1. Pandas 실습
판다스의 개발 환경은 Jupyter Notebook으로 진행한다.
왜 Jupyter Notebook인가 하면 쉘마다 실습이 가능하기 때문에 시각화할 수 있기 때문이다.
// Conda의 실행파일이 인식되도록 함
export PATH="/Users/suyeon/anaconda3/bin:$PATH"
// 인식됨을 확인함
conda list
// Conda 버전 업데이트
conda update conda
// Conda 가상환경 생성
conda create --nmae pandas_course
// Conda 환경을 활성화할 수 있도록 필요한 설정을 현재 셸에 적용하는 명령어
source /Users/suyeon/anaconda3/etc/profile.d/conda.sh
// Conda 가상환경 활성화
conda activate pandas_course
// ipkernel 설치 : 가상환경을 Jupyter Notebook에서 사용하려면 ipkernel을 설치해야 함
pip3 install ipykernel
// 가상환경을 JuypyterNotebook에 추가하기
python -m ipykernel install --user --name myenv --display-name "my Env"
// Conda 가상환경 관리
conda env list
데이터 프레임
- 데이터 프레임의 형태는 2차원의 표 형태 데이터 구조이다
- 데이터 프레임은 여러 개의 시리즈가 모여서 만들어진다
- 즉 시리즈는 1차원, 데이터 프레임은 2차원이다.
import pandas as pd
# Series 생성, index 값을 주게 되면 0, 1, 2가 아닌 명시적 기준열이 생기는 것이다.
sample = pd.Series(["쿠키", "초코", 2], index = ["종류", "맛", "갯수"])
# 데이터 프레임의 타입은 각각은 다를 수 있지만 표시될 때에는 넓은 범위의 타입으로 표시된다는 특징이 있다.
sample.apply(type)
'''
종류 <class 'str'>
맛 <class 'str'>
갯수 <class 'int'>
'''
data = {
'이름': ['철수', '영희'],
'나이': [20, 30],
'직업': ['학생', '의사'] ;
}
df = pd.DataFrame(data)
# 깔끔한 형태로 나오게 된다. (Series가 결합된 진정한 데이터 프레임 형태이기 때문)
print(df)
특정 인덱스로 기준점을 세울 수도 있게 된다.
이때 inplace 옵션을 주어야 df 자체가 바뀌게 된다.
df.set_index("이름", inplace=True)
df[["나이", "직업"]] -> "나이", "직업" 두 series가 결합되어 DataFrame 형태로 나온다.
2. Numpy
Numpy의 주요 특징
- 고속 배열 연산 : C 언어로 작성되어 있어 파이썬 기본 리스트보다 훨씬 빠른 연산 가능
- 다양한 수학 함수 : 배열 간의 덧셈, 뺄셈, 곱셈 등의 연산을 효율적으로 수행
- 선형대수, 통계 : 복잡한 수학 계산도 처리 가능
Numpy 연산자의 특징
-
복합 대입 연산 (arr //= 2) 은 그 자리에서 값을 수정하는 것이며
-
직접 연산 (arr = arr // 2) 은 계산 후 그 자리에 할당해주는 것임
-
따라서 만약 int 나눗셈 연산 후 float가 반환된다면 복합 대입 연산에서는 에러가 나오는 반면 직접 연산은 에러가 나타나지 않게 된다.
왜냐? int 자리에 float 값을 넣어주려 하기 때문이다.
Numpy의 Atribute
을 알아보기 전에 계속 나오는 형상에 대해 간단히 알아보고 가겠다.
형상
- 처음에는 차원인 줄 알았으나 차원을 반환하는 Attribute가 따로 있었다.
- 그렇다면 형상은 어떤걸 의미하는가
- 명시적 의미로는 배열의 구조의 튜플을 의미한다.
예시를 들어서 설명해보겠다
arr1 = np.array([1, 2, 3, 4, 5])
이 경우에는 1차원 배열이며 원소의 개수는 5개이다.
