 문이 실행될 때마다 최신 커밋된 데이터를 보는 스냅샷을 취합니다. 이런 방식으로 MVCC는 동시에 여러 트랜잭션이 수행되더라도, 각 트랜잭션이 독자적인 일관된 데이터 상태를 유지하도록 합니다.
MySQL InnoDB에서의 MVCC (Undo 로그와 Read View)
MySQL InnoDB 스토리지 엔진은 MVCC를 구현하기 위해 Undo 로그와 Read View(읽기 뷰) 개념을 활용합니다. Undo 로그는 앞서 언급한 대로 이전 데이터 버전들을 보관하는 공간으로, 트랜잭션에서 변경이 발생할 때마다 기존 값이 Undo 로그에 기록됩니다. 트랜잭션이 롤백하는 경우 Undo 로그를 참고하여 변경 전 상태로 되돌릴 수 있고, 현재 트랜잭션이 필요로 하는 과거 버전 역시 Undo 로그를 통해 제공됩니다.
Read View는 InnoDB가 일관된 읽기(consistent read)를 제공하기 위해 내부적으로 관리하는 스냅샷 정보입니다. 새로운 트랜잭션이 시작되거나 첫 SELECT 쿼리를 실행할 때, InnoDB는 현재 활성화된 다른 트랜잭션들의 ID 목록 등을 기반으로 읽기 뷰를 생성합니다. 이 읽기 뷰는 “어떤 트랜잭션까지의 커밋을 볼 수 있고, 어떤 트랜잭션의 변경은 보이지 않을지”를 결정하는 기준이 됩니다. InnoDB는 각 레코드의 트랜잭션 ID와 현재 트랜잭션의 Read View를 비교하여, 해당 트랜잭션이 볼 수 있는 가장 최신 버전을 선택합니다. 덕분에 읽기 작업은 별도의 잠금 없이도 (non-locking consistent read) Undo 로그를 통해 과거 버전을 조회함으로써 격리 수준이 보장됩니다.
예를 들어, 트랜잭션 A가 어떤 데이터를 읽고 있는 동안 트랜잭션 B가 그 데이터를 수정하고 커밋하더라도, 트랜잭션 A의 격리 수준이 REPEATABLE READ라면 트랜잭션 A는 트랜잭션 B의 변경을 자신의 트랜잭션이 끝날 때까지 보지 못합니다. 이러한 MVCC 특성은, 동시에 수행되는 여러 트랜잭션 간에 충돌을 최소화하고 성능을 높여주지만, 한편으로 오래 지속되는 트랜잭션에 대해서는 주의가 필요합니다. 그 부분은 뒤에서 성능 고려 사항에서 다루겠습니다.
2. JPA의 쓰기 지연과 Flush 메커니즘
Hibernate의 영속성 컨텍스트와 1차 캐시
JPA 구현체인 Hibernate에서는 영속성 컨텍스트(Persistence Context)라는 개념을 통해 엔티티 객체를 관리합니다. 이는 흔히 1차 캐시라고도 불리며, 애플리케이션에서 조회하거나 수정한 엔티티를 메모리 내에 보관하여 동일 트랜잭션 내에서는 반복적으로 데이터베이스를 조회하지 않도록 해줍니다. 영속성 컨텍스트는 또한 변경된 엔티티에 대한 쓰기 지연(Write-Behind)을 구현하는 공간으로 동작합니다.
Hibernate의 쓰기 지연(transactional write-behind)이란, 엔티티의 상태 변경(INSERT/UPDATE/DELETE)이 발생해도 즉시 데이터베이스에 반영하지 않고 영속성 컨텍스트에 모아두었다가 적절한 시점에 한꺼번에 반영하는 전략을 말합니다. 이러한 동작은 트랜잭션이 진행되는 동안 여러 번 일어날 수 있지만, 기본적으로 Hibernate는 가능한 한 flush 시점을 지연시키다가 마지막에 몰아서 수행하려고 합니다. 영속성 컨텍스트가 일종의 버퍼(cache) 역할을 하여, 변경사항을 임시로 담아두고 나중에 DB와 동기화하는 것이죠.
