AI 부트 캠프 TIL
1.AI 부트캠프 TIL - 1일차

1\. 파이썬의 기본파이썬은 다른 프로그래밍 언어들과는 다르게 인터프리터 언어이다.인터프리터 언어란 무엇인가 하면 한줄씩 컴파일이 들어가는 언어를 말한다. 즉 단계별로 진행이 가능한 프로그래밍 언어이다!(다른 프로그래밍 언어 ex.c++ 같은 경우에는 통으로 사전 컴파
2.AI 부트캠프 TIL - 2일차
1\. 클래스와 객체클래스는 객체를 만들기 위한 청사진이라고 할 수 있으며속성과 메서드로 구성이 된다이때 속성 (Atrribute) 은 클래스에 정의된 변수로, 데이터를 정의하며메서드 (method)는 객체의 동작을 정의한다객체는 클래스의 인스턴스로, 클래스라는 설계도
3.AI 부트캠프 TIL - 3일차
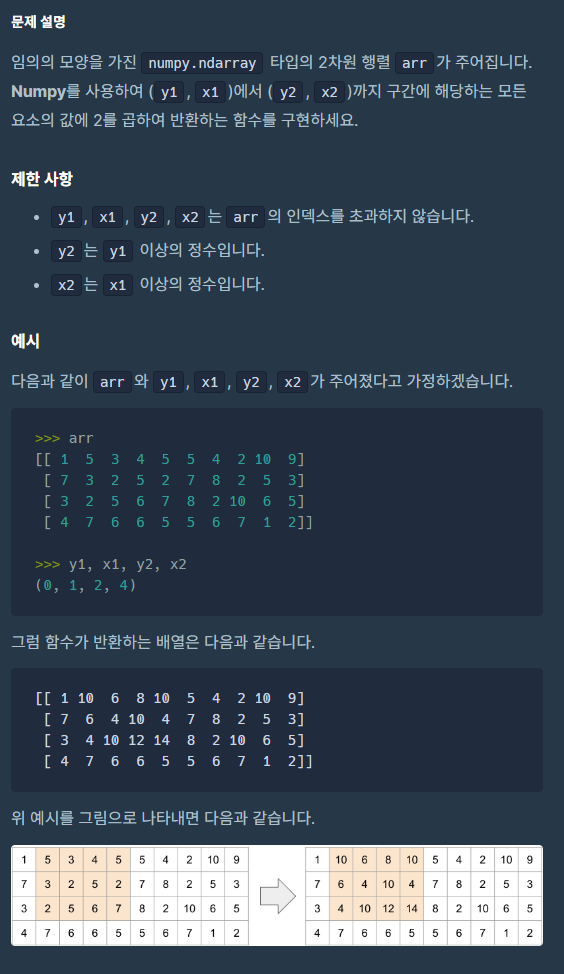
1\. Pandas 실습판다스의 개발 환경은 Jupyter Notebook으로 진행한다.왜 Jupyter Notebook인가 하면 쉘마다 실습이 가능하기 때문에 시각화할 수 있기 때문이다.데이터 프레임데이터 프레임의 형태는 2차원의 표 형태 데이터 구조이다데이터 프레임
4.AI 부트 캠프 - 4일차
1. 판다스에서 데이터 읽기 pd.read_csv("읽을 CSV 파일") 파일이 아닌 URL로부터 직접 바로 다운로드해서 가져올 수도 있음 : pd.read_csv("URL") pd.read_excel("읽을 EXCEL 파일") 특정 sheet를 읽고 싶다면? .h
5.AI 부트캠프 - 5일차
데이터 전처리 > 1. IQR을 사용한 이상치 탐지 IQR은 1사분위 수 (Q1)과 3사분위 수 (Q3)의 차이로, 이 범위를 벗어나는 데이터를 이상치로 간주할 수 있음 나이를 구해야 하는데 0보다 작은 값들이 bound로 나왔다? -> 이상치임 이상치를 구하는
6.AI 부트 캠프 6일차
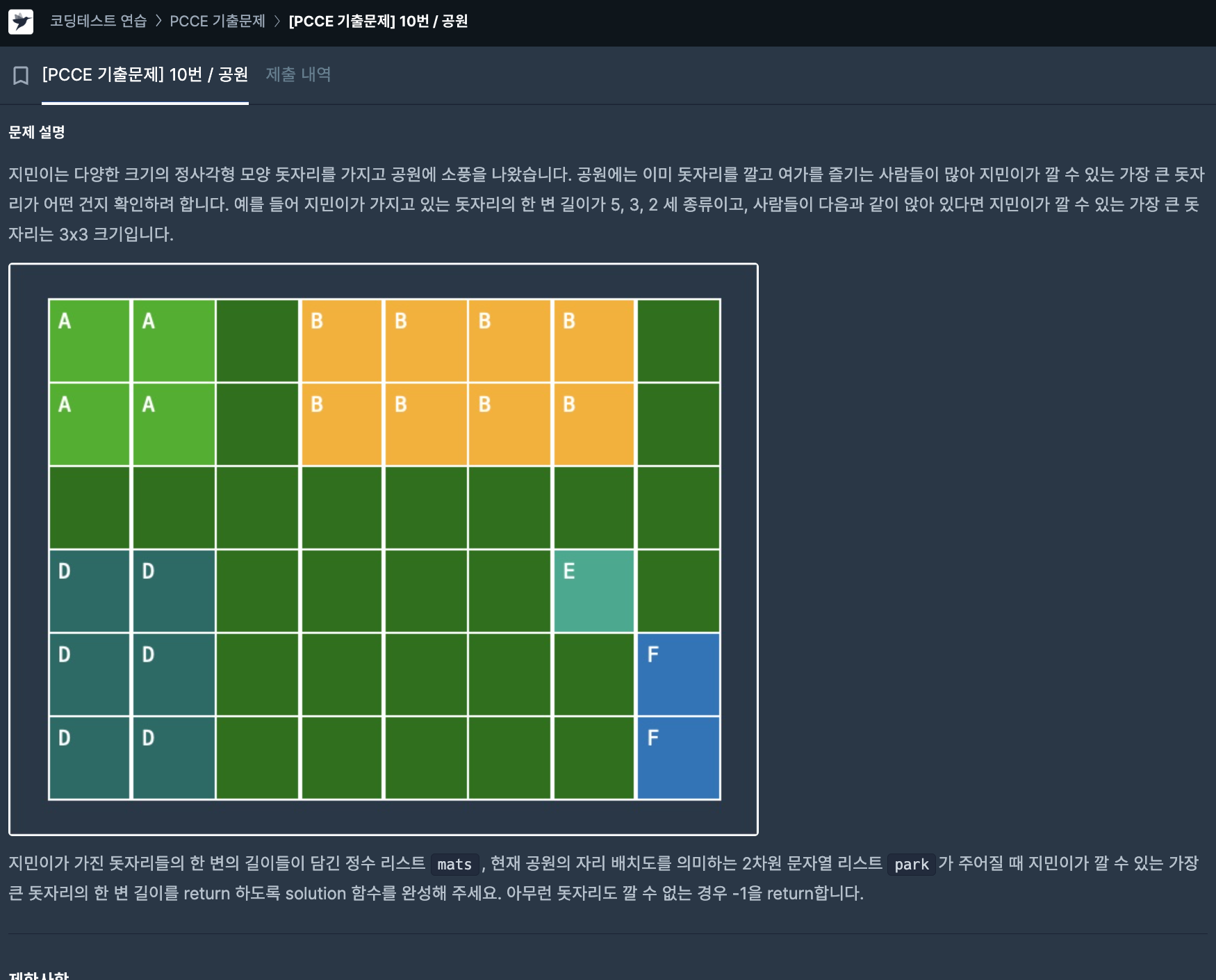