따라서 형상은 (5,) 이다.
- 1차원이기 때문에 형상에서의 행 표현이 사라지게 된다. (실질적으로는 (5) 를 의미하는 것이라고 생각했다.)
그렇다면
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
이 경우는 어떻겠는가?
이 경우에는 2차원의 배열이며, 2행 3열의 형태를 띄고 있다.
따라서 형상은 (2, 3)이다.
3차원의 경우에는 어떨까?
arr3 = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
2면 2행 3열의 형태로 되어있다.
때문에 형상은 (2, 2, 3) 이다.
면 / 행 / 열 사이의 우선 순위는 존재하지 않지만 형상을 작성하기 위해서 우선 순위가 존재한다고 간주해 이해하니 더 수월했다.
그래서 정리하자면 형상 표현은
- 구성 요소의 수는 차원의 수와 동일함
- 순서는 면 / 행 / 열 순으로 적힘
본격적인 Numpy의 Attribute를 살펴보겠다.
- 우선 주의해야 할 점은 Attribute이기 떄문에 뒤에 ()가 붙지 않는다.
- np.array().reshape
- 차원을 바꾸고자 할 때 사용함
- 단 차원을 바꿀 때에는 바꾸고자 하는 차원이 원소의 갯수의 약수여야 함
- np.array().shape
- 배열의 형상을 반환해줌
- np.array().ndim
- 배열의 차원을 반환해줌
- np.array().size
- 배열 원소의 갯수를 반환해줌
- np.array().dtype
- 배열 원소의 type을 반환해줌
- np.array().nbytes
- 배열이 실제로 차지하고 있는 공간을 반환해줌
배열의 변환 Method
- np.array().ravel()
- 어떤 차원이든 상관없이 1차원으로 바꿔줌
- np.array().flatten()
- 1차원을 바꾸고 싶은데 원본 배열을 바꾸지 않고 반환하고 싶을 때 사용함
- np.array().transpose()
- 배열의 축을 바꾸고 싶을 때 사용함
배열의 연산
1. np.array().mean()
- 배열의 평균을 구하고 싶을 때 사용함
- np.array().max()
- 배열의 최댓값을 구하고 싶을 때 사용함
배열의 모든 속성/메서드를 확인하고 싶다면?
-> dir(np.array())
배열 채워넣기
- np.ones(채우고 싶은 배열의 형상)
- 배열을 1로 형상 틀로 채워넣고 싶을 때 사용함
- np.full(원하는 배열.shape, 채우고 싶은 값)
- 원하는 배열의 형상 틀대로 원하는 값으로 채우고 싶을 때 사용함
- np.arange(특정 값)
- 배열을 특정 값까지 연속적으로 채우고 싶을 때 사용함, 0부터 증가함
연산
- np.array() 연산을 하고 싶다면?
