알고리즘 - 기사 단원의 무기
- 출처 : 프로그래머스

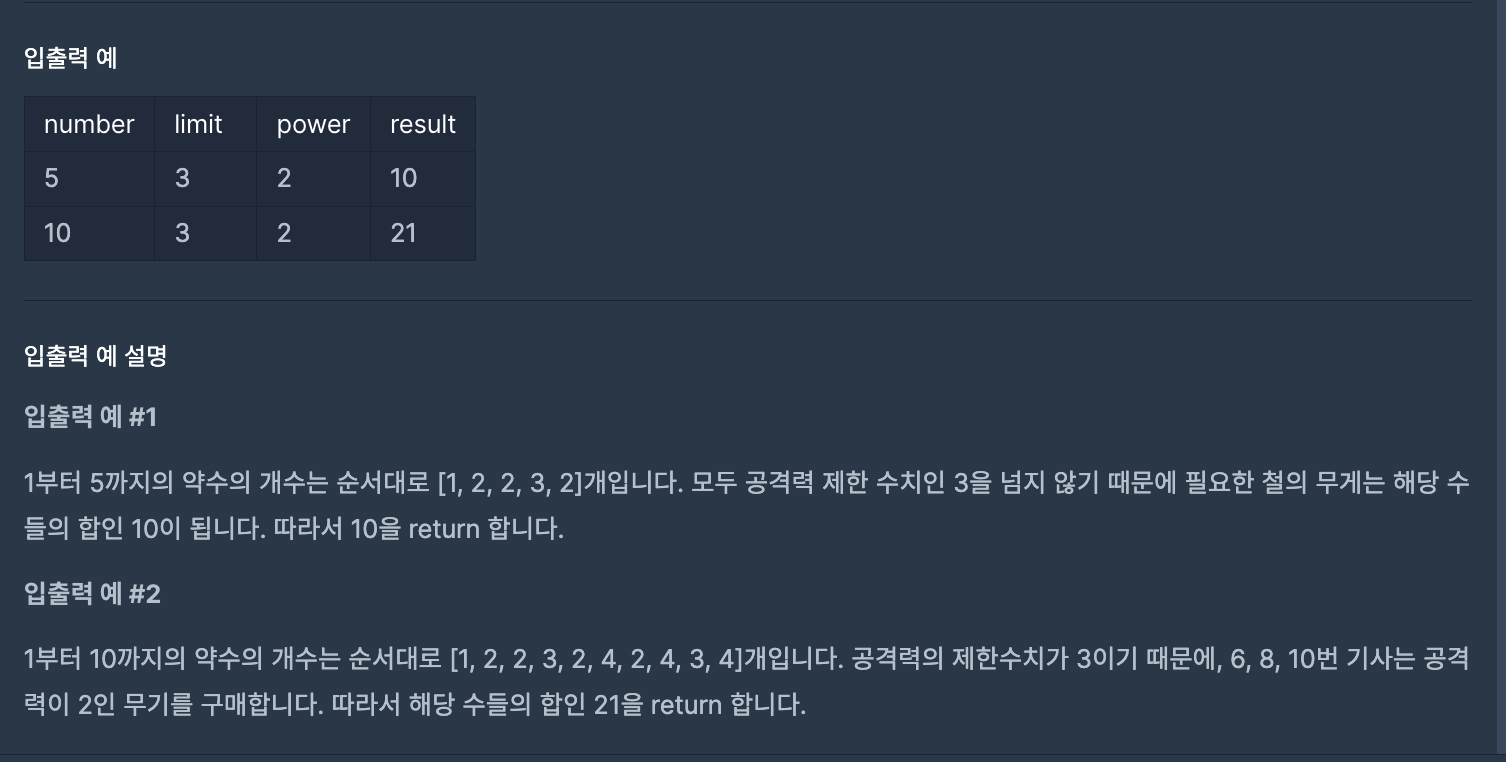
🧚
약수의 갯수를 얼마나 효율적으로 계산할지가 관건인 문제이다.
문제의 개념은 간단했지만 저 "효율적"에 애를 먹었던 문제이다.
처음에는 약수의 갯수를 구하기 위해 해당하는 숫자까지 전부 순회를 하였다.
하지만 이는 시간 초과를 마주하게 만들었고
시간 초과를 마주하지 않을, 순회를 덜 하는 코드가 필요했다.
처음에는 limit를 넘어가는 숫자는 break하게 해서 초과를 낮춰야 하나? 생각해 break문을 넣어주었지만 그 정도의 시간 초과가 문제가 아니었다.
해결한 아이디어는 간단했다.
약수를 만들어내는 특성 중 하나인 "쌍"을 이용하는 것이다.
따라서 애초에 반복문의 끝을 해당하는 숫자가 아닌 그 half까지만 돌게 하여 count를 하는 것이다.
약수의 갯수를 효율적이게 구하는 문제를 종종 본 기억이 있는데 툭 누르면 우다다다 나오게 기억해야겠다.