쓰기 지연과 Flush의 동작 방식
Flush는 Hibernate (JPA)에서 영속성 컨텍스트의 변경 내용을 데이터베이스와 동기화하는 동작을 가리킵니다. Flush가 발생하면, 그 시점까지 INSERT될 엔티티, UPDATE된 엔티티, DELETE될 엔티티에 대한 SQL 문이 생성되어 DB에 전송됩니다. 여기서 중요한 점은 Flush = 트랜잭션 Commit이 아니라는 것입니다. Flush는 단지 SQL을 실행하여 데이터베이스의 내용물을 업데이트할 뿐이며, 트랜잭션을 실제로 확정짓는(commit) 것은 별도의 단계입니다. 따라서 flush 이후에도 트랜잭션은 열려 있고, 예외가 발생하면 언제든 롤백할 수 있습니다. 반대로, Commit을 수행하면 내부적으로 남은 변경사항을 모두 flush한 뒤 트랜잭션을 확정하여 변경 내용을 영구히 저장합니다 (커밋이 성공한 이후에는 롤백이 불가능합니다).
Flush는 다음과 같은 시점에 발생합니다:
- 트랜잭션 커밋 시 –
commit()을 호출하면 JPA 구현체가 자동으로 flush를 수행한 후 커밋을 진행합니다. 개발자가 flush를 직접 호출하지 않더라도, 커밋 시에는 항상 flush가 일어납니다. - 명시적 Flush 호출 –
em.flush()또는 HibernateSession.flush()를 호출하여 프로그래머가 강제로 flush를 수행할 수 있습니다. 이 경우 즉시 영속성 컨텍스트의 변경 내용이 DB에 반영됩니다. - 쿼리 실행 전 (자동 Flush) – JPA의 기본 flush 모드인
AUTO에서는 중요한 쿼리 실행 전에 자동으로 flush가 일어날 수 있습니다. 예를 들어 영속성 컨텍스트에 아직 DB에 반영되지 않은 변경사항이 있는 상태에서 JPQL/Criteria 쿼리를 실행하면, JPA는 그 쿼리가 최신 데이터를 기반으로 수행되도록 쿼리 전에 flush를 트리거합니다. 이렇게 하면 “내가 작성한 변경사항을 내가 실행하는 쿼리에서 바로 조회”해도 일관성이 유지됩니다 (이를 Read-Your-Own-Writes 일관성이라고 합니다). - 이 외에도, 영속성 컨텍스트가 가득 차는 경우나 엔티티 관계상 cascade 옵션에 의한 전파 시에도 flush가 발생할 수 있지만, 일반적인 시나리오에서는 위의 세 가지가 핵심 flush 트리거입니다.
Flush 모드는 JPA와 Hibernate에서 flush 시점을 조절하는 설정입니다. JPA 표준에서는 FlushModeType.AUTO (기본값)와 FlushModeType.COMMIT 두 가지를 제공하며, Hibernate는 추가로 ALWAYS, MANUAL 등의 모드를 지원합니다. 일반적으로:
- AUTO 모드: 커밋 시 flush는 물론이고, 쿼리 실행 시에도 자동 flush가 일어날 수 있습니다. JPA 구현체가 알아서 일관성 유지를 위해 필요한 경우 flush를 수행합니다.
- COMMIT 모드: 쿼리 실행 시에는 flush를 하지 않고, 오직 트랜잭션 커밋할 때만 flush를 수행합니다. 개발자가 수동으로 flush를 호출하지 않는다면, 중간에 DB와 동기화하지 않고 메모리에만 변경을 유지하다가 커밋 직전에 한꺼번에 반영합니다.
- (Hibernate 전용) ALWAYS: 쿼리 실행 여부와 관계없이 매 쿼리 실행 전에 항상 flush합니다.
- (Hibernate 전용) MANUAL: 자동 flush를 완전히 비활성화하고, 오로지 수동 flush 호출에만 의존합니다.
⠀대부분의 애플리케이션에서는 기본 값인 AUTO를 사용하지만, 특정 상황에서는 FlushModeType.COMMIT로 변경하여 불필요한 flush를 방지하기도 합니다. Flush 모드에 따른 성능 및 일관성 이슈는 아래 최적화 및 성능 고려 사항에서 자세히 다루겠습니다.
