머신러닝
1.머신러닝 1일차 (251031)
수업 리뷰 해보쟈머신러닝 1일차수업한거 대부분은 개념 + 실습조금머신러닝이 뭔데?지도학습, 비지도학습, 강화 학습 차이데이터 분할 과 시각화 해보기모델 성능 문제 뭐가있는지 확인해보기정확도, 정밀도, 재현율 기본 개념 알기일단! 이런 부분을 듣기만 했지 이렇게 직접 개
2.머신러닝 2일차(251104)
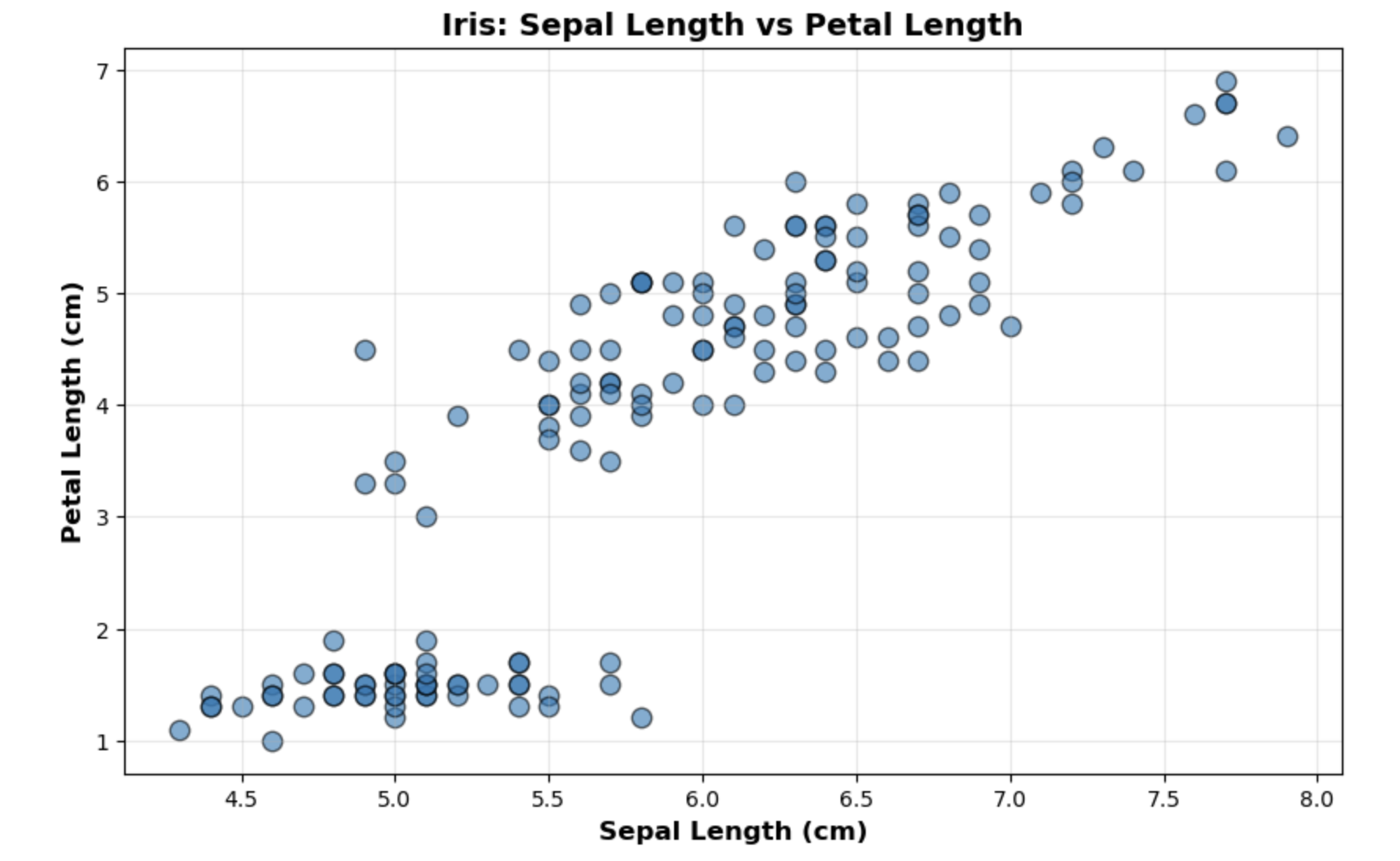
다음날이 되고 정리를 시작한다. 어제 미니 프로젝트 했던거 블로그 쓰고 나니 12시여서 일단 피곤해서 자고 내일 하자 함. 막상 오늘 일어났는데 피곤해서 10시 전까지 쭉 자버림 ㅎㅎ2일차 주제는 회귀분석과 선형회귀 점들 사이에서 숨겨진 관계를 찾아내는 방법이다.자잘한
