이번에 정리할 글은 AdaBoost, Gradient Boosting, XGBoost
AdaBoost
한마디로 표현하자면 "점점 똑똑해지는 팀 공부법"
어떤 문제든 중요도(가중치) 가 똑같다고 한 다음. 한 분류기에다가 문제를 풀린다.
어떤 친구가 맞히고 다른 친구는 틀렸다고 하면, 틀린 문제를 다음 친구에게 더 중요하게 알려준다. 계속 반복해서, 분류기들이 반복해서 문제를 풀고 잘한 친구일수록 높은 점수를 주고 이 점수를 활용해 모델을 만든다. 👉 정리하면 처음한 친구가 낮은 점수를 받고 나중에 한 친구가 앞에 한 친구들을 보고 학습한 다음 점수를 받으니 높은 점수를 받음
평가 지표
일단, 정확도 score 값 만으로는 조금 불안함. 전체 중 2프로만 암 환자인데, 모든 환자를 정상으로 예측해도 정확도가 98% 나 나오니 엄청 좋아보임
- Confusion Matrix
- Precision
- Recall
- F1 score(요거 좀이따가 해볼거임 👉 Classification Report 활용해용 (support - 각 클래스 샘플 수, Macro avg - 단순 평균, Weighted avg: 샘플 수 가중 평균)
언제 사용해?
Roc-Auc: 클래스 균형이 맞을 때, 전반적 성능
PR Curve: 불균형 데이터, Positive 클래스가 중요할 때
의료진단: PR Curve 중요 (암 환자가 매우 적음)
일단 코드 보고 실습하면서 확인해보자
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score, roc_curve, auc, precision_recall_curve, average_precision_score중요한거는 AdaBoost분류기 클래스를 넣어주는거, 그리고 sklearn.metrics 의 평가 지표들 쭉 넣어준다.
classification_report - 종합선물세트(precision, recall, f1-score, support(클래스별 데이터 개수))
confusion_matrix - 타일 표
roc_auc_score - 모델이 전체적으로 얼마나 잘 구분하는지 0-1점수로 평가. 0.5 랜덤, 1 완벽!
roc_curve - 이 모델은 보통 0~1 사이의 값을 출력하고, 만약 내가 조건으로 0.5 이상이면 1이라고 하자. 실제 1인 것 중에서, 모델이 1이라고 맞춘 비율-recall(재현율) 을 y에다 놓고(높을수록 좋음), 실제 0인데 모델이 1이라고 잘못 판단한 비율(건강한 사람을 암이라고 한 비율) (낮을수록 좋음)을 x축으로놓는다.
그래서 roc-curve 그래프는 ↘️ 이런 모양으로 갈수록 좋음.
auc - 얘는 곡선 아래 면적
precision_recall_curve - 클래스 불균형에서 가장 중요한 그래프. Positive가 매우 적은 상황(암 진단, 사기 거래 탐지)에서 쓴다. Threshold값을 조정하면서 Precision과 trade-off 값을 확인.
trade off? 👉 둘을 동시에 최고로 가질 수 없어서, 하나를 올리면 다른 하나가 내려가는 관계
average_precision - PR curve 누적 평균. PR curve를 하나의 숫자로 요약한 값
average_precision_score - PR-AUC 함수. average_precision과 유사하지만 계산 방식이 더 엄밀함.
이상, 클래스 설명이었음.
그 다음,
X에다가 유방암 파일의 데이터값 넣어주고
y에다가 유방암 파일의 타겟값 넣어줌
이제 ada_boost를 해주는데, estimator로 결정 트리를 넣어준다(약한모델). 이외에 넣을 수 있는 약한 모델 리스트로는 logisticregression, linear svc, perceptron 등이있음.