Flush 메커니즘 동작 예시 (Hibernate 기준)
MySQL 8.0(InnoDB)와 Hibernate(JPA 구현체)의 동작을 예로 들어, flush와 커밋이 어떻게 작동하는지 살펴보겠습니다. 아래 코드는 하나의 트랜잭션에서 엔티티를 수정하고 flush와 commit을 수행하는 과정입니다 (Hibernate show_sql 설정을 켜두면 어떤 SQL이 언제 실행되는지 확인할 수 있습니다).
EntityManager em = emf.createEntityManager();
em.getTransaction().begin(); // 트랜잭션 시작 (auto-commit 모드 off)
// 1. 엔티티 조회 및 변경 (쓰기 지연 발생)
User user = em.find(User.class, 1L); // SELECT 쿼리 실행 (DB 조회)
user.setEmail("new-email@example.com"); // 엔티티 상태 변경 (메모리만 변경)
System.out.println("flush 전: DB에는 아직 변경 반영 전");
// 2. flush 호출로 DB 동기화 (SQL 실행되지만 commit 전이라 트랜잭션 내 상태)
em.flush(); // UPDATE 쿼리 실행 (DB에 변경사항 전송)
System.out.println("flush 후: 트랜잭션은 열려있고, 변경사항은 DB에 반영되었으나 미커밋");
// (다른 로직 수행 가능 - 필요한 경우 이 시점에 DB에서 select 해도 new-email을 읽음)
// 3. 트랜잭션 커밋 (flush가 자동 발생하고 트랜잭션 확정)
em.getTransaction().commit(); // 커밋 시점에 최종 flush 수행 후 commit
System.out.println("commit 후: 트랜잭션 종료 및 변경사항 영구 확정");
// 4. EntityManager 종료
em.close();위 코드에서, user.setEmail(...)을 호출해 엔티티를 변경했을 때 즉시 DB에 UPDATE 문을 보내지 않고 영속성 컨텍스트에 변경사항이 적재된 것에 주목하세요. em.flush()를 호출하기 전까지는 DB에는 아무 변화가 없습니다. em.flush()를 호출하면 Hibernate가 UPDATE User ... SET email='new-email@example.com' ... SQL을 실행하여 현재 트랜잭션의 변경 내용을 DB에 반영합니다. 그러나 이 시점에도 트랜잭션이 커밋되지 않았으므로 해당 변경은 다른 트랜잭션에는 보이지 않습니다. 마지막에 commit()을 호출하면, Hibernate는 혹시 남은 변경사항이 있다면 flush를 한 번 더 수행하고 (예: flush 호출을 생략한 경우 이때 flush됨), 데이터베이스에 트랜잭션 커밋을 실행합니다. 커밋이 성공하면 해당 변경은 영구 적용되고, 비로소 다른 트랜잭션에서도 새로운 이메일 값을 조회할 수 있게 됩니다.
이 예제에서 flush 후 commit 전까지의 사이에, 만약 별도의 세션/트랜잭션에서 동일한 데이터를 조회한다면 어떻게 될까요? MVCC 격리 덕분에 그 다른 트랜잭션은 여전히 예전 이메일 값을 보게 됩니다. 즉, flush로 DB에 반영은 되었지만 미커밋 상태의 변경은 다른 트랜잭션의 일관적 읽기에 포함되지 않습니다. 이러한 동작이 가능한 것은 DB 수준에서 MVCC가 트랜잭션 격리를 보장하고 있기 때문입니다. 반대로 현재 트랜잭션 내부에서는 flush 이후 즉시 DB에 반영되었기 때문에, 영속성 컨텍스트나 DB를 통해 조회하더라도 새 이메일 값이 보입니다. JPA/Hibernate는 1차 캐시를 통해 애플리케이션 레벨에서도 repeatable read를 제공하므로, flush를 호출하지 않더라도 같은 트랜잭션 내에서는 user 엔티티의 변경된 값을 계속 일관되게 볼 수 있습니다. 요약하면, flush는 현재 트랜잭션에 한해서 변경내용을 DB와 동기화하며, MVCC는 그 변경이 커밋되기 전까지 다른 트랜잭션에는 보이지 않도록 차단해주는 것입니다.