-> 사칙연산으로 진행할 수 있음 - np에서 제공하는 np.add()연산도 존재하는데 사칙연산보다는 좀 더 조절된 연산을 할 수 있다는 것이 특징임
- 종류로는 add, subtract, multiple, floor_divide, mod가 있음
- 브로드캐스팅 : 작은 배열이 큰 배열의 형태에 맞게 자동으로 확장되어 연산이 이루어지는 것을 의미함, 단 조건에 맞아야 함
arr1 = np.array([1,2,3,4,5])
arr2 = np.array([6,7,8,9,10])
arr3 = np.array([11,12])
arr4 = np.array([13]) # 브로드 캐스팅 확인 용도
result1 = arr1 + arr2 # [7,9,11,13,15]
result2 = arr1 + arr3 # 에러가 뜸 -> 브로드캐스팅 조건에 맞지 않았기 때문임
result4 = arr1 + arr4 # [14, 15, 17, 18] -> 자동 행렬 덧셈을 해줌
np.add(arr1, arr4, out = result) # arr1과 arr4의 행렬 덧셈 결과가 result로 나옴, result는 미리 선언되어 있어야 함
np.subtract(arr1,arr2) # arr1 에 arr2를 뺌
np.multiple(arr1, arr2) # arr1에 arr2를 곱함
np.floor_divide(arr1, arr2) # arr1에 arr2를 나눔 (소수점 버림)
np.mod(arr1, arr2) # arr1에 arr2를 나눈 나머지를 반환함
np.empty_like(arr1) # arr1 형상을 가진 빈 np array가 생성이 됨
- 브로드 캐스팅 확인 예시
arr1 = np.array([1, 2, 3]) # 형싱 : (3,)
arr2 = np.array([[10], [20], [30]]) # 형상 : (3,1)
broadcasting_result = arr1 + arr2
print(broadcasting_result.shape) # (3,3)
'''
# broadcasting_result 형태
array([[11, 12, 13],
[21, 22, 23],
[31, 32, 33]])
'''
- 확인할 수 있는 사칙 연산 (사용 : np. ~)
sum : 합
prod : 누적곱
cumsum : 누적합
mean : 평균
median : 중앙값
argmin : 최소값이 위치해있는 인덱스
argmax : 최댓값이 위치해있는 인덱스
ptp : 최솟값과 최댓값의 range
exp : 자연지수 함수
dot: 내적
vdot : 켤레 복소수 사용, 모든 입력 배열을 평탄화하여 내적
예시문제를 풀어서 체득해보겠다
(문제 출처 : Programmers)
문제 1.
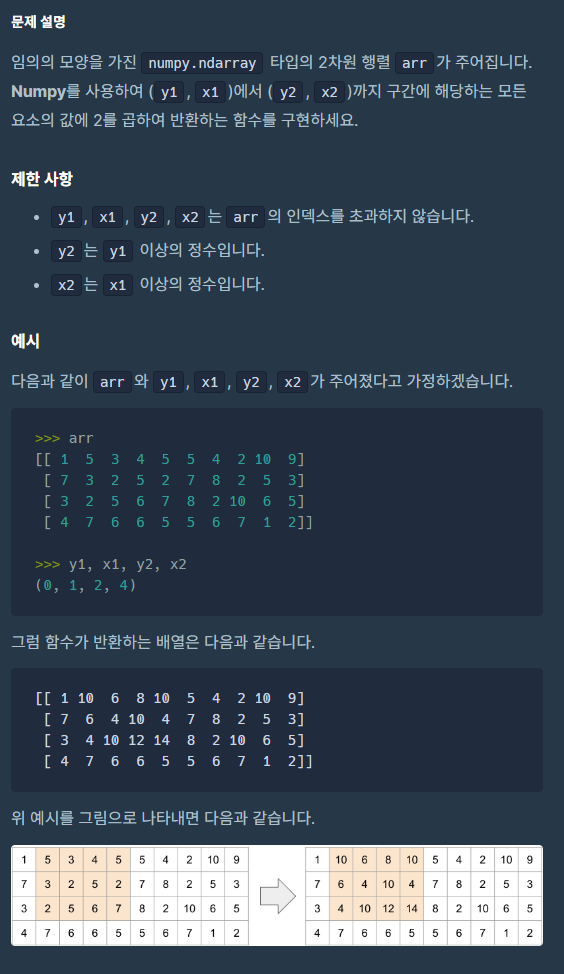
🧚
만약 numpy의 array가 아니라 그냥 array라면은 2배 연산을 진행해 준 후에 직접 모든 인덱스에 대입해주어야 하는 작업이 필요하겠다.
하지만 numpy의 array는 위 상황을 직접 배열에 2배를 해주는 것만으로도 해결할 수 있다. (브로드캐스팅)
📌
import numpy as np
def solution(arr, y1, x1, y2, x2):
arr[y1:y2+1, x1:x2+1] = arr[y1:y2+1, x1:x2+1] * 2
answer = arr
return answer문제 2.
