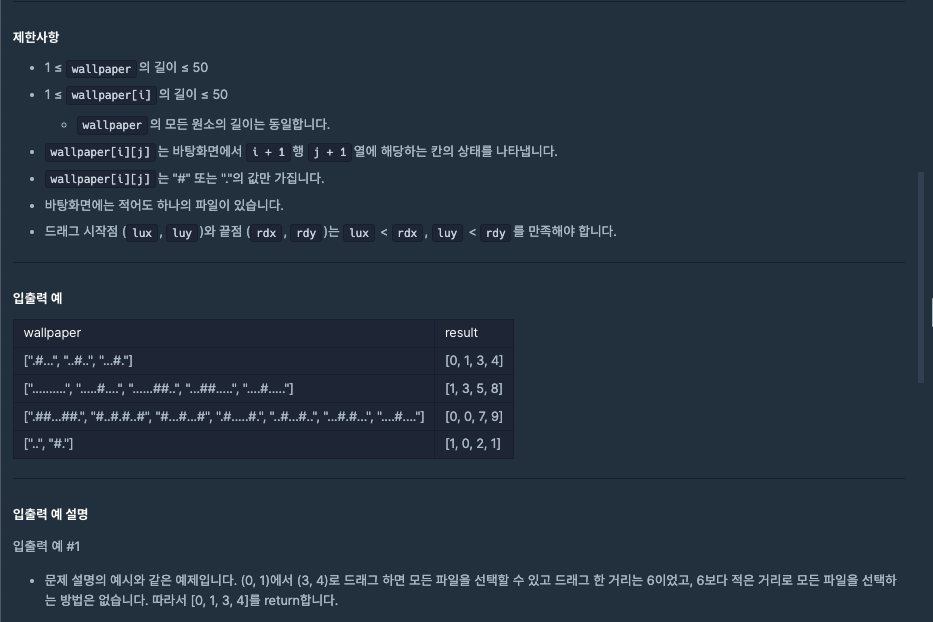
1. 바탕화면 정리 (출처 : 프로그래머스)

🧚
문제의 길이가 길지만 쳐내다 보면 단순한 문제임을 알 수 있는 문제이다.
정리해보자면 스크롤의 최소 넓이를 구하는 것이다.
단 주의해야 할 점이 몇가지 존재한다.
- 스크롤은 단순 배열이 아니라 시작점과 끝점이 한 칸으로 이루어져 있다는 것이다.
- 이 점 때문에 배열에 추가를 할 때에 이 점을 고려하여 추가해야 한다.
- 또한 파일들의 위치를 저장할 타입을 어떻게 선언할 것인가에 대해서도 고민이 필요했는데 단순히 x좌표와 y좌표만을 저장할 것이기 때문에 배열은 불필요하다는 판단을 했다. 때문에 튜플로 각 칸의 좌표들을 저장하고자 했다.
회고
"칸" 저장의 개념, 튜플 미사용, 문제를 성급하게 읽어 놓쳤더라면 풀이 시간이 늘어날 수도 있었던 문제였던 것 같다.
📌
def solution(wallpaper):
answer = []
tmp = []
row_len = len(wallpaper)
col_len = len(wallpaper[0])
for row in range(row_len):
for col in range(col_len):
if wallpaper[row][col] == "#":
tmp.append((row, col))
tmp.append((row+1, col+1))
# print(tmp)
x_array = []
y_array = []
for tup in tmp:
x_array.append(tup[0])
y_array.append(tup[1])
x_array = sorted(x_array)
y_array = sorted(y_array)
# print(x_array)
# print(y_array)
answer.append(min(x_array))
answer.append(min(y_array))
answer.append(max(x_array))
answer.append(max(y_array))
return answer2. 성격 유형 검사하기 (출처 : 프로그래머스)


🧚
이 문제는 더 길다.
카카오 문제는 뭔가 이입은 잘되는데 정리하면서 풀지 않으면 안드로메다로 갈 수 있는 위험성이 있는 경향이 있다.
때문에 간단한 문제설명도?