📌
def solution(number, limit, power):
answer = 0
number_list = []
for one in range(1, number+1):
cnt = 0
# 제곱근을 구하는 코드
half = int(one ** 0.5)
for j in range(1, half+1):
if one % j == 0:
# 구한 제곱근이 정수일 경우는 count를 하나만 해야 함
if j ** 2 == one:
cnt += 1
# 정수가 아닐 경우에는 쌍이 있는 경우이므로 2번 count를 해주어야 함
else:
cnt += 2
number_list.append(cnt)
for attack in number_list:
if attack > limit:
answer += power
else:
answer += attack
return answer넷플릭스 리뷰를 바탕으로 한 평점 예측 LSTM 모델
import
# 데이터 분석용 라이브러리
import pandas as pd
import numpy as np
# 딥러닝을 위한 라이브러리
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 언어 모델 생성을 위한 라이브러리
# 문장에서 단어들을 나눠주는 라이브러리
from torchtext.data.utils import get_tokenizer
# 영문 단어들을 숫자로 바꿔주는 라이브러리
from torchtext.vocab import build_vocab_from_iterator 구두점 및 문장 전처리
- 작은 따옴표는 유지해봄
import re
def preprocess_text(text):
if isinstance(text, float):
return ""
text = text.lower() # 대문자를 소문자로
text = re.sub(r"[^\w\s']", '', text) # 작은따옴표는 유지, 나머지 구두점 제거
text = re.sub(r'\d+', '', text) # 숫자 제거
text = text.strip() # 띄어쓰기 제외하고 빈 칸 제거
return text- 적용
data["content"] = data["content"].apply(preprocess_text)
data["content"]테스트 & 학습용 데이터 분리
# 이때 그냥 data["컬럼"] 의 경우에는 Series의 형태이므로 list 변환을 해주어야 함
X = data["content"].tolist()
y = data["score"].tolist()
train_reviews, test_reviews, train_ratings, test_ratings = train_test_split(X, y, test_size=0.2, random_state=42)
# 토큰 생성 (영어 문장에서 단어들을 분리해줌)
tokenizer = get_tokenizer('basic_english')
# 여러 문장들 가운데 문장에서 토큰화를 진행해주는 메서드
# 해당 메서드가 필요한 이유는 사전에 단어집을 생성해주는 작업을 하기 떄문임
def yield_tokens(sentences):
for sentence in sentences:
yield tokenizer(sentence)
# 여러 문장들 속 단어들을 이용해 단어집을 만들어주는 코드임
# 즉 이 단계에서 train_reviews의 단어들은 이미 단어집으로 만들어졌다는 말이다.
vocab = build_vocab_from_iterator(yield_tokens(train_reviews), specials=['<UNK>'])
vocab.set_default_index(vocab['<UNK>'])
# 날 것으로 받은 review(구두점이나 다른 이모지가 포함되어 있는...) 을
# 1. 단어 분리 후
# 2. 단어집 속 해당 단어가 있는지 확인한 후 해당하는 숫자 배열로 바꿔주는 파이프 라인임
def text_pipeline(setence):
return [vocab[token] for token in tokenizer(sentence)]
# 1부터 시작하는 raiting을 학습을 위해 -1 시켜주는 파이프라인임
def label_pipeline(raiting):
return int(raiting) - 1Dataset
- 해당 클래스를 거친 후 raw한 리뷰와 score 는 비로소 같은 형태가 되는 것임
- 리뷰 : str -> long
- 평점 : long (1부터 시작) -> long(0부터 시작)
class ReviewDataset(Dataset):
def __init__(self, reviews, ratings, text_pipeline, label_pipeline):
self.reviews = reviews
self.ratings = ratings
self.text_pipeline = text_pipeline
self.label_pipeline = label_pipeline
def __len__(self):
return len(self.reviews)
def __getitem__(self, idx):
review = self.text_pipeline(self.reviews[idx])
rating = self.label_pipeline(self.ratings[idx])
return torch.tensor(review), torch.tensor(rating)
train_dataset = ReviewDataset(train_reviews, train_ratings, text_pipeline, label_pipeline)
test_dataset = ReviewDataset(test_reviews, test_ratings, text_pipeline, label_pipeline)배치 사이즈 조절
- 각각의 리뷰 문장은 다른 문장 길이를 갖고 있다. 이를 일치시켜주는 작업이다.
- MAX_LEN을 충족하지 못한 문장이 있다면 0으로 채워넣는다.
- 외에도 review와 raiting 타입 일치 작업도 같이 해주고 있다.