3. MVCC와 JPA 쓰기 지연의 관계
앞서 살펴본 개념들을 바탕으로, 왜 MVCC가 있기 때문에 JPA의 쓰기 지연 전략이 가능한지를 정리해보겠습니다. 핵심은 “격리”입니다. JPA/Hibernate가 엔티티 변경을 즉시 DB에 반영하지 않고 모아서 두었다가 나중에 SQL을 실행하더라도, 데이터의 일관성과 격리가 깨지지 않는 이유는 DB 자체가 MVCC로 트랜잭션 격리를 관리해주기 때문입니다.
동일 트랜잭션 내 일관성: 영속성 컨텍스트(1차 캐시)는 현재 트랜잭션에서 변경된 엔티티들을 캐시하고 있기 때문에, 애플리케이션은 항상 자기 자신이 한 변경을 읽을 때 일관된 결과를 얻습니다. 예를 들어 트랜잭션 내에서 User 엔티티의 이메일을 바꾸고 나서 다시 그 User를 조회하면, 아직 flush를 하지 않았더라도 1차 캐시에 있는 변경된 엔티티를 돌려주므로 항상 변경된 최신 값을 보게 됩니다. 이를 Application-level Repeatable Read라고 부르기도 하는데, Hibernate의 1차 캐시가 내부적으로 “내가 쓴 건 내가 읽는다”를 보장해주기 때문입니다. 이러한 동작은 JPA 쓰기 지연 전략의 전제 조건이 됩니다. 즉, 굳이 즉각 DB에 쓰지 않아도, 트랜잭션 내부에서는 모순 없이 데이터 일관성을 유지할 수 있다는 것이죠.
트랜잭션 격리와 가시성: JPA가 데이터베이스에 실제 SQL을 늦게 보내더라도, 다른 트랜잭션들은 이 변경을 볼 수 없으므로 문제없다는 점이 중요합니다. MVCC로 관리되는 RDBMS에서는, 어떤 트랜잭션의 변경이 커밋되기 전까지는 절대 다른 트랜잭션에서 보이지 않습니다. 즉, A 트랜잭션에서 여러 객체를 막 변경하고 있어도 B 트랜잭션은 A가 커밋하기 전에는 기존 커밋된 데이터만 읽게 되므로 A의 미커밋 변경으로 인한 Dirty Read 현상은 발생하지 않습니다. 이런 보장이 있기 때문에 JPA는 한 트랜잭션 내에서 여러 변경을 모았다가 지연 실행해도 안전한 것입니다. Hibernate 자료에서도 “flush된 변경 내용은 오직 현재 DB 트랜잭션에만 보이며, 트랜잭션이 커밋되기 전에는 어떤 다른 트랜잭션에게도 보이지 않는다”라고 명시하고 있습니다. 실제로 flush를 여러 번 하더라도 커밋 전까지는 그 변경들이 모두 트랜잭션 경계 안에 격리되어 있는 셈입니다.
MVCC의 역할: flush 시점에 Hibernate가 SQL을 실행하면, 데이터베이스(InnoDB)는 해당 변경에 대해 잠금과 버전 관리를 적용합니다. 예를 들어, UPDATE SQL이 flush로 인해 실행되면 InnoDB는 대상 행(row)에 배타적 잠금(X Lock)을 걸고 새로운 버전을 생성하지만, 그 트랜잭션이 끝날 때까지는 해당 변경을 커밋 보류 중인 상태로 유지합니다. 다른 트랜잭션이 동일한 행을 읽으면, 이 커밋되지 않은 버전을 무시하고 Undo 로그를 통해 이전 버전을 읽게 되므로 여전히 일관된 이전 상태를 보게 됩니다. 또한 다른 트랜잭션이 운 나쁘게 동일 행을 수정하려 한다면, 앞선 트랜잭션이 잡고 있는 잠금 때문에 대기하게 됩니다. 이는 MVCC 이전의 로킹 기법과 동일하게 동작하지만, 읽기 작업에 대해서는 잠금이 필요 없도록 MVCC가 버전으로 해결해 주는 것입니다. 정리하면, MVCC는 JPA/Hibernate의 쓰기 지연으로 인해 트랜잭션 내부에서 변경이 늦게 DB에 반영되더라도 외부 격리를 지켜주고, flush로 중간에 SQL이 실행되어도 그 트랜잭션이 끝날 때까지 변경을 다른 트랜잭션과 격리시켜 줍니다.