1\. 멀티 인덱스멀티 인덱스는 하나 이상의 인덱스를 사용하여 데이터프레임의 행과 열을 구조화하는 방법이다.이는 다차원 데이터를 보다 효율적으로 관리하고 분석할 수 있게 해준다.1\. set_index()로 멀티 인덱스 설정2\. pd.MultiIndex.from_tu
7.AI 부트 캠프 - 7일차
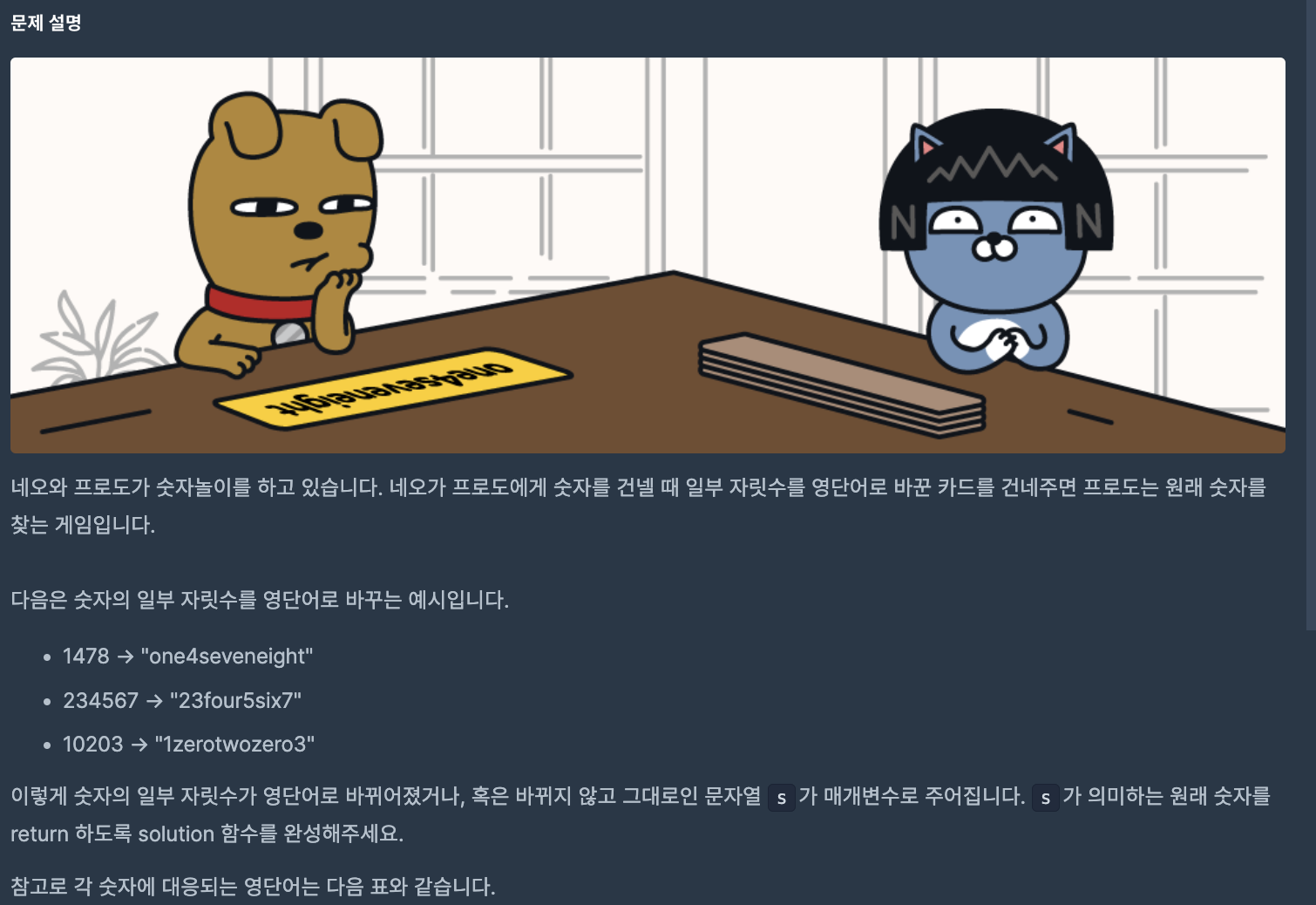
🧚가장 먼저 만든 것은 진짜 숫자와 영문 숫자를 담은 딕셔너리이다. key와 value 접근을 통해 숫자 변환을 할 예정이기 때문이다.First attempt하지만 문자열을 어떻게 o이 아닌 one을 유효한 문자열로 인식하고 나누지? 에 대한 고민이 이어졌다.때문에
8.AI 부트캠프 - 8일차
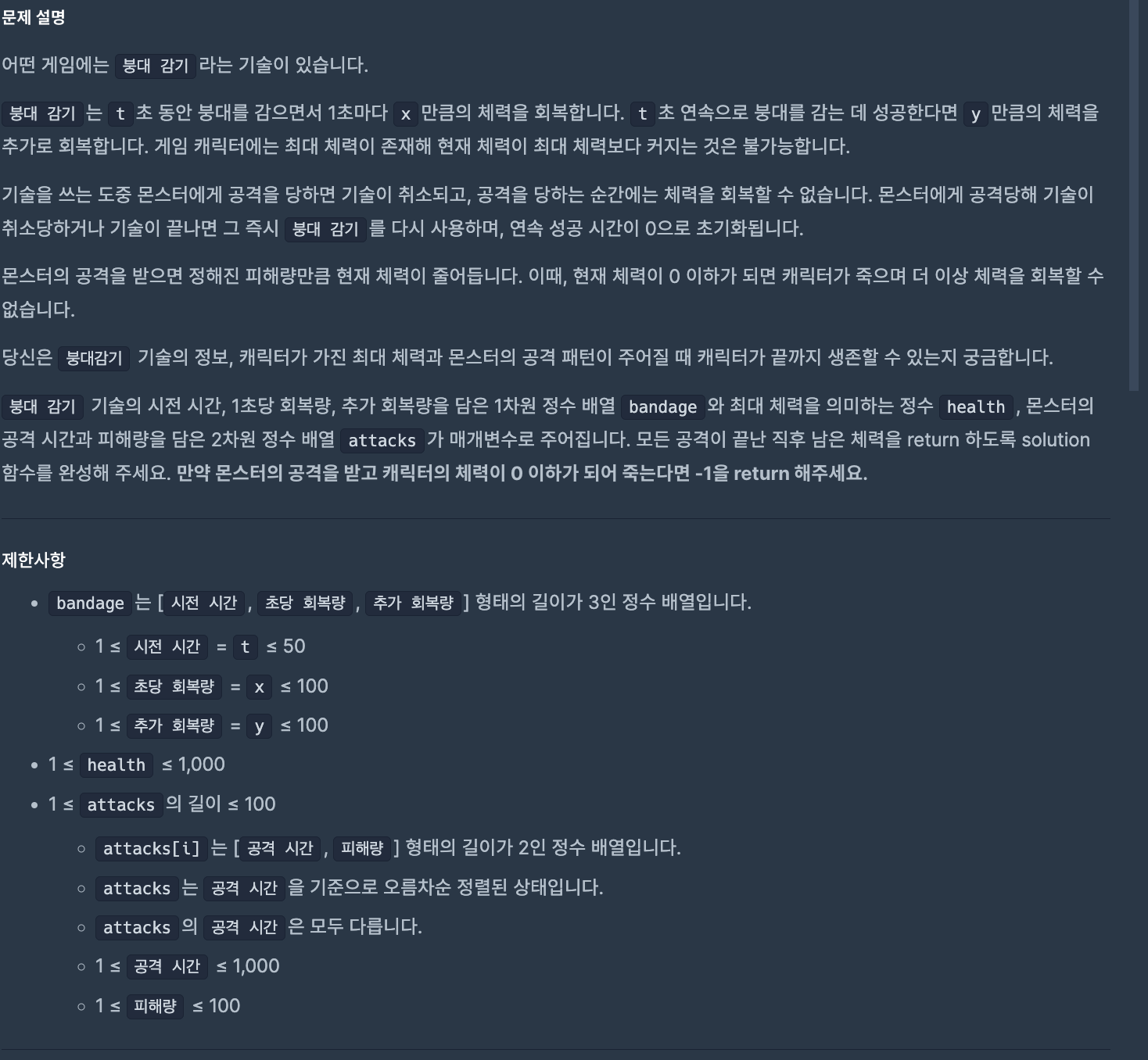
알고리즘 풀이 문자열 내 마음대로 정렬하기 (출처 : 프로그래머스)🧚문자열의 접근할 특정 인덱스의 글자를 기준으로 정렬된 문자열의 배열을 출력하는 문제이다.즉, 특정 인덱스의 글자와 함께 문자열은 같이 움직여야 한다.단, 조건은 특정 인덱스의 글자가 겹치는 경우가 존
9.AI 부트캠프 - 9일차
1\. 머신러닝컴퓨터가 명시작으로 프로그래밍 되지 않아도 데이터를 통해 예측할 수 있도록 하는 기능머신러닝 구성요소1\. 데이터 셋80% -> 학습에 사용, 규칙을 뽑아냄 / 20% -> 테스트에 사용2\. Feature (특징)데이터에서 모델이 학습할 수 있는 개별
10.AI 부트캠프 - 11일차
지도 학습 모델 학습SVM이란서포트 벡터 머신은 분류와 회귀 분석에 사용되는 강력한 지도학습 모델이다.데이터를 분류하기 위해 결정 경계를 찾아 분류한다.초평면은 두 클래스 사이의 최대 마진을 보장하는 방식으로 선택함목표는 마진을 최대화하면서 결정 초평면을 찾아 데이터
11.AI 부트캠프 - 12일차