- 메모메모해서 한눈에 문제가 들어오도록해야하며
- 문제 예시를 볼 때 참고할 용도이다. (나는 스크롤하다가 까먹는 금붕어다)
문제를 정리해보자면 다음과 같다.
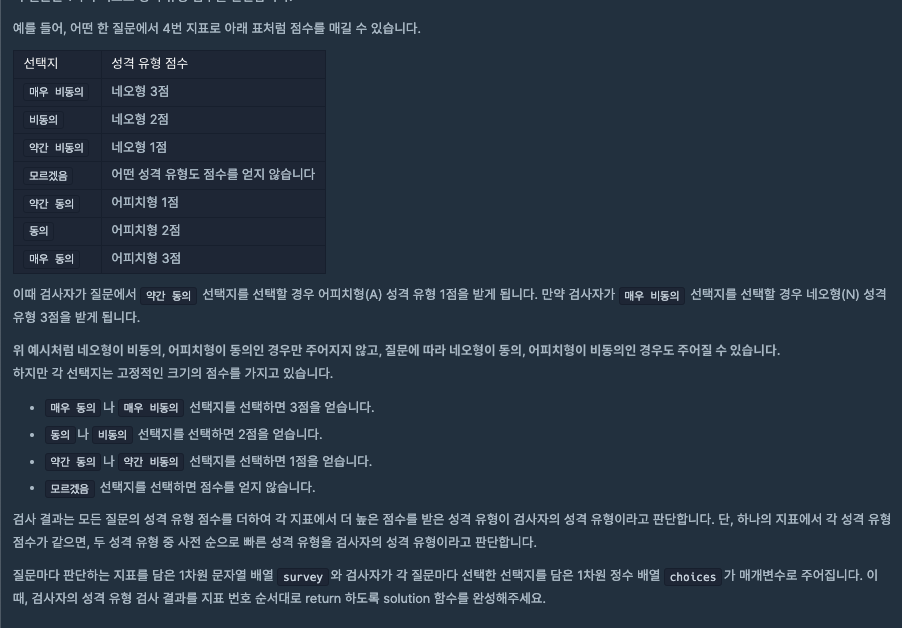
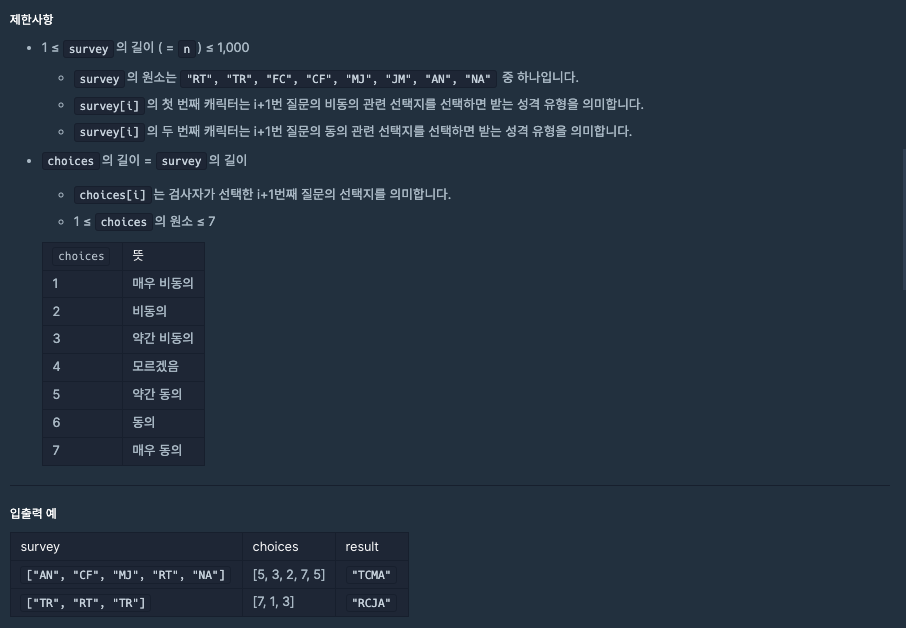
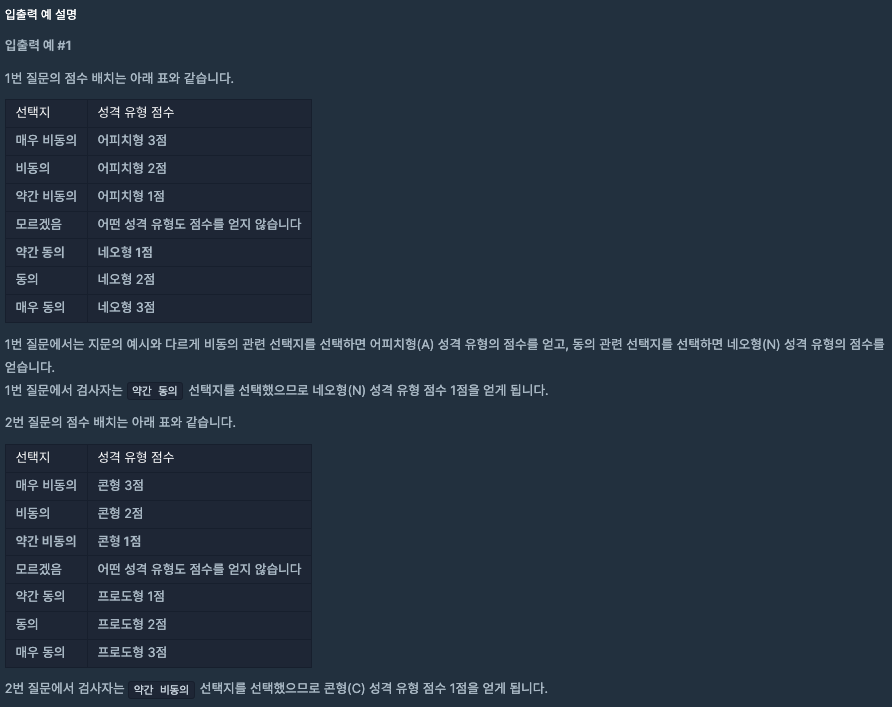
성격 유형 검사를 하는데 들어온 성격 유형 (surveys)에 따라 대응하는 점수(choices) 도 함께 부여되는데 그에 따라 각 캐릭터에 맞는 점수가 계산이 되며 계산된 결과는
최종 성격 유형 분류기에 들어가서 성격이 결정이 된다.
이때 최종 성격 유형 분류기에는 규칙이 존재하는데
아래와 같은 지표를 갖고 판별되며
1번 지표 라이언형(R), 튜브형(T)
2번 지표 콘형(C), 프로도형(F)
3번 지표 제이지형(J), 무지형(M)
4번 지표 어피치형(A), 네오형(N)
만약 두 캐릭터의 점수가 동일하게 나온다면 사전순으로 앞선 것으로 결정된다.
이번 풀이에서는 모듈화를 진행했는데
1. 매우 비동의, 비동의... 같은 choices 의 값에 따라 점수가 부여되기 때문에 이를 거르는 cal 함수를 만들었고
2. 최종 성격 유형 분류기를 함수로 빼서 만들었다.
📌
def cal(first, second, score, dic):
if score == 1:
dic[first] += 3
elif score == 2:
dic[first] += 2
elif score == 3:
dic[first] += 1
elif score == 5:
dic[second] += 1
elif score == 6:
dic[second] += 2
elif score == 7:
dic[second] += 3
def division(answer, dic):
axis = ["RT", "CF", "JM", "AN"]
for one in axis:
if dic[one[0]] > dic[one[1]]:
answer += one[0]
elif dic[one[0]] < dic[one[1]]:
print(dic[one[1]])
answer += one[1]
else:
arr = [one[0], one[1]]
sorted_arr = sorted(arr)
answer += sorted_arr[0]
return answer
def solution(survey, choices):
answer = ''
survs = {"R":0, "T":0, "C":0, "F":0, "J":0, "M":0, "A":0, "N":0}
for i in range(len(survey)):
first, second = survey[i][0], survey[i][1]
cal(first, second, choices[i], survs)
answer = division(answer, survs)
return answerAPI 활용
모델 서빙이란?