이 외에 내가 공부했던 분류기 randomforest SVM, KNN 등도 있지만, 이 모델들은 약한 모델이 아니라 강한 모델이어서 adaboost 구조와 잘 맞지 않음. adaboost는 약한 모델을 여러번, 가중치를 조절해서 강화시키는 구존데, 처음부터 강한 모델을 넣으면 오히려 성능 다운
ada_boost = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=50,
learning_rate=1,
algorithm='SAMME',
random_state=42
)
ada_boost2 = AdaBoostClassifier(
estimator=LogisticRegression(),
n_estimators=50,
learning_rate=1,
algorithm='SAMME',
random_state=42
)
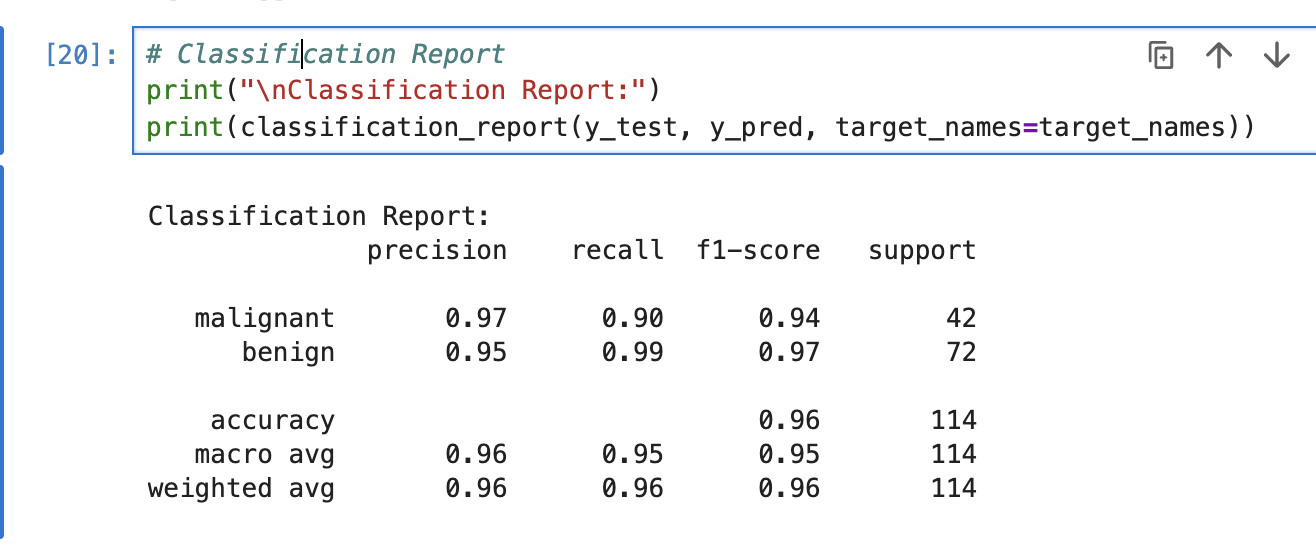
ada_boost.fit(X_train, y_train)요게 Decision tree로 classification report 한 추출값들
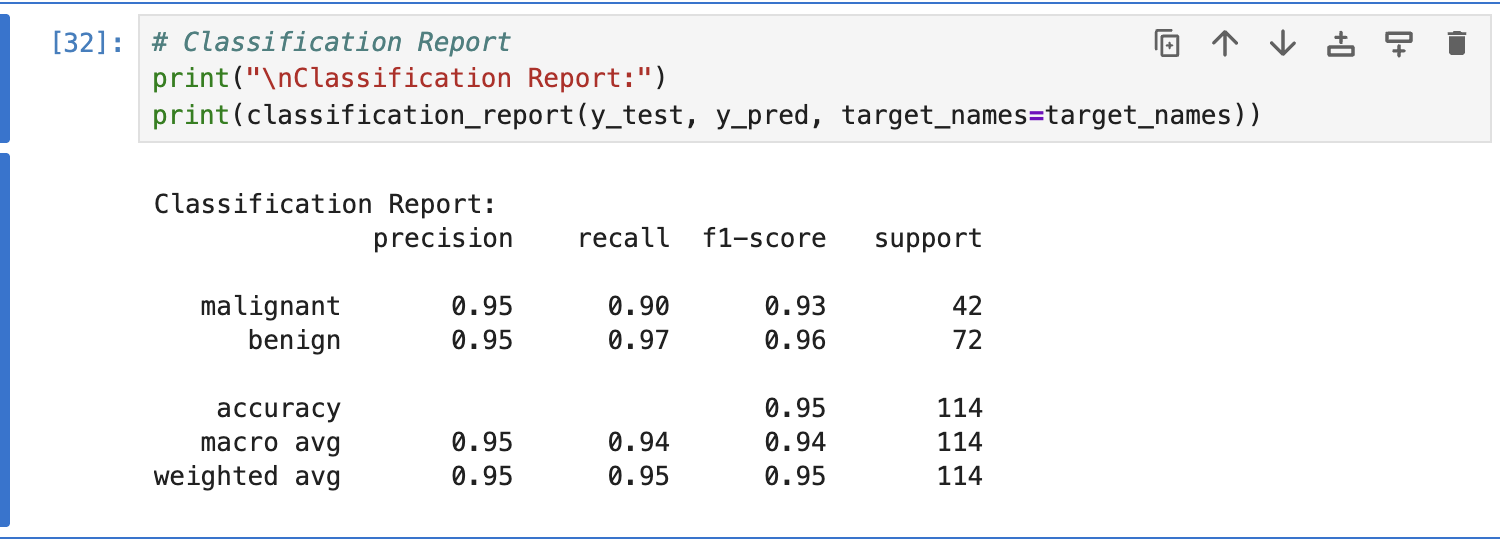
요게 Logistic회귀로 classification report 한 추출값들
Confusion Matrix
요거는 정확도랑 재현율 확인하는 타일그래프.