인공지능 : 인공지능은 인간의 지능을 모방하여 문제를 해결하는 기술을 의미함. AI는 규칙 기반 시스템으로부터 자율 학습 시스템까지 다양한 접근 방식을 포함함머신러닝 : 머신러닝은 데이터를 이용해 모델을 학습하고, 이를 통해 예측이나 결정을 내리는 기술임. 머신러닝은
12.AI 부트캠프 - 13일차
입력층 : 입력층의 뉴런수는 입력데이터 피쳐수와 동일은닉층 : 은닉층의 뉴런수와 층수는 모델의 복잡성과 성능에 영향출력층 : 출력층의 뉴런 수는 예측하려는 클래스 수 또는 회귀문제 출력차원과 동일동작 방식순전파 (Forward Propagation) 각 뉴런은 입력 값
13.AI 부트캠프 - 14일차
정규화정규화는 입력 데이터의 분포를 일정한 범위로 조정하여, 모델의 학습을 안정화하고 성능을 향상시키는 기법임배치 정규화 : 각 미니배치의 평균과 분산을 사용하여 정규화함 이는 학습 속도를 높이고, 과적합을 방지하는 데 도움이 됨레이어 정규화 : 각 레이어의 뉴런 출력
14.AI 부트캠프 - 15, 16일차
RNN 복습순환 신경망이기 때문에 sequential 데이터에 대해 잘 동작함이전 시간 단계의 정보를 현재 시간 단계로 전달해, 시퀀스 데이터의 패턴을 학습할 수 있음모든 시점의 가중치가 동시에 update가 된다. (처음부터 끝까지 같은 가중치를 갖지 않도록 해줌)다
15.AI 부트캠프 - 17, 18일차
알고리즘 - 기사 단원의 무기 출처 : 프로그래머스 🧚 약수의 갯수를 얼마나 효율적으로 계산할지가 관건인 문제이다. 문제의 개념은 간단했지만 저 "효율적"에 애를 먹었던 문제이다. 처음에는 약수의 갯수를 구하기 위해 해당하는 숫자까지 전부 순회를 하였다. 하지만
16.AI 부트캠프 - 18일차
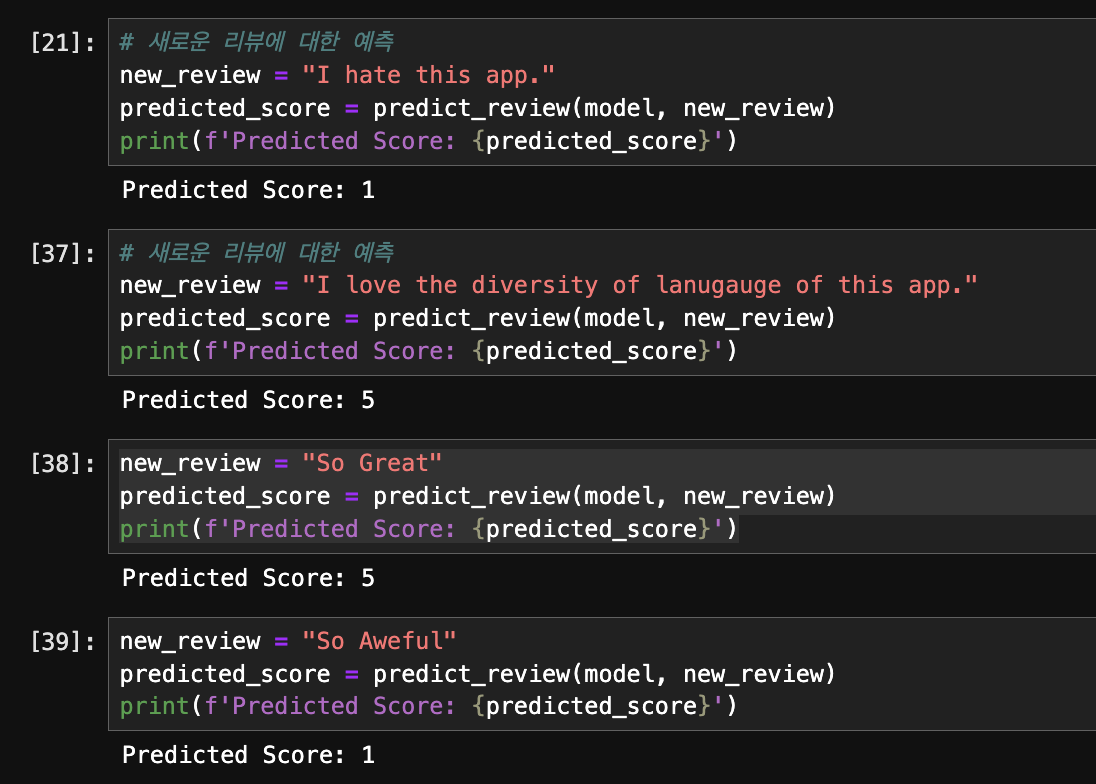
사실 이전 LSTM 모델에서 에폭을 5로 줄여서 학습을 시켜보았는데 모든걸 부정적으로 보는 모델이 생성되었다 개선할 수 있는 방법은 없을까??? 떠오른 방법과 부트 캠프가 추천하는 방법은 아래와 같다. optimzer 수정 (SGD -> Adam) 손실함수 수정