예시 시나리오: 간단한 시나리오로, 트랜잭션 A와 트랜잭션 B 두 개가 있고 동일한 데이터를 다룬다고 가정해보겠습니다.
- 트랜잭션 A는 엔티티를 조회하여 값을 변경했지만 아직 flush나 commit을 하지 않고 있습니다 (JPA 영속성 컨텍스트에만 변경 저장).
- 트랜잭션 B가 동시에 그 데이터를 조회하면, 트랜잭션 A의 변경은 커밋되지 않았으므로 트랜잭션 B는 예전 값을 읽습니다. (MVCC에 의해 A의 미커밋 버전은 B에게 보이지 않음)
- 이후 트랜잭션 A가 flush를 수행하여 변경내용을 DB에 보냈다고 해도, 트랜잭션 A가 commit을 하기 전이라면 트랜잭션 B는 여전히 변화가 없는 기존 버전을 보게 됩니다.
- 트랜잭션 A가 최종적으로 commit하면, 그제서야 해당 변경이 공식적인 커밋된 버전으로 확정되고, 이후의 트랜잭션들은 새 값을 읽게 됩니다. 트랜잭션 B가 REPEATABLE READ 격리 수준으로 이미 읽고 있었다면, B는 자기 트랜잭션이 끝날 때까지도 계속 예전 값만 볼 수도 있습니다.
⠀위 시나리오에서 보듯이, MVCC는 JPA의 지연된 SQL 실행이 문제를 일으키지 않도록 뒷받침해줍니다. 또한 이러한 설계 덕분에 Hibernate는 가능한 한 flush를 지연하여 DB 락 점유 시간을 줄이고, 배치 작업 최적화를 꾀할 수 있습니다. (예: 나중에 한 번에 flush하면서 JDBC 배치를 사용하면 다수의 DML을 한 번에 보내 효율을 높일 수 있습니다.)
4. 최적화 및 성능 고려 사항
JPA의 쓰기 지연과 MVCC 조합은 성능상 많은 이점을 주지만, 잘못 활용하면 오히려 성능 문제나 데이터 일관성 문제가 발생할 수 있습니다. 이번에는 flush 전략과 트랜잭션 지속 시간 측면에서 고려해야 할 최적화 포인트와 주의사항을 정리해보겠습니다.
Flush 빈도와 성능 최적화
너무 잦은 Flush: flush는 변경 내용을 DB에 동기화하는 작업이므로 DB I/O 부하와 잠금 오버헤드를 발생시킵니다. 기본 flush 모드 AUTO에서는 쿼리 실행 전에 flush가 일어날 수 있는데, 트랜잭션 안에서 쿼리가 빈번히 실행되면 flush도 빈번하게 발생할 수 있습니다. 예를 들어, 어떤 복잡한 비즈니스 로직이 엔티티를 여기저기 수정하면서 여러 차례 JPQL 쿼리를 수행한다면, 불필요하게 여러 번 flush하여 같은 엔티티를 반복해서 DB에 쓰는 낭비가 있을 수 있습니다. Flush가 과도하면 그만큼 네트워크 왕복 횟수와 DB 쓰기 작업이 증가하여 성능을 떨어뜨릴 수 있으므로 주의해야 합니다.
너무 드문 Flush: 한편 flush를 너무 드물게 (또는 아예 하지 않고) 몰아서 한 번에 하도록 설정할 수도 있습니다. FlushModeType.COMMIT으로 설정하면 커밋 시에만 flush하므로, 중간 단계 쿼리들은 영속성 컨텍스트의 변경사항을 반영하지 않고 DB를 조회하게 됩니다. 이는 성능 측면에서는 중간 flush가 없으니 유리하지만, 논리적 오류를 유발할 수 있습니다. 예를 들어, flush 모드를 COMMIT로 해놓고 트랜잭션 중간에 JPQL로 DB를 조회하면, 이미 메모리엔 변경되어 있는 데이터에 대해 아직 DB에는 옛 값이 있으므로 그 쿼리는 예전 데이터를 기준으로 실행될 것입니다. 이로 인해 엔티티의 상태와 쿼리 결과가 불일치하는 문제가 생길 수 있습니다. 따라서 flush 모드를 조정할 때는 해당 트랜잭션에서 쿼리들이 내 변경사항을 알아야 하는지를 고려해야 합니다. 일반적으로 flush 모드를 COMMIT로 사용하는 경우, 트랜잭션 동안 수정 후 조회를 하지 않거나, 조회를 하더라도 수정된 데이터와 무관한 조회를 하는 시나리오여야 안전합니다.