- 사실상 배치 사이즈 조절 작업은 review만 해주면 되는데 그 이유는 문장의 경우에만 그 길이가 "가변적"이기 때문임
from torch.nn.utils.rnn import pad_sequence
MAX_LEN = 100
def collate_batch(batch):
reviews, raitings = [], []
for review, raiting in batch:
# 최대 문장길이를 넘어가는 단어는 제거함
truncated_review = review[:MAX_LEN]
# 리뷰와 평점의 타입 일치 작업도 함께 해줌
reviews.append(torch.tensor(truncated_review, dtype=torch.long))
raitings.append(torch.tensor(raiting, dtype=torch.long))
# padding을 주어 짧은 문장에 대한 길이를 맞춤
# 짧은 문장의 경우 남는 자리에는 0으로 채움
# 해당 작업은 평점에는 할 이유가 없다. (한 자리만 존재하기 때문이다.)
padded_reviews = pad_sequence(reviews, batch_first=True, padding_value=0)
return padded_reviews, raitings- 적용
# 데이터 로더 정의
# 배치 단위로 나눠 반복적으로 불러오는 역할을 하는 DataLoader이다.
# 이때 방금 만든 패딩 조절 메서드를 문장에 적용시켜준다.
BATCH_SIZE = 64
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, collate_fn=collate_batch)LSTM 모델
임베딩(embedding) 레이어의 역할:
텍스트 데이터는 보통 단어의 나열로 이루어지며, 이를 그대로 LSTM 같은 신경망에 입력할 수는 없습니다. 신경망 모델은 수치 데이터를 입력으로 받으므로, 단어를 벡터로 변환하는 과정이 필요합니다.
nn.Embedding은 단어 ID(정수 값)를 고정된 길이의 벡터(embedding vector)로 변환해줍니다. 예를 들어 단어 "excellent"가 ID 50으로 매핑된다면, nn.Embedding 레이어는 이 50을 지정된 벡터 차원 (embed_dim)을 가지는 벡터로 변환해줍니다. 이렇게 변환된 임베딩 벡터는 단어의 의미를 어느 정도 반영하도록 훈련 중에 학습됩니다. 즉, 임베딩은 단어 간의 의미적 유사성을 잘 표현할 수 있도록 합니다.
즉 텍스트 데이터를 벡터 변화해주는 역할을 임베딩 레이어가 한다는 것임
그리고 해당하는 임베딩 레이어는 단어집의 사이즈만큼 생성함
그 다음 forward 메서드를 통해 리뷰별로 임베딩 작업을 거치게 됨
output, (hidden, cell) :
LSTM 모델은 입력된 시퀀스를 순차적으로 처리하며, 각 타임스텝마다 단어 정보를 축적합니다. 최종 타임스텝에서의 hidden 상태는 모델이 입력된 전체 문장을 처리한 후 얻어진 결과임
이때 hidden 값은
문맥과 정보를 가장 많이 반영한 벡터임
때문에 hidden 값을 return 하는 것임
+새로 알게 된 사실인데 초기 은닉상태를 정의해주지 않아도 pyTorch의 nn.LSTM은 자동으로 초기값을 설정하고 학습을 진행한다고 함
# LSTM 모델 정의
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):
super(LSTMModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, reviews):
embedded = self.embedding(reviews)
output, (hidden, cell) = self.lstm(embedded) # 단어 정보 축적
return self.fc(hidden[-1]) # 마지막 타임스텝의 출력을 사용 (가장 최상위 벡터)- 적용
# 하이퍼파라미터 수정
VOCAB_SIZE = len(vocab)
EMBED_DIM = 64
HIDDEN_DIM = 128
OUTPUT_DIM = len(set(y))
NUM_EPOCHS = 100
# 모델 초기화
model = GRUModel(VOCAB_SIZE, EMBED_DIM, HIDDEN_DIM, OUTPUT_DIM)
# 손실 함수와 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)모델 학습
# 학습 루프 개선
for epoch in range(NUM_EPOCHS):
model.train()
running_loss = 0.0
for reviews, ratings in train_dataloader:
outputs = model(reviews)
# 기울기 초기화
optimizer.zero_grad()
# 손실 계산
loss = criterion(outputs, ratings)
# 손실 업데이트
loss.backward()
# 가중치 업데이트
optimizer.step()
# 누적 손실
running_loss += loss.item()
print(f'Epoch [{epoch + 1}/{NUM_EPOCHS}], Loss: {running_loss / len(train_dataloader):.4f}')
print('Finished Training')모델 평가
# 예측 함수(예시)
def predict_review(model, review):
model.eval()
with torch.no_grad():
# 첫 번째 차원에 1을 추가한다는 의미
# 이전에 사용해본 unsqueeze(-1)은 마지막 차원에 1을 추가한다는 의미임
tensor_review = torch.tensor(text_pipeline(review), dtype=torch.long).unsqueeze(0)
output = model(tensor_review)
# 가장 높은 예측 확률을 보이는 평점의 인덱스를 반환
prediction = output.argmax(1).item()
return prediction + 1# 새로운 리뷰에 대한 예측
new_review = "This app is terrible."
predicted_score = predict_review(model, new_review)
print(f'Predicted Score: {predicted_score}')근데 EPOCH가 100이라 그런가 진짜 오래 걸림