17.AI 부트캠프 - 19,20일차
앞서 기본 lstm 모델을 바탕으로 텍스트 리뷰 기반 딥러닝 모델을 만들어보았다.해당 모델에서는 Attention 알고리즘 적용하여 에포크를 100번 돌았을 경우에 좋은 성능을 보임을 알 수 있었다.추가로 같은 방식으로 sentiment 예측 모델도 생성할 수 있었다.
18.AI 부트캠프 - 24일차
1. 바탕화면 정리 (출처 : 프로그래머스) 🧚 문제의 길이가 길지만 쳐내다 보면 단순한 문제임을 알 수 있는 문제이다. 정리해보자면 스크롤의 최소 넓이를 구하는 것이다. 단 주의해야 할 점이 몇가지 존재한다. 스크롤은 단순 배열이 아니라 시작점과 끝점이 한
19.AI 부트캠프 - 25일차
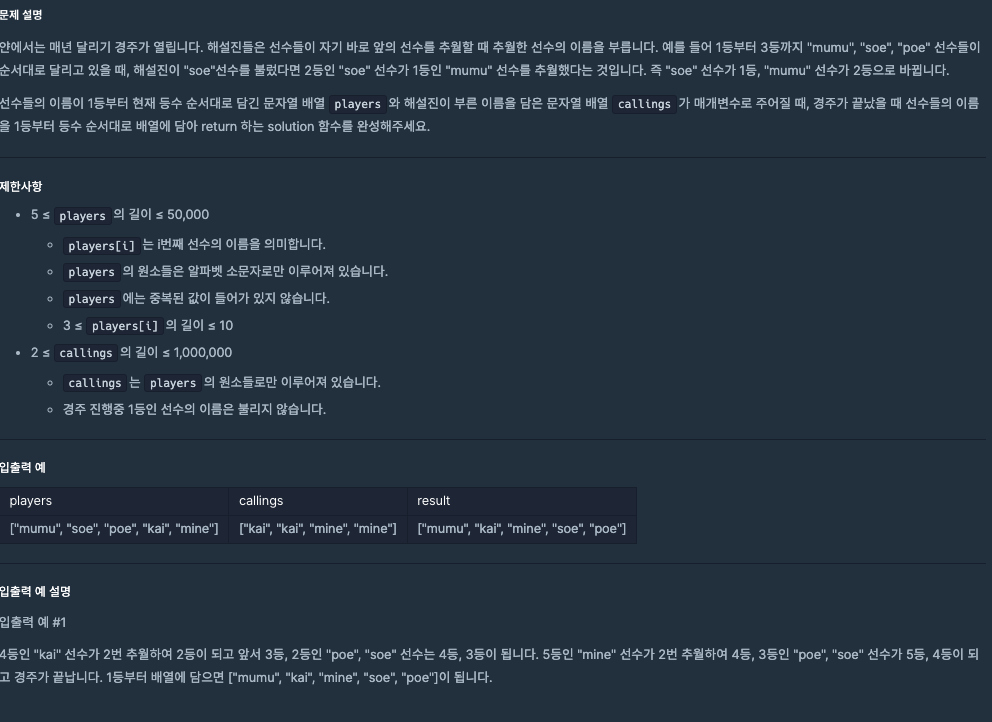
🧚이번에는 문제의 길이는 짧은데 시간초과로 애를 먹었던 문제이다.초기에 내가 하였던 접근은 다음과 같다.callings, 즉 순서를 바꿔야 하는 상황일 때마다 players를 다시 탐색해서 같은 name이 나온다면 해당 기준으로 앞뒤를 바꿔주는 로직이었다.처음에 문제
20.AI 부트캠프 - 26일차
공원산책 (출처 : 프로그래머스) 🧚 문제는 간단하나 생각보다 시간이 오래걸렸다. 오래 걸린 이유 또한 간단했다. 단계적 풀이를 하지 않아서였다. 이렇게 방향키(?)같은 문제를 접근할 때에는 한 개의 방향키 당 접근해야 한다는 것을 깨달았다. 또한 여러 에러들을
21.AI 부트캠프 - 28일차
1\. 학습 : LLM은 대규모 텍스트 데이터셋을 이용해 학습함여기서 중요한 개념은 "패턴 인식"임.수많은 텍스트에서 단어와 문장의 패턴을 찾아내어, 새로운 문장이나 답변을 생성할 때 그 패턴을 적용함2\. 추론 :학습된 LLM은 질문이나 입력을 받으면, 그에 따른 추
22.AI 부트캠프 - 29일차