히트맵 그리기도 가능한 matrix
y_pred = ada_boost.predict(X_test)
y_proba = ada_boost.predict_proba(X_test)[:, :1]
cm = confusion_matrix(y_test, y_pred)
print(cm)roc-auc score
roc_score = roc_auc_score(y_test, y_proba)Average Precision Score
ap_score = average_precision_score(y_test, y_proba)요정도 하고 넘어가자.
Gradient Boosting
전에 했던거 단점을 나열하면
AdaBoost는 이진분류에 최적화
노이즈와 이상치에 민감
이것도 adaboost처럼 틀린부분을 고쳐나가면서 점점 더 똑똑해지는 모델을 만드는건 맞지만, adaboost는 틀린 문제만 계속 강조해서 학습하는 방식이라면, Gradient Boosting은 문제를 틀린만큼 '오차를 계산해서' 다음 친구가 그 오차를 고치도록 하는 방법.
adaboost가 속도가 빠른대신 성능이 중간 정도라면, gradient는 깊은 트리도 사용하면서 속도는 느려지지만, 성능은 매우 좋아진다.
adaboost는 간단한 문제에 사용되지만, gradient boosting은 실제 데이터를 비교분석할 때 사용됨
모듈과 클래스로 sklearn.ensemble 모듈의 GradientBoostingClassifier 가져오기
gradient Boosting도 앞에 sklearn 모델들이랑 비슷하게 estimator넣어주고, leearning_rate 넣어주고 shit + tap눌러서 안에 메서드 뭐있는지 확인하고 각각의 값들 넣어주면 됨.
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor
from sklearn.datasets import make_regression, make_classification
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# 1. 분류 예제
X_clf, y_clf = make_classification(n_samples=500, n_features=10,
n_informative=5, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X_clf, y_clf, test_size=0.3, random_state=42
)
# 2. Gradient Boosting 분류기
gb_clf = GradientBoostingClassifier(
n_estimators=100, # 부스팅 라운드
learning_rate=0.1, # 학습률 (shrinkage)
max_depth=3, # 개별 트리 깊이
min_samples_split=2, # 노드 분할 최소 샘플
min_samples_leaf=1, # 리프 노드 최소 샘플