3.결측값 없애기 + 최적의 점수 묶어서 확인하기
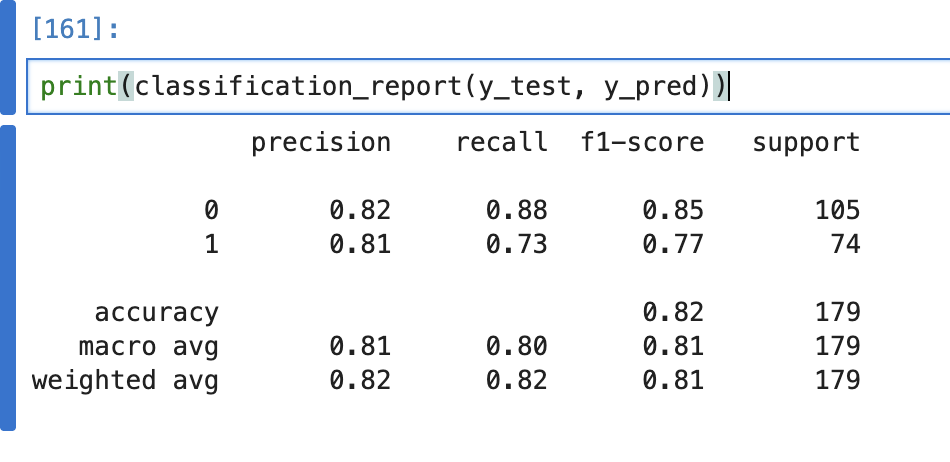
3일차 과제 리뷰 해보려 함. 원래는 수업 전체 내용을 블로그 글로 정리 했었는데, 내용이 너무 많아서 과제를 집중적으로 정리하는거로 방향을 틀었다. 수업 내용을 다 따라가기에도 벅차다 보니 이렇게 진행할것임. (이해 부탁드립니다)일단 이번 과제는 iris 데이터 가지
4.feature 엔지니어링 - feature generation
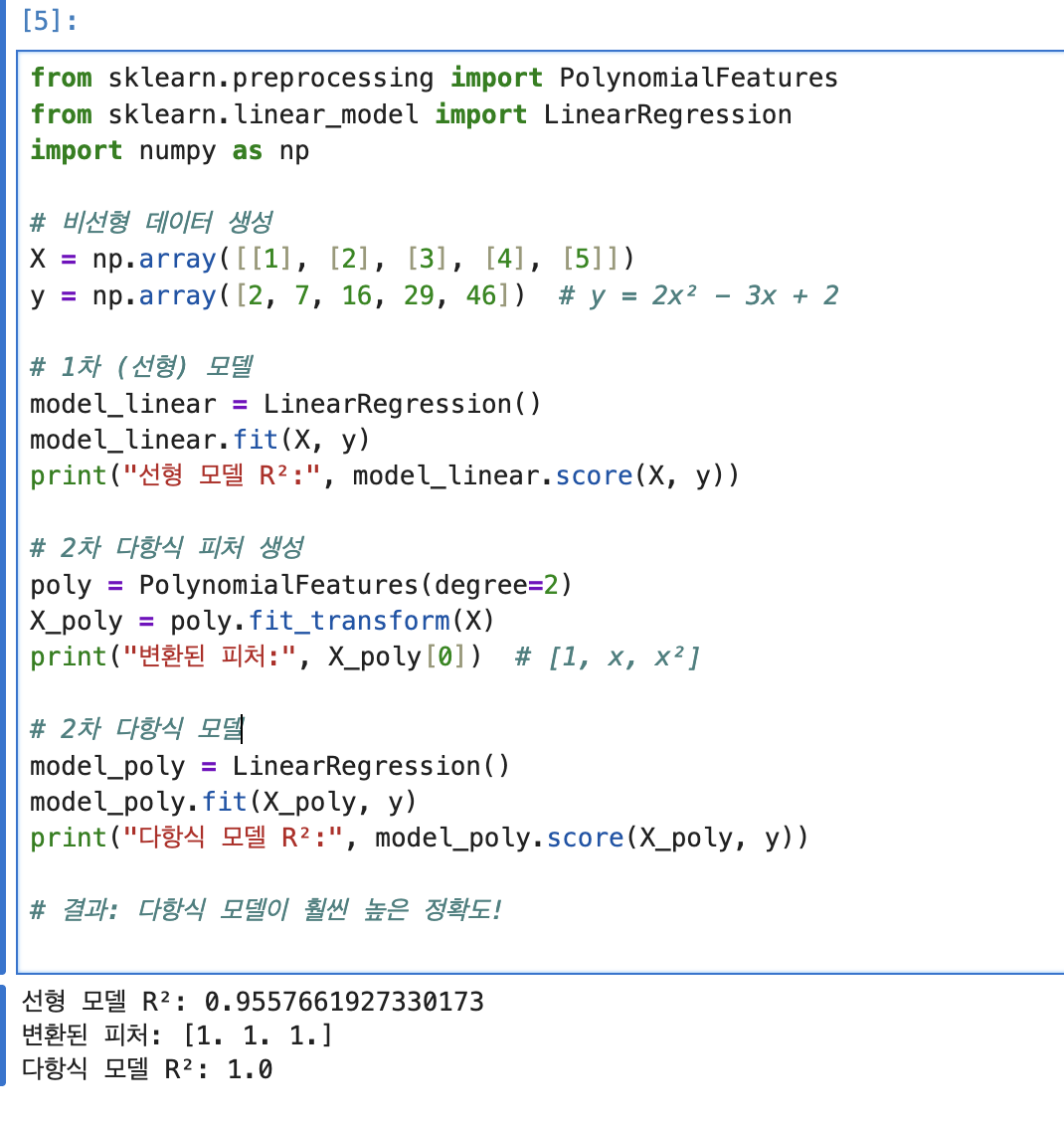
피쳐 엔지니어링에는 3가지 축이 있다.1\. Feature Generation2\. Feature