First Attempt\-> 반복을 택했어야 시간 복잡도가 낮아짐The Answer일종의 모듈화가 잘 된 라이브러리라고 생각하면 됨주요 개념1\. 언어 모델 (LLM)언어 모델은 주어진 입력을 바탕으로 텍스트를 생성함 LangChain은 OpenAI의 GPT 모델을
23.AI 부트캠프 - 30일차
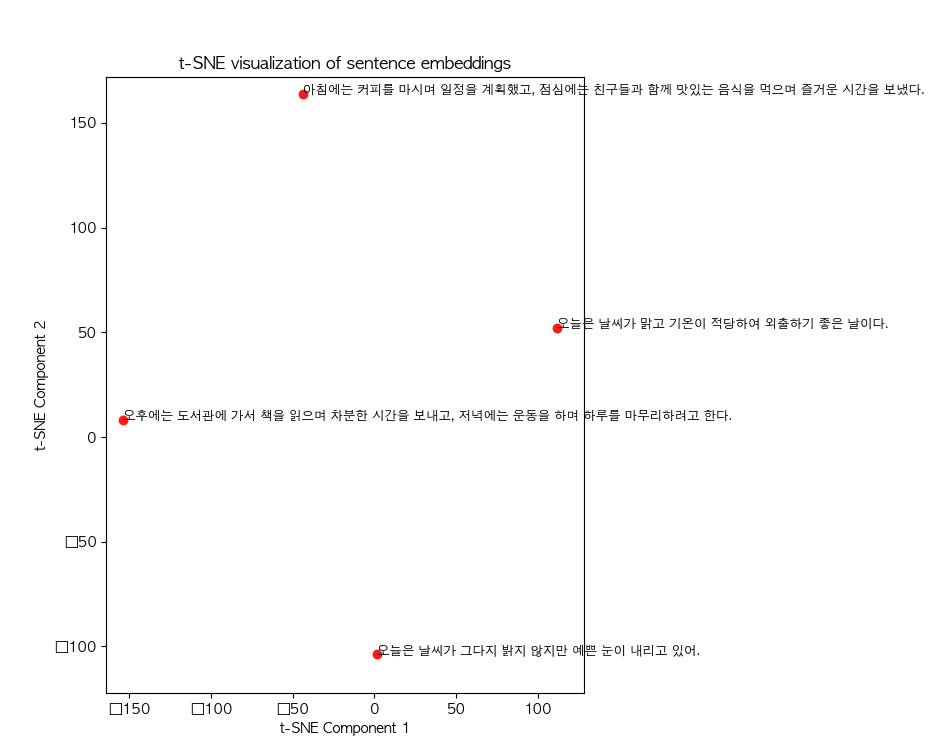
한국어 임베딩을 위해서는 세가지 기법이 존재한다고 한다.Sentence-Transformer, Word2Vec, Transformer 기반 임베딩Word2VecWord2Vec은 단어를 고차원 벡터로 변환하여 의미적 유사성을 측정하는 임베딩 기법임단어 간의 문맥적 관계를
24.AI 부트캠프 - 31일차

평가 기준1\. 사용 환경OpenAI2\. 모델 로드gpt-4o-miniRAG3\. 문서 로드4\. 문서 청킹가장 먼저 청킹은 텍스트를 작은 덩어리, 즉 "청크"로 나누는 과정을 말함, LLM을 학습할 때 긴 텍스트 전체를 한 번에 처리하기보다는 일정한 길이의 청크로
25.AI 부트캠프 - 32일차
이번에는 LangChain 프롬프트 Library에서 사용할 만한 프롬프트를 가져온 후 다듬어서 LangChain의 품질을 높이는 작업을 해보겠다. > 0. API KEY (model : OPEN AI, Langchain : Langchain) >1. Prompt
26.AI 부트캠프 - 33일차
기본 모델의 성능을 살펴보기 위한 기본 코드를 돌려보았는데 여러 질문을 해 본 결과 꽤나 잘못된 정보를 답변하는 경우가 존재했다.택한 데이터가 논문이었기 때문에 챗봇으로 활성화를 했을 경우 치명적일 것이라고 판단했다.대대적으로 전처리부터 다시했다.전처리논문 특성상 "\
27.AI 부트캠프 - 34일차
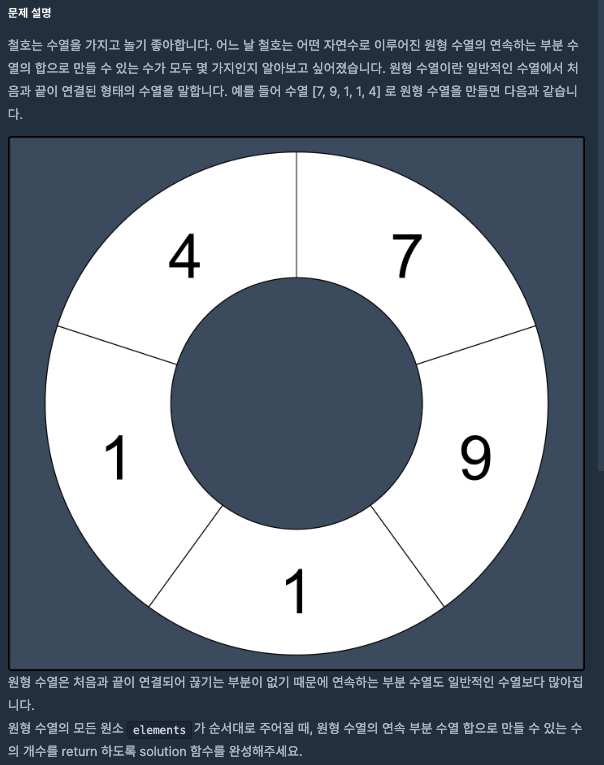