모델 서빙은 학습된 머신러닝 모델을 실제 애플리케이션에서 사용할 수 있도록 제공하는 과정임
서빙된 모델은 외부에서 입력 데이터를 받아 예측을 수행하고, 그 결과를 응답으로 반환함
이를 위해 API를 활용해 모델에 접근할 수 있도록 함
RESTful API란?
REST(representational state transfer) 아키텍처 스타일을 따르는 API로, HTTP를 통해 클라이언트와 서버 간에 데이터를 주고 받는 방식임
FastAPI
python으로 작성된 빠르고 간단한 웹 프레임워크로 RESTful API를 구축하는 데 매우 적합함
Fast API
우선 웹 프레임워크라는 점에서 장고랑 헷갈렸다.
가장 큰 차이점은 장고는 동기 방식 (물론 최근에는 비동기 처리를 일부 지원하지만)
FastAPI는 비동기 방식이라는 점이다.
동기방식이란?
작업이 순차적으로 진행되는 방식
특정 작업이 완료될 때까지 프로그램은 기다림
비동기 방식이란?
여러 작업을 동시에 진행할 수 있는 방식
특정 작업이 완료될 때까지 대기하지 않고, 다른 작업을 먼저 수행함
따라서 일반 웹페이지 개발에는 장고가,
머신러닝 모델을 제공하는 서버 개발에는 FastAPI 가 더 유리하다는 점을 알 수 있었다.
그리고 특정 서비스 (ex. 챗봇) 같은 서비스에는 FastAPI만, 이외의 서비스적인 개발에는 장고를 사용해 상호 보완적인 이득을 얻을 수 있겠음
사전 설치
pip install fastapi uvicorn- Uvicorn (ASGI 서버) : HTTP 요청을 받아 처리할 수 있게 해주는 서버
실행 명령어
uvicorn your_script_name:app --reload서버 확인
<http://127.0.0.1:8000/>문서화 확인
<http://127.0.0.1:8000/docs>OpenAI API 사용 간단 실습
from dotenv import load_dotenv
import os
import openai
# .env 파일 불러오기
load_dotenv()
openai.api_key = os.getenv("OPEN_API_TOKEN")
system_message = {
"role" : "system",
"content" : "너는 변호사야, 나에게 법률 상담을 해줘"
}
messages = [system_message,
{"role": "user", "content": "내 이름은 쿠키"},
{"role": "user", "content" : "직업은 대학생"},
{"role" : "user", "content" : "먹는 걸 좋아함"}
]
while True:
user_input = input("사용자 전달 : ")
if user_input == "exit":
print("즐거운 대화였습니다! 감사합니다!")
break
messages.append({"role" : "user", "content" : user_input})
completion = openai.ChatCompletion.create(
model="gpt-4o",
messages=messages
)
reply = completion.choices[0].message.content
print("대답 : " + reply)
messages.append({"role": "assistant", "content" : reply})OpenAI API ChatGPT API 활용한 챗봇 실습
-
사용자의 input 입력값 받고
-
입력값에 맞는 출력 답변 생성
-
사용자가 보낸 채팅과 Assistant가 보낸 채팅이랑 구분해서 채팅 리스트 생성
-
style.css에서 message를 누가 보냈느냐 (user, assistant에 따라) 보이는 채팅방향이나 색상이 결정됨
from fastapi import FastAPI, Request, Form
from fastapi.templating import Jinja2Templates
from fastapi.responses import HTMLResponse
from fastapi.staticfiles import StaticFiles
from dotenv import load_dotenv
import os
import openai
# .env 파일 불러오기
load_dotenv()
openai.api_key = os.getenv("OPEN_API_TOKEN")
app = FastAPI()
# Jinja2 템플릿 설정 (HTML 과의 소통을 다룬 문법 탬플릿, 문법 사용가능, style.css 가져와 실행해줌)
templates = Jinja2Templates(directory="templates")
# 정적 파일 서빙
app.mount("/static", StaticFiles(directory="static"), name="static")
# 초기 시스템 메시지 설정
system_message = {
"role": "system",
"content": "너는 환영 인사를 하는 인공지능이야, 농담을 넣어 재미있게해줘"
}
# 대화 내역을 저장할 리스트 초기화 (추가로 위의 기본 코드처럼 프롬프트 엔지니어링을 할 수도 있겠음)
messages = [system_message]
@app.get("/", response_class=HTMLResponse)
async def get_chat_page(request: Request):
"""채팅 페이지 렌더링"""