subsample=1.0, # 샘플링 비율
max_features='sqrt', # 특성 샘플링
random_state=42
)
# 3. 학습
gb_clf.fit(X_train, y_train)
# 4. 성능 평가
print("="*50)
print("Gradient Boosting Classifier")
print("="*50)
print(f"훈련 정확도: {gb_clf.score(X_train, y_train):.4f}")
print(f"테스트 정확도: {gb_clf.score(X_test, y_test):.4f}")XGBoost
XGBoost는 대용량 데이터셋(100만 행 이상), 최고 성능이 필요한 경우(Kaggle 경진대회), 결측치 많은 데이터, 학습 시간 단축하고 싶을 때, 안정석+속도를 잡고 싶을때. 즉 모든 방면에서 좋은거 쓰고싶을때 쓰셈
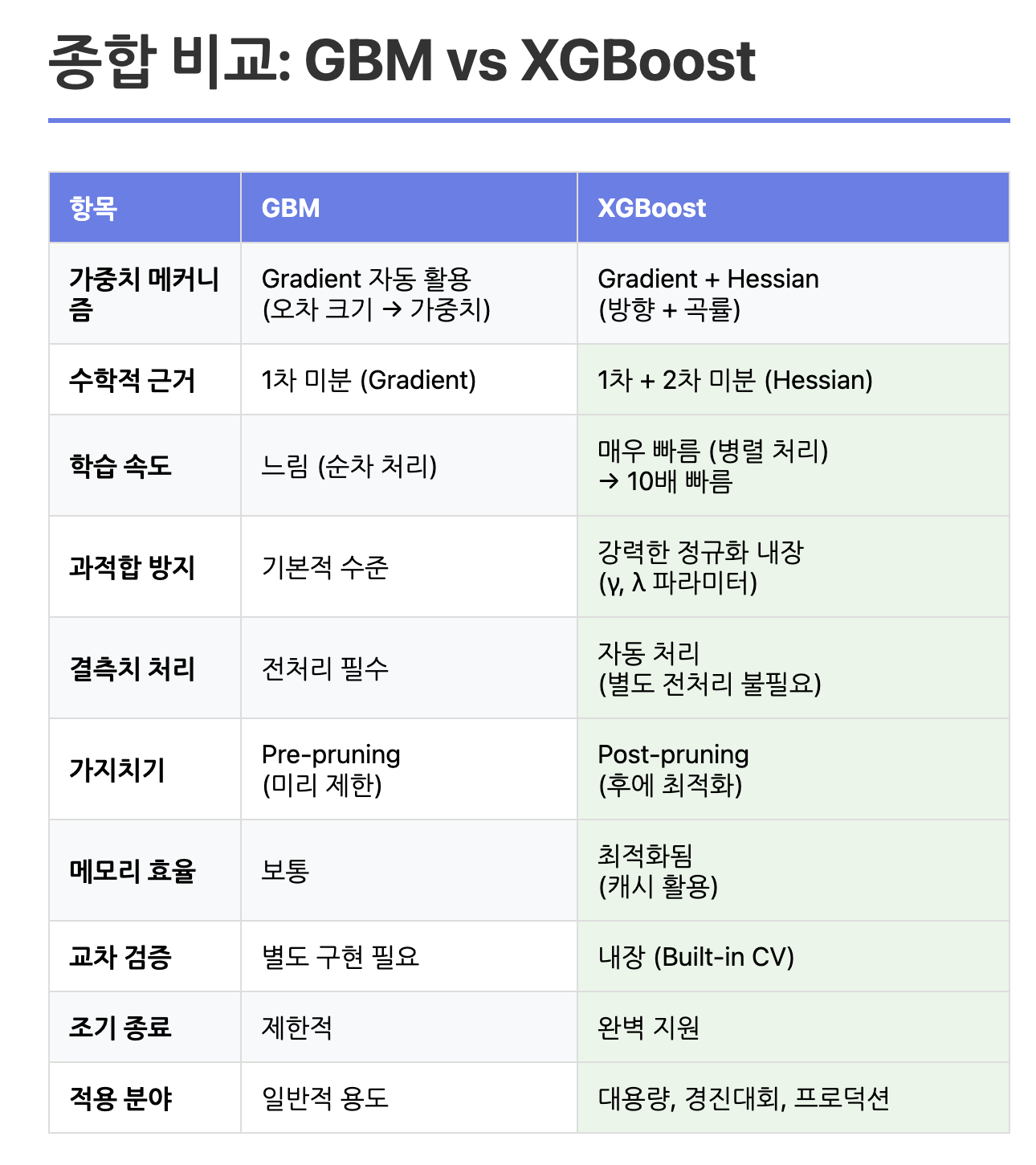
둘다 약한 모델을 가지고 강한 모델을 만드는 '부스팅'방법이지만, Adaboost는 틀린 데이터에 가중치를 부여하는 방식, Gradient Boosting은 잔차(오차)를 직접 고치는 방식이다.
xgb방식은 !pip install xgboost 다운 ㄱㄱ
xgb.XGBClassifier 에다가 하이퍼 파라미터 형식으로 이것저것 넣어준다.
n_estimators = 100
XGBoost는 나무를 여러 그루 심어서 예측하는 모델. 나무를 몇 개 심을지 지정. 많을수록 더 복잡한 패턴을 잘 잡지만, 단점으로 학습 시간이 오래 걸리고, 너무 많으면 과적합 발생
max_depth= 3
각 나무들이 얼마나 깊게 보낼건지 결정
learning_rate = 0.1,
XGBoost는 나무를 하나씩 추가해가면서 조금씩 수정해나가는 방식(Gradient Boosting). 이때 조금씩의 크기를 정하는 비율.
이 값이 커지면 한 번에 많이 못고치지만 속도는 업!
이 값이 작아지면 천천히, 안정적 but 나무 개수를 더 늘려 주어야 함.
random_state = 42
42 자체에 특별한 의미 없음
실험을 해도 다시 같은 결과 나오게 하는장치(random요소를 가미 하는 느낌)
# XGBoost 설치: pip install xgboost
import xgboost as xgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 로드
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Sklearn 스타일
model = xgb.XGBClassifier(
n_estimators=100,
max_depth=3,
learning_rate=0.1,
random_state=42
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"정확도: {accuracy_score(y_test, y_pred):.4f}")