📌초반에는 완전탐색 문제인줄 알고 아 쉽네 했는데 삼중 반복문을 만나고 나서 완전 탐색으로는 해결할 수 없음을 깨달았다.결론은 "원형 배열" 과 "부분 합" 의 특성을 활용했어야 했다는 것이다.이전에는 단순히 특정 구간의 합을 구하기 위해서는 반복문 / sum을 이용
28.AI 부트캠프 - LLM, RAG 적용 챗봇 만들기
현재 2주짜리 팀프로젝트로 LLM, RAG를 적용한 학습용 챗봇만들기 프로젝트를 하고 있다.나는 모델 고도화를 담당했다.이전에 해왔던 단순 정보 탐색용으로 RAG를 사용하는 것이 아닌 정보 탐색 + 문제 출제 기능을 수행할 수 있는 챗봇을 만들어야 했기 때문에 참고할
29.AI 부트캠프 - Docker
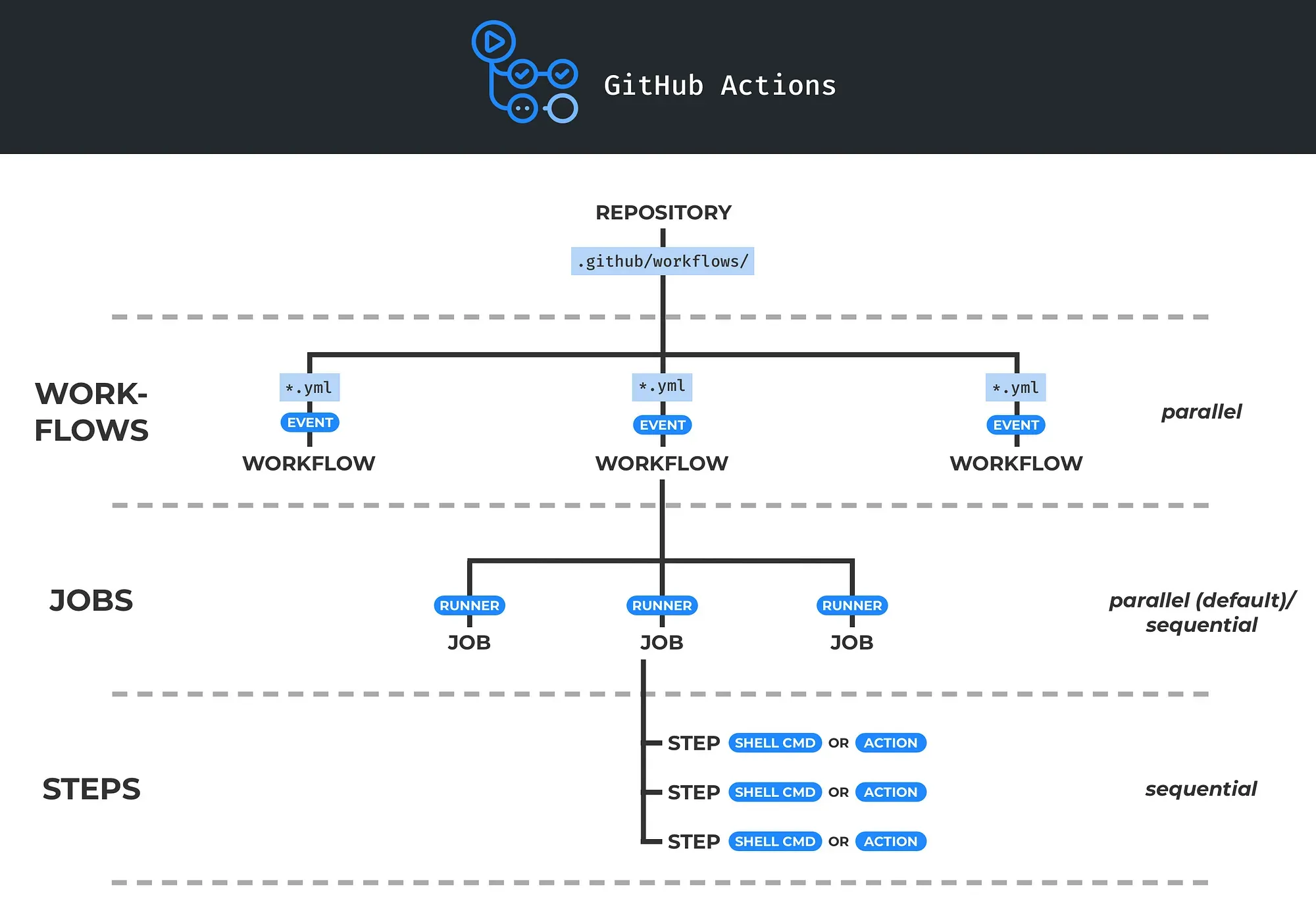
도커 사용이유CI/CD에서 지속적인 통합 과정의 테스트에서 Docker를 활용함어떤 서버에 올리더라도 같은 환경으로 구성된 컨테이너로 동작하기 때문에 표준화된 배포를 구성할 수 있음여러 애플리케이션의 독립성과 확장성이 높아짐Docker가 가상화에서 사실상 표준의 위치도
30.AI 부트 캠프 - Docker 2
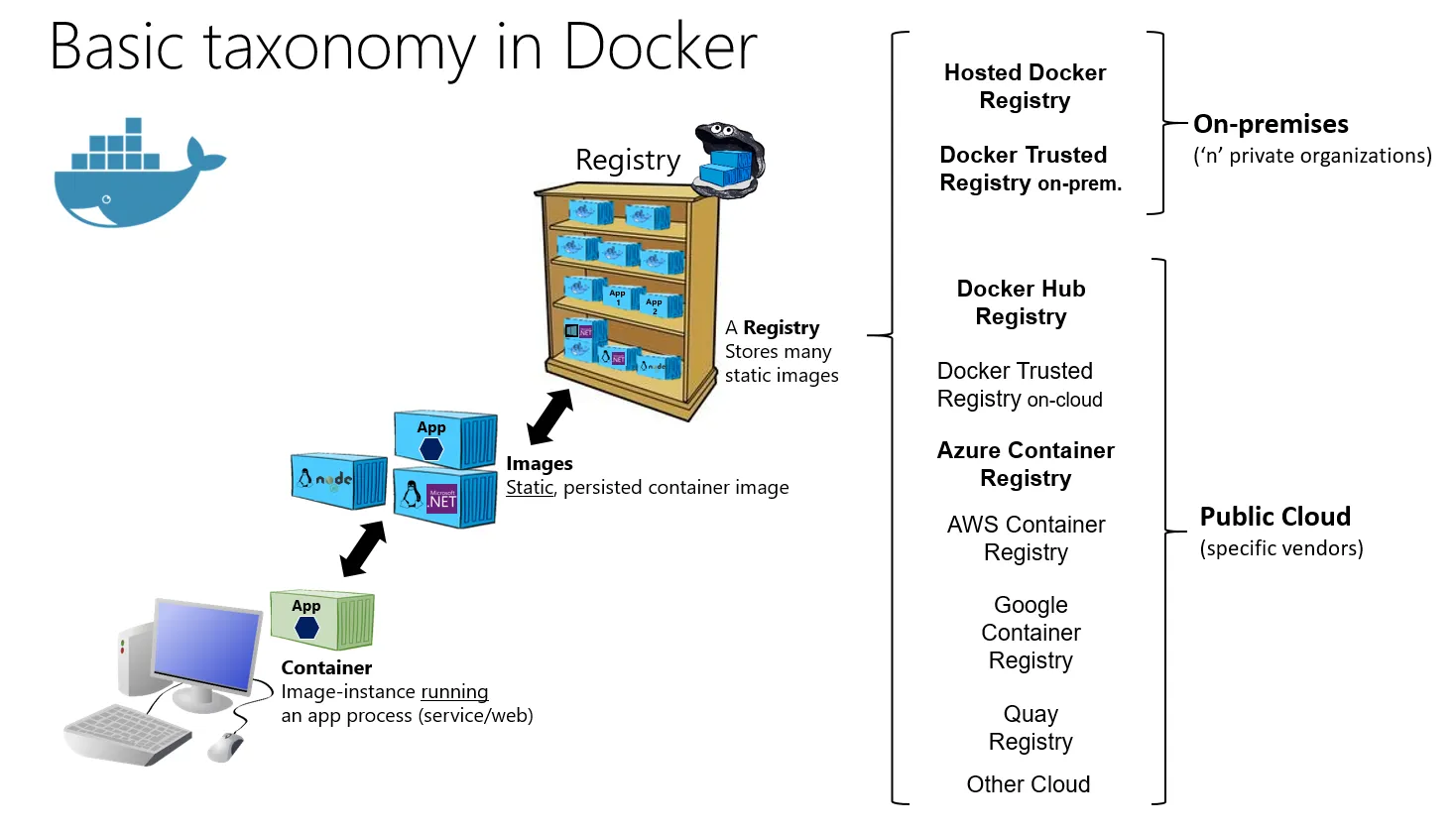
뭔가 배포를 관리하는 CI/CD는 이해를 잘 했는데 Docker에 대한 개념은 와닿지 않았다.다시 해보자이미지를 설계도같은 것 명령어FROM : 베이스 이미지를 선택MAINTAINER : 이미지를 만든 사람의 정보를 입력LABEL : 이미지에 메타데이터를 추가 RUN
31.AI 부트캠프 - Docker 3
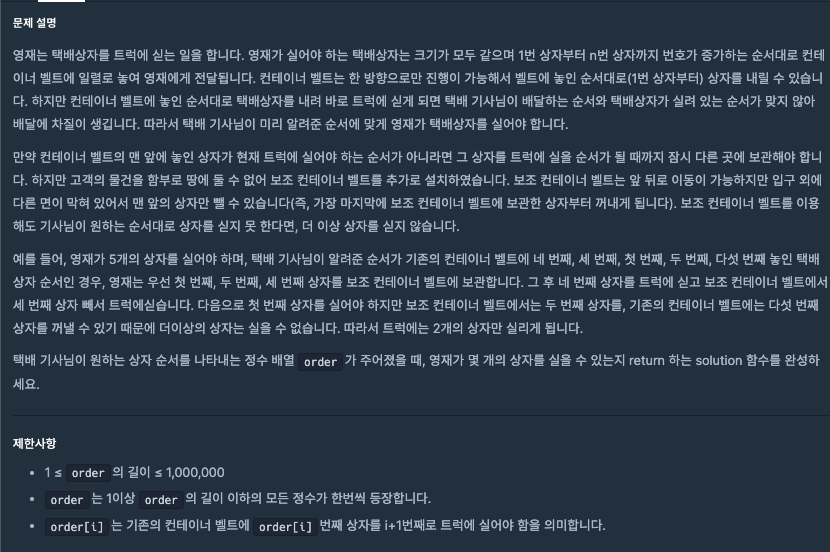
알고리즘 (택배상자 / 출처 : 프로그래머스)🧚규칙은 간단하다.order의 숫자 나열을 최우선으로 하되해당 나열에 포함되지 않는 숫자들을 관리하는 sub_array가 필요하다는 것이다.다만 이 sub_array를 초기화 하는 부분에서 많은 애를 먹었다.시간의 복잡도가
32.AI 부트캠프 - Django의 기초