conversation_history = [msg for msg in messages if msg["role"] != "system"]
return templates.TemplateResponse("index.html", {"request": request, "conversation_history": conversation_history})
@app.post("/chat", response_class=HTMLResponse)
async def chat(request: Request, user_input: str = Form(...)):
"""사용자 메시지를 받아 OpenAI API 호출 및 응답 반환"""
global messages
# 사용자의 메시지를 대화 내역에 추가
messages.append({"role": "user", "content": user_input})
# OpenAI API 호출
completion = openai.ChatCompletion.create(
model="gpt-4o",
messages=messages
)
# AI의 응답 가져오기
assistant_reply = completion.choices[0].message.content
# AI의 응답을 대화 내역에 추가
messages.append({"role": "assistant", "content": assistant_reply})
# 화면에 표시할 대화 내역에서 system 메시지를 제외하고 전달
conversation_history = [msg for msg in messages if msg["role"] != "system"]
# 결과를 HTML로 반환 (대화 내역과 함께)
return templates.TemplateResponse("index.html", {
"request": request,
"conversation_history": conversation_history
})
음성 변환 API elevenLabs API 실습
- 이때 이상하게 내장된 ENV파일을 제대로 가져오지 못하는 이슈가 있었다... (이유는 아직 알지 못함)
따라서 아래 코드의 api-key는 하드코딩했음
headers = {
"xi-api-key": xi_api_key,
"Content-Type": "application/json"
}
# 문장을 입력받습니다.
text = input("텍스트를 입력하세요: ")
# 음성 생성 요청을 보냅니다.
data = {
"text": text,
"model_id": "eleven_multilingual_v2",
"voice_settings": {
# 작을 수록 아나운서스러워짐
"stability": 0.6,
"similarity_boost": 1,
"style": 1,
"use_speaker_boost": True
}
}
# API로 post 요청
response = requests.post(url, json=data, headers=headers, stream=True)
# 오디오 파일 생성 및 재생
if response.status_code == 200:
audio_content = b""
for chunk in response.iter_content(chunk_size=1024):
if chunk:
audio_content += chunk
segment = AudioSegment.from_mp3(io.BytesIO(audio_content))
segment.export(output_filename, format="mp3")
print(f"Success! Wrote audio to {output_filename}")
# 오디오를 재생합니다.
play(segment)
else:
print(f"Failed to save file: {response.status_code}")
사전 학습
사전 학습된 모델은 대규모 데이터셋에서 미리 학습된 상태로 제공되는 모델임.
이 모델들은 이미 기본적인 패턴과 특징을 학습했기 때문에, 특정 작업에 대한 추가 학습 (파인 튜닝)을 통해 쉽게 높은 성능을 얻을 수 있음.
예를 들자면 이미지 분류 작업에서는 ImageNet 데이터셋으로 사전 학습된 모델을 많이 사용함
... 이미지 학습 내용은 내일 더 자세하게 정리 예정
!pip install fastai
from fast.vision.all import *
# 데이터셋 로드
path = untar_data(URLs.PETS) # PETS 데이터셋 다운로드 및 압축 해제
path_imgs = path/'images'
# 이미지 파일 라벨링 함수 정의
def is_cat(x): return x[0].isupper()
# 데이터블록 정의
dls = ImageDataLoaders.from_name_func(
path_imgs, get_image_files(path_imgs), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
# 데이터셋 확인
dls.show_batch(max_n=9, figsize=(7, 6))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.lr_find()
learn.find_tune(3)
learn.show_results()
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