Selection3\. Anomaly Detection피쳐 제너레이션은 데이터에 숨겨진 패턴을 명시적으로 표현하는 것 그 중에 피쳐 제너레이션 방법은 2가지 Binning
5.feature 엔지니어링 - feature SELECTION
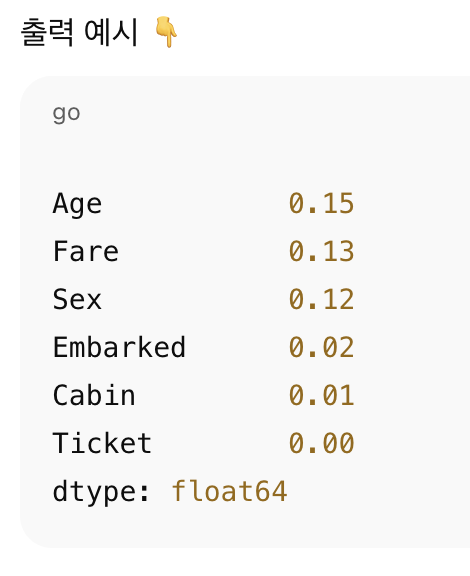
피쳐 엔지니어링에서 generation 다음 feature selection 글이다. feature selection 을 하는 이유는, 모델성능 향상, 학습 시간 단축, Overfitting 방지 등등 아무튼 하면 좋으니 하는거. feature selection 안에
6.SVD , 고급 군집화 기법
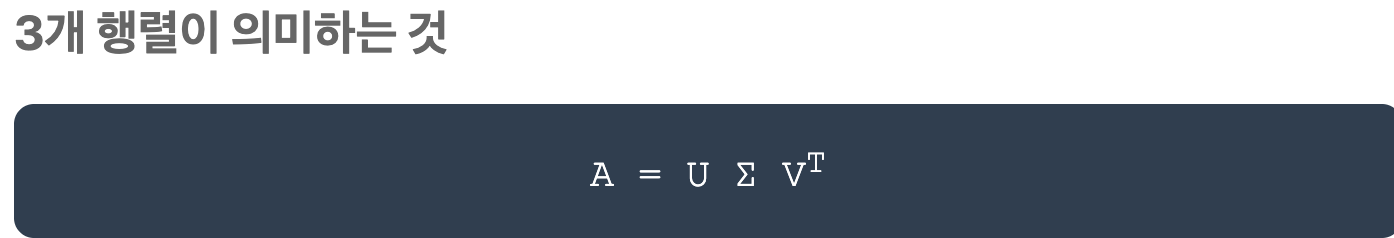