연속된 부분 수열의 합 (출처 : 프로그래머스) 🧚 연속된 부분 수열인데 그 합이 k와 같아야 하며 부분 수열 가운데에서도 그 간격이 가장 작고 짧은 것을 구하는 것이 최종 목적이다. sequence의 길이가 1,000,000 이기 때문에 시간복잡도를 반드시 고
33.AI 부트캠프 - Django 기초 마무리
그리디 알고리즘탐욕적인 탐색검토 사항 : 가장 탐욕적인 탐색 방법이 배수의 조건에 해당 되거나 (가장 먼저 우선시 해야 하는 조건에 해당되거나) 탐욕적인 선택만으로 답을 구할 수 있을 것이라 판단될 때 사용함거스름 돈 문제배수의 조건에 해당 되기 때문에 그리디 알고리즘
34.AI 부트캠프 - Django
Model 저장할 데이터에 대한 필드와 동작들을 포함한 데이터베이스 구조 Django는 Model을 이용해서 데이터를 조작 일반적으로 하나의 Model은 하나의 데이터베이스 테이블을 의미 Migration Python으로 작성한 model의 코드가 데이터베이스에는
35.AI 부트캠프 - DRF
HTTP 요청URI : 통합 자원 식별자, 웹상에 자원이 어디 있는지 나타내기 위한 문자열RestFul API : URL로 소통하는 것URL은 동사가 아닌 명사의 나열로 사용해야 함(POST /articles/create 가 아닌 POST /articles/ 로 사용해
36.ReadRiddle 개발기 - 1
백엔드 : Django프론트엔드 : ReactDB : PotegreSQLCI/CD : Docker, AWS규칙 : MSA맡은 역할 : ReactReact 선택 이유React 프로젝트 구조하지만 이는 보안에 취약하다는 치명적인 단점이 있었습니다.공격자가 웹 애플리케이션의
37.ReadRiddle 개발기 - 2

문제 : 같은 퀴즈 세션에 대해서만 답변, 결과가 업데이트 되던 문제문제 원인:현재 백엔드에서 가져오는 id 값은 퀴즈 세션의 id값이 아닌 존재하지 않은 값이기 때문에 나오는 디폴트 값인 1이었습니다.백엔드 구조즉, 백엔드 측에서 보내주는 id 값이 전체 퀴즈 세션의