FlushMode 설정 전략: flush 빈도를 조절하려면 위에서 언급한 FlushModeType을 적절히 활용하면 됩니다. 예를 들어 대량의 엔티티를 처리하는 배치 작업에서는, 중간에 특별히 조회쿼리를 실행하지 않는다면 FlushModeType.COMMIT로 설정해두고 필요할 때만 수동 flush를 호출하는 편이 효율적일 수 있습니다. 반대로, 사용자가 입력한 데이터를 검증하기 위해 즉시 쿼리로 확인해야 하는 경우 등은 기본값인 AUTO가 안전합니다. 또한 Hibernate 확장 모드인 ALWAYS는 거의 모든 쿼리 전에 flush하므로 일관성은 철저히 지키지만 성능 비용이 크므로 잘 사용되지 않습니다. 반대로 MANUAL 모드는 자동 flush를 완전히 끄는 것인데, 이 경우 개발자가 직접 flush 호출을 누락하면 데이터베이스와 영속성 컨텍스트 간 상태 불일치가 생길 수 있으므로 주의해야 합니다.
불필요한 Flush 피하기와 Batch 처리
불필요한 Flush 줄이기: flush는 기본적으로 Hibernate가 자동으로 처리해주지만, 개발자도 flush가 언제 발생하는지 알고 신경 써야 불필요한 flush를 줄일 수 있습니다. 위에서 말한 flush 모드 조정이 한 방법이고, 또 다른 방법은 쿼리와 변경 작업의 순서를 고려하는 것입니다. 가능하면 트랜잭션 내에서 변경 작업(엔티티 수정/등록/삭제)을 모두 마친 후에 필요한 조회 쿼리를 실행하거나, 반대로 조회 쿼리를 다 끝낸 후에 엔티티를 변경하는 식으로 순서를 구성하면 중간 flush 발생을 줄일 수 있습니다. 만약 JPA 표준 JPQL 혹은 네이티브 SQL로 복잡한 조회를 해야 하는데 flush로 인한 성능 저하가 우려된다면, FlushModeType.COMMIT로 설정하여 flush 없이 조회하는 방법도 고려할 수 있습니다 (이 경우 1차 캐시와 DB 간 데이터 차이를 개발자가 인지하고 있어야 합니다).
배치 처리와 Flush/Clear: JPA/Hibernate를 사용하다 보면 대용량 데이터 적재나 업데이트를 트랜잭션 하나에서 처리해야 하는 경우가 있습니다. 예를 들어 수만 건의 레코드를 CSV에서 읽어와 DB에 INSERT 한다고 가정하면, 쓰기 지연으로 모두 메모리에 쌓아두었다가 한 번에 flush하면 메모리 사용량이 매우 커지고 성능도 저하될 수 있습니다. 이러한 경우 주기적으로 flush를 수행하고 1차 캐시를 비워주는 것이 좋습니다. Hibernate에서는 관례적으로 배치 크기를 정해서, 일정 수 이상의 엔티티를 처리하면 session.flush()와 session.clear()를 호출합니다. 예를 들어 1000건마다 flush/clear하면, 한 번에 1000건씩 INSERT SQL을 배치로 보내고 1차 캐시를 비워 메모리 점유를 낮출 수 있습니다. 이 방법은 OutOfMemoryError 방지에도 효과적이며, DB 입장에서도 한 트랜잭션에서 너무 많은 변경을 몰아서 커밋하는 것보다는 중간중간 나눠 커밋하는 편이 부하 관리에 도움이 됩니다. 단, 이러한 중간 커밋은 애플리케이션 로직상 데이터 일관성에 문제가 없는 범위에서 해야 합니다 (예: 완전히 별개의 레코드들에 대한 작업일 때).