25년 11월 10일 월요일, 오늘도 어김없이 시작하는 오즈코딩 헬스케어 AI수업. 대학교 4학년 2학기 휴학하고 이래도 되나 하는 생각과, 토플 모의고사 봤는데 성적이 생각한 만큼 안나와서 속상한 생각과, 친구들 취직 준비하는거 보면 생각나는 걱정들이 뒤죽박죽 섞인다
7.DBSCAN

25년 11월 11일 빼빼로 데이다. 마트에서 빼빼로 사다가 좋아하는 애들한테 주는 날. .... 그렇다고 한다 이번 글에서 정리할 내용은 DBSCAN 이랑 k-means DBSCAN은 Densiry-Based Spatial Clustering로 앞에서 했던 k-me
8.하이퍼파라미터 튜닝
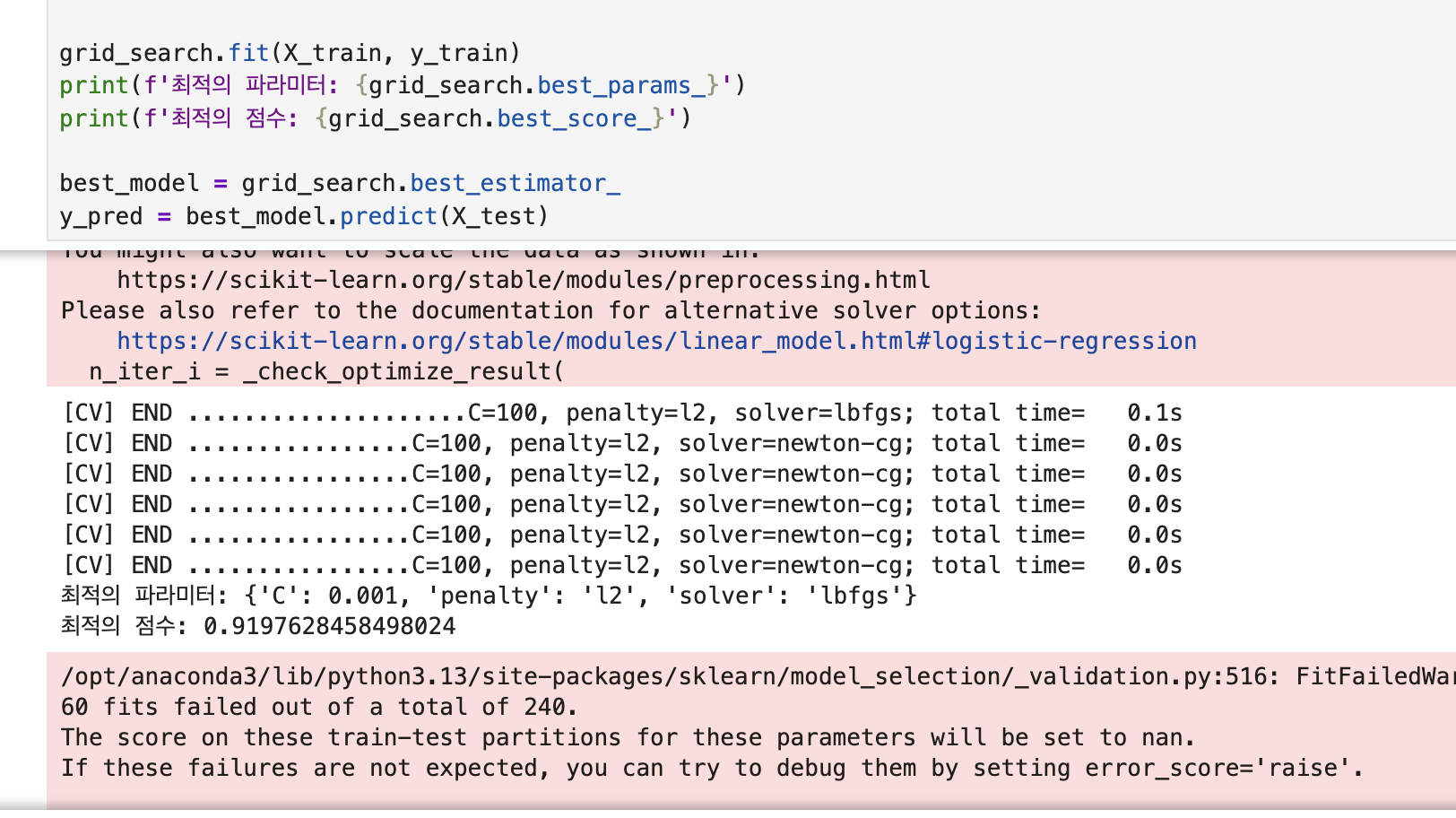