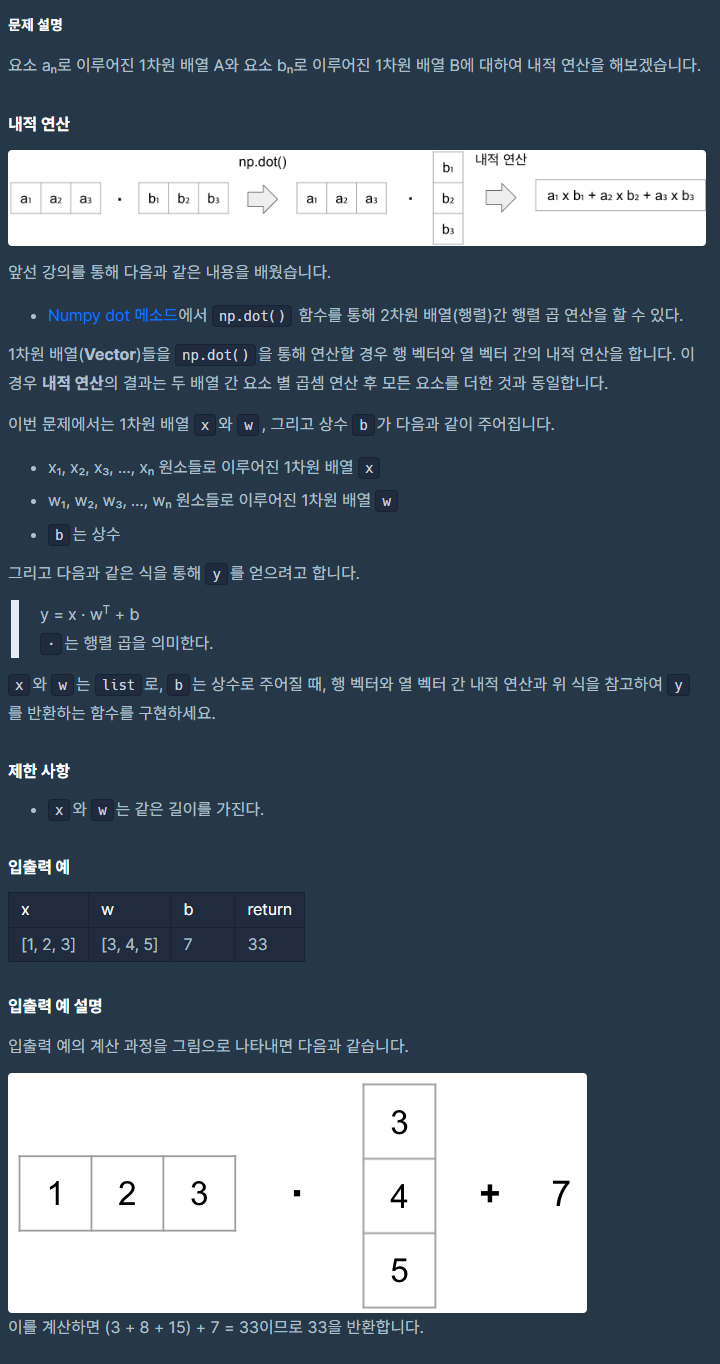
🧚
np의 사용법을 안다면 쉽게 풀 수 있는 문제이다
내적 연산을 하려면 np.dot(배열, transform 할 배열)
📌
import numpy as np
def solution(x, w, b):
answer = np.dot(x,w) + b
return answer문제 3.