Long Transaction(장기 트랜잭션) 이슈
JPA 쓰기 지연 + MVCC 조합에서 흔히 간과하기 쉬운 문제가 트랜잭션을 오래 유지하는 것입니다. 트랜잭션을 길게 유지하면 애플리케이션 레벨에서는 편할지 몰라도, DB 레벨에서는 여러 가지 부작용이 나타납니다.
Undo 로그 증가: 트랜잭션이 활성화된 동안 변경 전 데이터 버전들을 Undo 로그에 보관해야 합니다. 만약 어떤 트랜잭션이 오래 지속되면, 그 트랜잭션이 시작된 이후 커밋된 모든 다른 트랜잭션의 이전 버전 정보를 유지해야 할 수도 있습니다. 이는 롤백 세그먼트(rollback segment)가 점점 커지고, Undo 테이블스페이스가 비대해지는 결과를 낳습니다. MySQL 문서에서도 “커밋을 주기적으로 수행하지 않으면 Undo 로그 데이터를 삭제하지 못해 계속 커지고, Undo 테이블스페이스를 가득 채울 수 있다”고 경고합니다. 즉, 오래 열려있는 트랜잭션 하나가 전체 DB 성능에 악영향을 줄 수 있습니다.
Lock 지속 및 교착상태 위험: 트랜잭션이 변경을 수반하는 경우, 해당 데이터에 대한 락(잠금)을 트랜잭션 종료 시까지 쥐고 있게 됩니다. 트랜잭션이 짧으면 락 보유 시간도 짧아져 다른 트랜잭션들과 충돌 가능성이 줄지만, 길어지면 그만큼 다른 트랜잭션들이 기다려야 할 확률이 높아지고 교착상태(deadlock)도 발생하기 쉽습니다. 예를 들어 트랜잭션 A가 어떤 행을 업데이트하고 10분간 대기하고 있다면, 그 행에 업데이트하려던 트랜잭션 B는 10분간 대기하거나 타임아웃될 것입니다. MVCC가 읽기에는 이전 버전을 제공해주지만, 쓰기 락 충돌은 결국 해결을 미룰 수 없기 때문에 트랜잭션 시간을 불필요하게 끌지 않는 것이 중요합니다.
애플리케이션 레벨 부작용: 사용자 요청에 의해 시작된 트랜잭션을 너무 오래 유지하면, 데이터 변경에 연관된 자원도 오래 붙잡아두는 결과를 낳습니다. 일반적으로 웹 애플리케이션에서는 하나의 HTTP 요청 단위로 트랜잭션을 처리하는데, 만약 특정 요청에서 트랜잭션을 시작한 후 사용자의 추가 입력과 같은 외부 이벤트를 기다리는 구조라면 바람직하지 않습니다. 따라서 트랜잭션은 가능한 짧게 유지하고, 필요한 작업이 완료된 즉시 커밋 또는 롤백하여 자원을 신속히 반환하는 것이 좋습니다.
데이터 변경에 연관된 자원들에는 다음과 같은 것들이 있습니다:
- 데이터베이스 커넥션 풀 (DB Connection Pool)
- 트랜잭션 동안 DB 연결이 계속 유지됩니다.
- 쓰레드(Thread) 자원
- 일반적으로 트랜잭션은 애플리케이션의 특정 쓰레드에서 처리되므로, 트랜잭션이 길면 쓰레드도 오랜 시간 묶이게 됩니다.
- ⠀메모리 자원 (영속성 컨텍스트 및 캐시)
- JPA의 영속성 컨텍스트(1차 캐시)는 트랜잭션과 함께 유지되기 때문에, 긴 트랜잭션 동안 엔티티가 계속 메모리에 남아있어 메모리 사용량이 증가할 수 있습니다.
- 트랜잭션 관리 자원(Transaction Manager)
- 트랜잭션 관리 컴포넌트가 트랜잭션 상태를 오래 관리해야 하므로 시스템 부하가 증가합니다.