하이퍼 파라미터가 무어냐... 요거는 모델이 배우지 않은 설정값 이라고 봄 요리 하기전에 요리 어떻게 할지 전부 알고 있는 상태(어떤 냄비 쓸지, 불 세기는 어떻게 할지, 몇분 요리할지 등등) 이는 하이퍼 파라미터에 따라 성능이 달라지는데, 최적값은 어떻게 찾는게 좋을
9.SVM(Support Vector Machine)
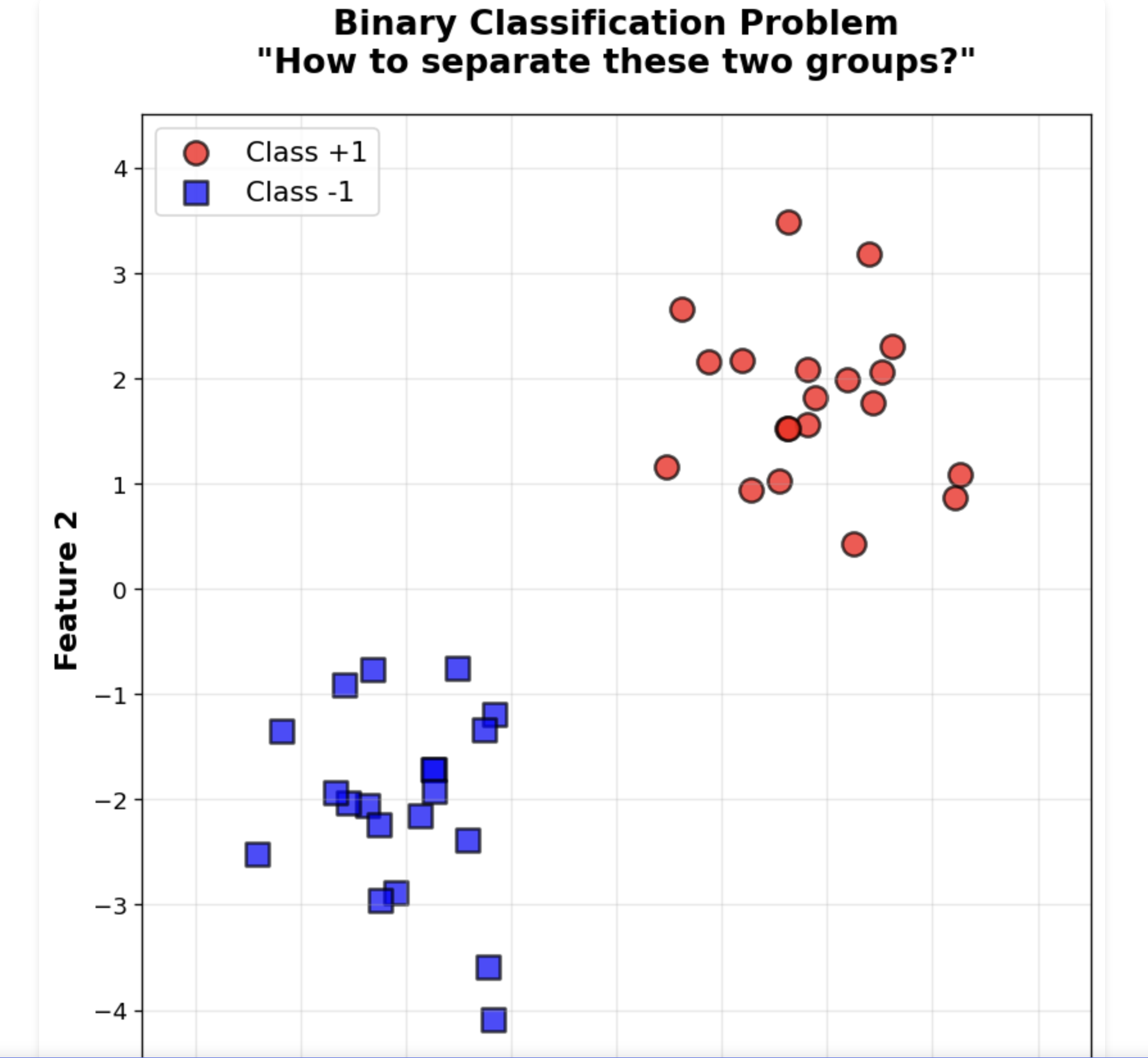
오늘도 어김없이 찾아오는 블로그 정리시간.솔직히 말하면 코드를 하나하나 손으로 쳐봐라 하면은 못치겠지만, 왜 이거를 이렇게 쳤는지 이렇게 글로 정리하면서 진행하면 이해는 된다. 오늘도 팟팅왜써? 가장 좋은 분류 경계를 찾기 위해서생각해보장, 이렇게 데이터가 주어졌는데.