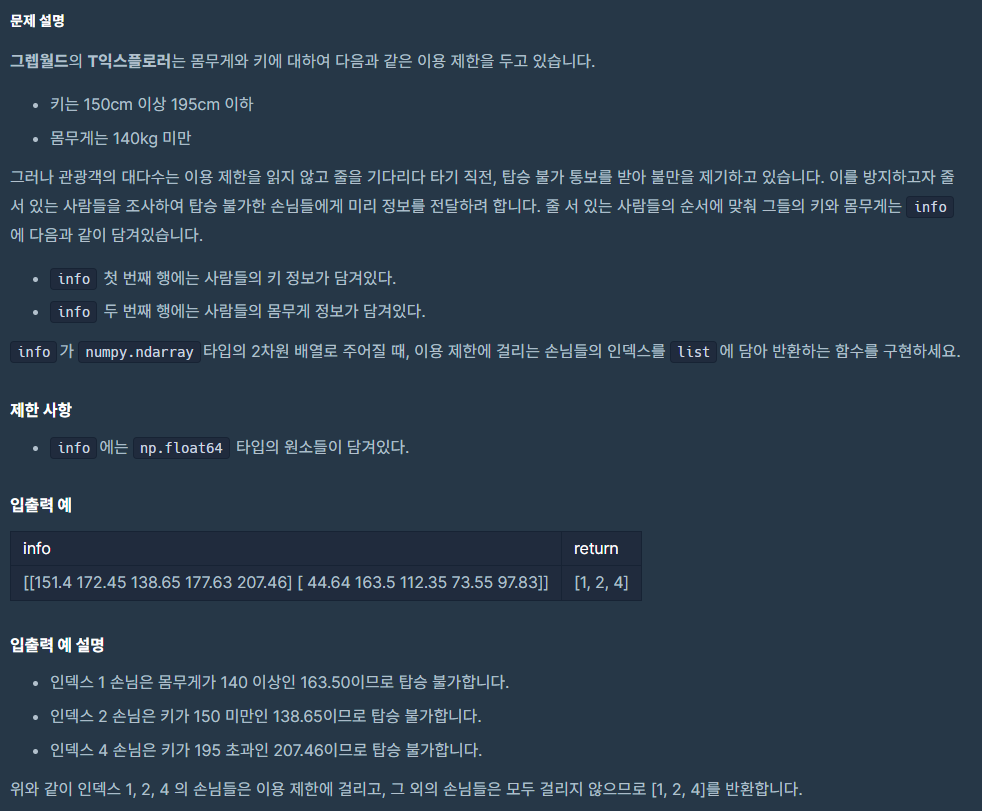
🧚
np.array() 형태로 들어오는 원소들의 형태에 유의하여 작성해야 한다.
해당 문제에서는 인덱스를 return 값에 포함시켜야 하기 때문에 for문에 원소 직접 접근이 아닌 인덱스 접근을 해야 한다.
📌
import numpy as np
def solution(info):
for i in range(len(info[0]):
if info[0, i] <= 150 or info[0,i] >=195 or info[1,i] >= 140:
answer.append(i)
return answer
문제 4.

🧚
여기에서 핵심은 "A와 arr의 행렬곱이 가능하다"는 조건이다.
행렬곱이 가능한 조건은 아래와 같다.
왼쪽 행렬 X 오른쪽 행렬이 있다고 했을 때
왼쪽 행렬의 열의 수와 오른쪽 행렬의 행의 수가 동일할 때이다.
왼쪽 행렬의 열의 수는 len(A[0])이고
오른쪽 행렬의 행의 수는 len(arr)가 되겠다.
또한 행렬 곱을 진행하기 위해 np.dot() 를 사용했다.
📌
import numpy as np
def solution(arr_list):
a = np.array([[0]])
for arr in arr_list:
if len(a[0]) == len(arr):
a = np.dot(a + 1, arr * 2)
answer = a
return answer
문제 5.

🧚
np.array() 형태로 들어오는 파라미터를 최대한 활용하는 것이 이 문제의 핵심이 되겠다.
들어오는 img의 각 열의 형태와 동일하게 return 하기 때문이다.
📌
import numpy as np
def solution(img):
h = len(img)
w = len(img[0])
r = img[:,:,0]
g = img[:,:,1]
b = img[:, :,2]
return 0.3 * r + 0.5 * g + 0.2 * b