38.ReadRiddle 개발기 - 3
구현 사항폼 형식 퀴즈 개발퀴즈 Summary 요약 화면 제공채팅 퀴즈에 API 연결문제 : 개별 피드백 화면 연결 못함 문제원인 : 로직의 복잡성 때문에 프론트에서의 처리에 불편함을 겪었음 과거 개별 피드백 요청 시에 피드백만 나오는 구조였으며 애초에 질문을 생성할
39.ReadRiddle 개발기 - 4
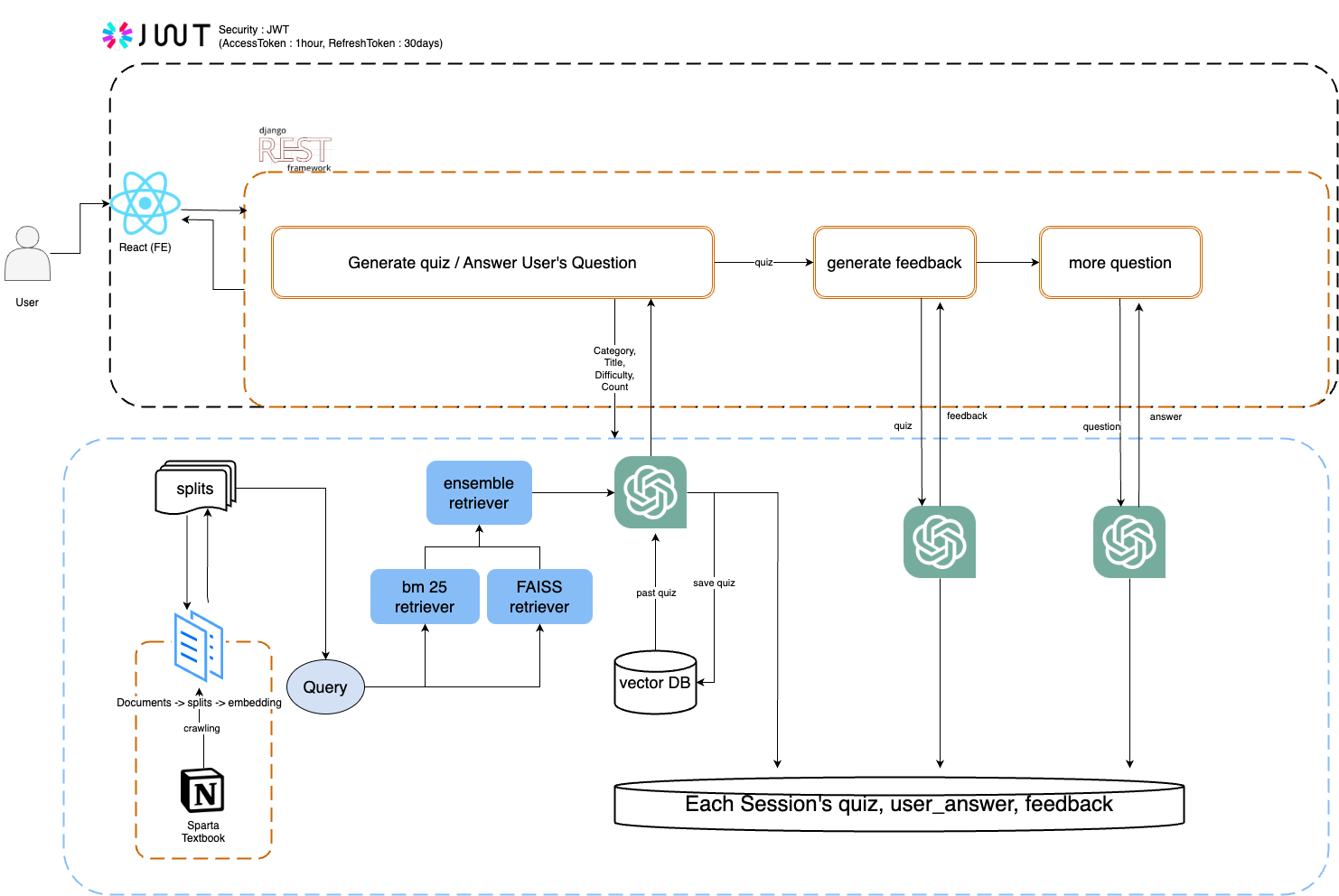
중간발표 준비기본 프로젝트에서는 웹 개발/AI 학습을 원하는 사용자가 챗봇 / 시험지 형식을 통해 원하는 지식을 학습하거나 학습한 지식의 깊이를 확인해 볼 수 있는 서비스를 제공하고자 합니다.데이터 셋범위 : AI 부분 스파르타 노션 교재, 교재 기반 실제 코드 개발
40.ReadRiddle 개발기 - 5
AWS Ec2 인스턴스 생성Ubuntu키페어 설정 (RSA 키 설정)용량 설정 (어느정도 서비스가 완성이 된 이후부터는 8GB가 너무 작다는 문구가 나왔다. -> 20GB)SSH 접근키페어 연결 (chmod 400 ./readriddle_suyeon.pem)SHH 접근
41.ReadRiddle 개발기 - 6
EC2를 활용하지 않고 React 배포 하는 방법\-> ECS로 ECR컨테이너를 띄워서 ColudFront의 proxy처리(말이 proxy지, AWS는 "동작"이라 표현한다)를 통해 백엔드와 프론트엔드를 연결함버킷 만들기리전 : 아시아 태평양퍼블릭 액세스 차단 설정 해
42.ReadRiddle 개발기 - 8
Fully Whole JWT 로그인Backend (60분 주기의 JWT AccessToken)Frontend (자동으로 refreshToken 갱신하도록)여기에서 핵심은 로그인할 때마다는 타이머로 사용할 로그인 TimeStamp를 찍고해당 타임스탬프가 백엔드의 원본 J