10.SVC 과제 리뷰

하이욤오늘은 어제 마무리 했던 과제를 리뷰해보려 한다어제 한 내용은 솔직히 말하면 함수 다른거 빼고는 다른 데서도 정리 한번 했었는데, 다시 하려니까 기억이 안나서 전에 했었던 코드 다시 보고 다시 쳐보는 걸 반복했었다. 요번에도 정리해서 조금 더 기억력을 올려보려 함
11.앙상블(Bagging)

이번 글에서 정리할 내용은 Decision Tree의 한계와 앙상블 Bagging Random Forest(tree 말고 숲!) Decision tree 한계와 앙상블 일단 Decision tree 가 뭐냐 요런 사진. Decision tree 만들어서 classif
12.앙상블(Bagging) - Random Forest

앞 글에서 bagging에 대해서 정리했는데, bagging만으로는 한계가 부족한 면이보인다. Bagging은 중복을 허용해서 랜덤 샘플을 여러번 만든다음 각 샘플의 판단값을 평균으로 잡는데, (모든 샘플 데이터가 다 비슷), random forest는 서로 다른 방식
13.AdaBoost, Gradient Boosting, XGBoost
이번에 정리할 글은 AdaBoost, Gradient Boosting, XGBoost한마디로 표현하자면 "점점 똑똑해지는 팀 공부법"어떤 문제든 중요도(가중치) 가 똑같다고 한 다음. 한 분류기에다가 문제를 풀린다.어떤 친구가 맞히고 다른 친구는 틀렸다고 하면, 틀린