- 애플리케이션 로직 내의 잠금(Lock) 자원
- 특정 애플리케이션에서 데이터 정합성을 위해 애플리케이션 레벨의 명시적 락(예: Java 내 ReentrantLock, 분산 락)을 사용할 경우, 긴 트랜잭션 동안 이런 락들도 함께 점유됩니다.
요약하면, JPA의 쓰기 지연 전략은 짧은 트랜잭션에서 최대의 효과를 발휘합니다. 트랜잭션이 짧으면 영속성 컨텍스트에서 모았던 변경을 한 번에 flush하고 끝내기가 좋고, DB 측면에서도 MVCC 버전 관리나 잠금 유지 부담이 적습니다. 가능하다면 작은 단위로 트랜잭션을 분할하고, 불가피하게 트랜잭션이 길어질 경우 주기적으로 상태를 점검하여 flush/commit을 수행하는 것이 좋습니다. MySQL InnoDB에서는 오래된 트랜잭션을 경계해야 함을 기억하세요 (예: SHOW ENGINE INNODB STATUS로 오래된 트랜잭션 모니터링 등).
결론
JPA/Hibernate의 쓰기 지연(write-behind)과 RDBMS(InnoDB)의 MVCC는 서로 조화를 이루어 동작합니다. MVCC가 보장하는 트랜잭션 격리 덕분에, JPA는 한 트랜잭션 내에서 변경사항을 모아두었다가 flush 시점에 일괄 DB 동기화를 해도 데이터 일관성을 해치지 않을 수 있습니다. 이로써 애플리케이션은 엔티티를 자유롭게 변경하고, Hibernate는 가능한 늦게까지 SQL 생성을 미뤄 배치 최적화나 락 경쟁 감소 같은 이점을 얻습니다.
물론 이러한 편의성은 개발자가 트랜잭션과 flush 메커니즘을 정확히 이해하고 사용할 때 극대화됩니다. 트랜잭션 관리 모범 사례를 몇 가지 기억해 둡시다:
- 트랜잭션을 필요 이상으로 길게 유지하지 말 것: 짧은 트랜잭션으로 빠르게 커밋하여 MVCC로 인한 저장 공간 낭비와 잠금 홀딩을 최소화합니다.
- Flush 모드와 시점을 명확히 인지할 것: 자동 flush의 동작을 이해하고, 필요하면
FlushModeType을 조절하여 불필요한 flush를 줄이세요. 단, 그로 인해 발생할 수 있는 일관성 문제에 대비해야 합니다. - 일관성 필요한 시점에는 수동 Flush: 외부 시스템과 연계하거나 JPA 외부에서 DB 접근이 함께 이뤄지는 경우, 적절한 시점에
em.flush()를 호출하여 데이터베이스와 동기화하고 진행하는 것이 안전합니다. 예를 들어, JPA로 일부 변경 후 JDBC를 직접 호출해 프로시저를 실행해야 한다면, 먼저 flush를 해서 DB에 반영하고 프로시저를 호출하는 것이 일관성에 좋습니다. - 대량 작업 시 메모리 관리: 수천 건 이상의 엔티티를 처리해야 한다면, flush 주기를 조절하고 clear()를 병행하여 1차 캐시 메모리 누수를 방지하세요. 필요하면 작업을 여러 트랜잭션으로 분할해 처리하는 것도 고려합니다.
현대의 RDBMS는 MVCC를 통해 높은 수준의 격리를 제공하고 있고, Hibernate 같은 ORM은 이를 효과적으로 활용하여 개발 생산성과 성능 두 마리 토끼를 잡으려 합니다. 이 글에서 살펴본 개념들을 이해하면, 트랜잭션과 영속성 컨텍스트를 다루는 실무 코드에서 발생하는 미묘한 문제들 (예: “내가 분명 엔티티를 수정했는데 쿼리 결과에 반영이 안 된다”거나 “트랜잭션을 안 끊고 오래 유지했더니 DB가 버벅인다” 같은) 을 쉽게 진단하고 해결할 수 있을 것입니다. 트랜잭션 관리의 모범 사례를 항상 염두에 두고, JPA와 DB의 동작 원리를 이해하며 코드를 작성하면, 안정성과 성능을 모두 갖춘 애플리케이션을 구축할 수 있습니다.