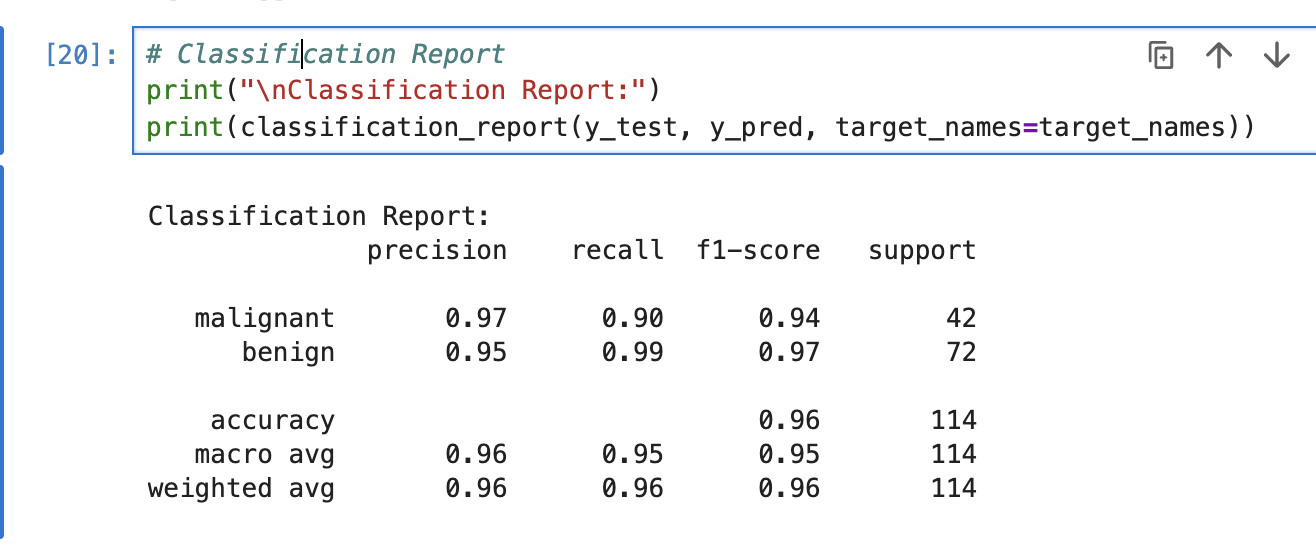
14.머신러닝 7일차 과제 리뷰(task1: ada, GB, XGB활용 / task2: GB-GridSearchCV)
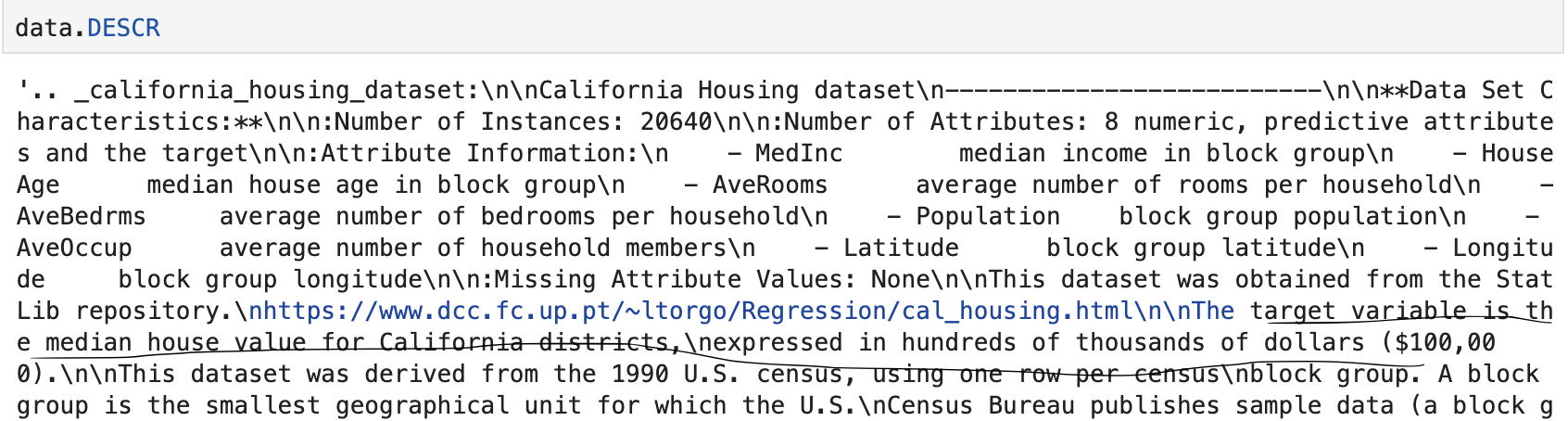
요번 글은 과제 내용 리뷰인데, 나름 요번에는 코드를 모두 직접 써보기도 했고, 그거 가지고 뿌듯해하는 내 자신에 글을 정리해보려 한다.과제1은 사이킷런 데이터셋에서 fetch_california_housing을 활용한다.필요한 기본 모듈은 model_selection
15.251201 딥러닝 2일차 수업 리뷰 (iris데이터 / mnist데이터 / 윤년 데이터)
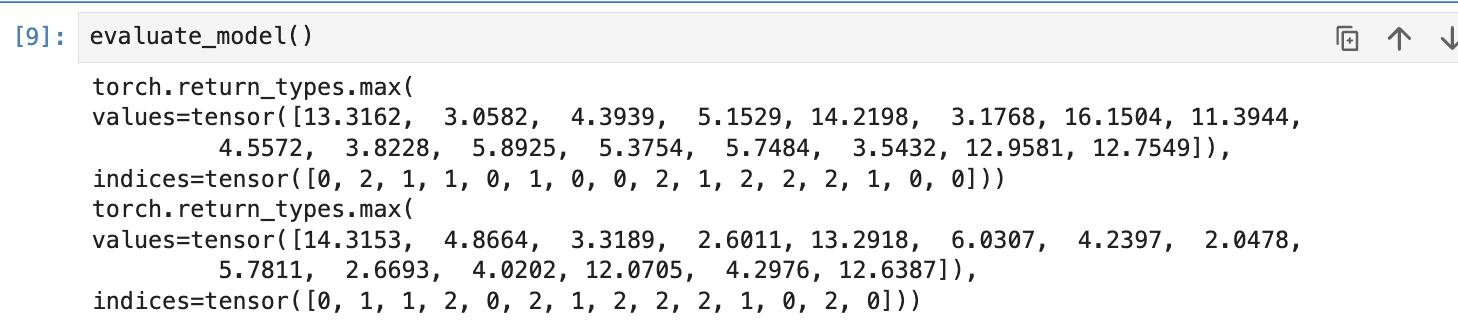
오전 1교시 iris 데이터 가지고 class 만들기 실습 iris 데이터를 가지고 와서 데이터 표준화와 테스트 데이터로 분리한다 이때 데이터가 불균형할 경우에 like 극히 드문 암환자 치료 경우 데이터를 쪼개면 어느 한쪽으로 데이터가 치우쳐질 수 있기에 stra
16.LightGBM 활용

일단 데이터를 분석하는게 가장 중요하다. 여기 월간 데이콘 신용카드 사용자 연체 예측 AI 경진대회 데이터의 칼럼을 보면, family_type 이 있는데 이는 범주형 데이터니 숫자로 변형해준다 LightGBM 모델은 결측치와 범주형 변수를 자동으로 처리할 수 있는
17.Feature Importance, IQR, StandardScaler, feature weight, feature selection
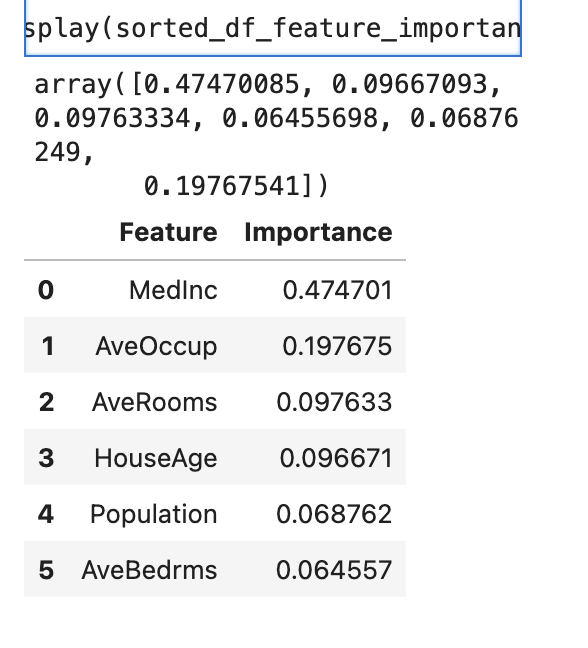
선형 모델의 각 피처 중요도는 해당 피처의 가중치의 절대값을 통해 평가가중치의 절대값이 클수록, 해당 피처는 모델의 에측에 더 큰 영향을 미침선형 모델에서 피처의 스케일이 다를 경우, 가중치를 직접 비교하기 전에 모든 피처를 동일한 스케일로 조정 (Standardsca
18.기본 교차 성능 검증(RandomForestClassifier)
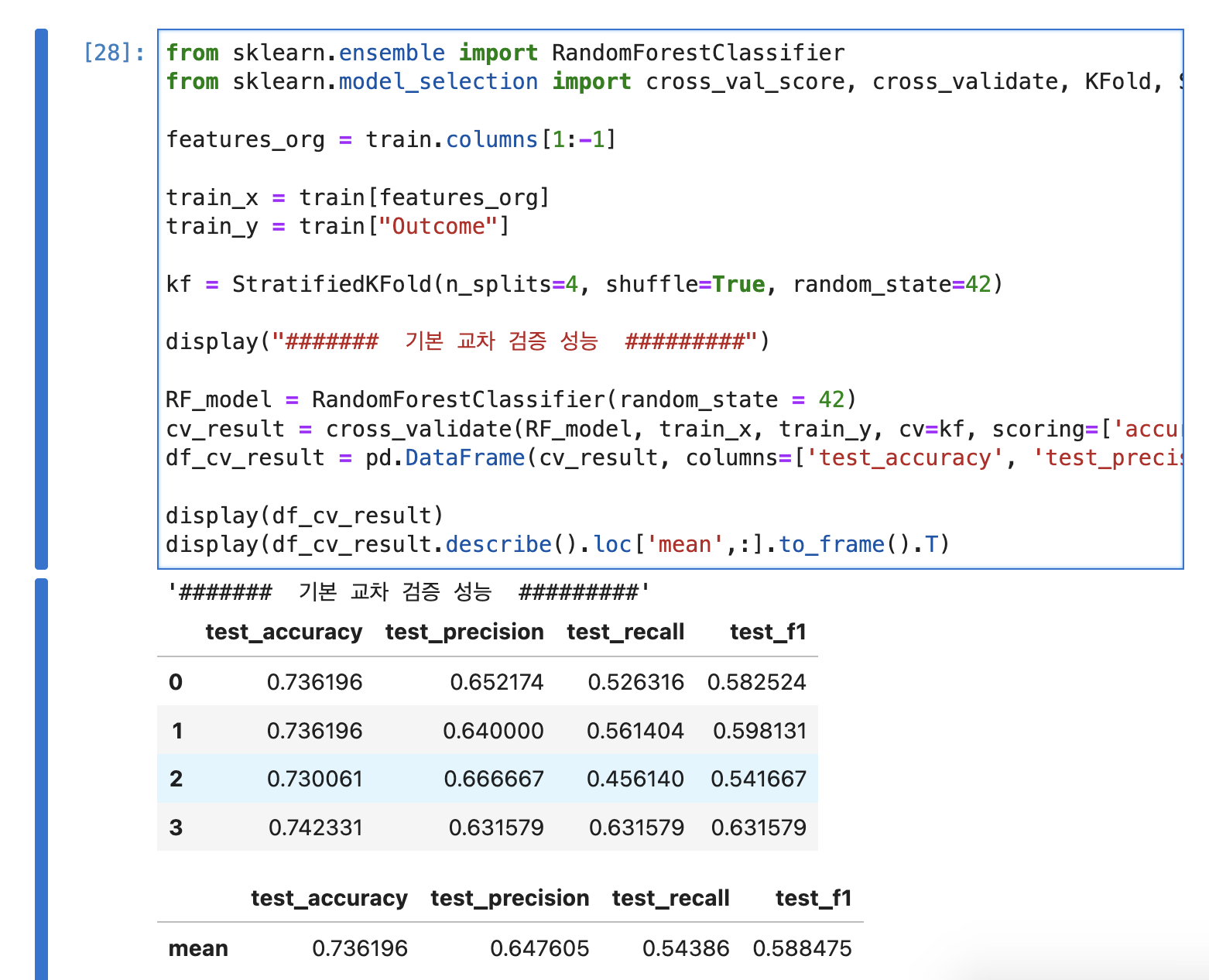
StratifiedKFold를 사용하여 훈련 데이터를 4개의 폴드로 나누고, 각 폴드에서의 정확도, 정밀도, 재현율, F1 점수를 계산features_org 로 train 칼럼중 Outcome 칼럼을 제외한 다른 칼럼 선택train_x 데이터는 Outcome 칼럼 제외