피쳐 엔지니어링에서 generation 다음 feature selection 글이다. feature selection 을 하는 이유는, 모델성능 향상, 학습 시간 단축, Overfitting 방지 등등 아무튼 하면 좋으니 하는거.
feature selection 안에는 filter method, wrapper method, embedded method 가 있다. 필터 방법은 통계적 지표로 피처 평가, 뤱퍼 방법은 모델 성능으로 지표 평가, embedded 방법은 모델 학습 중 피쳐 선택
그 다음에 filter method 안에는 상관계수-(Pearson correlation), Chi-Square, Mutual Information, Variance Threshold가 있다.
filter method
상관계수(corr)
상관계수는 앞에서 히트맵 그릴 때 corr 요 클래스해서 -1부터 1까지 값을 도출한다.
Chi-square(카이제곱 검정)
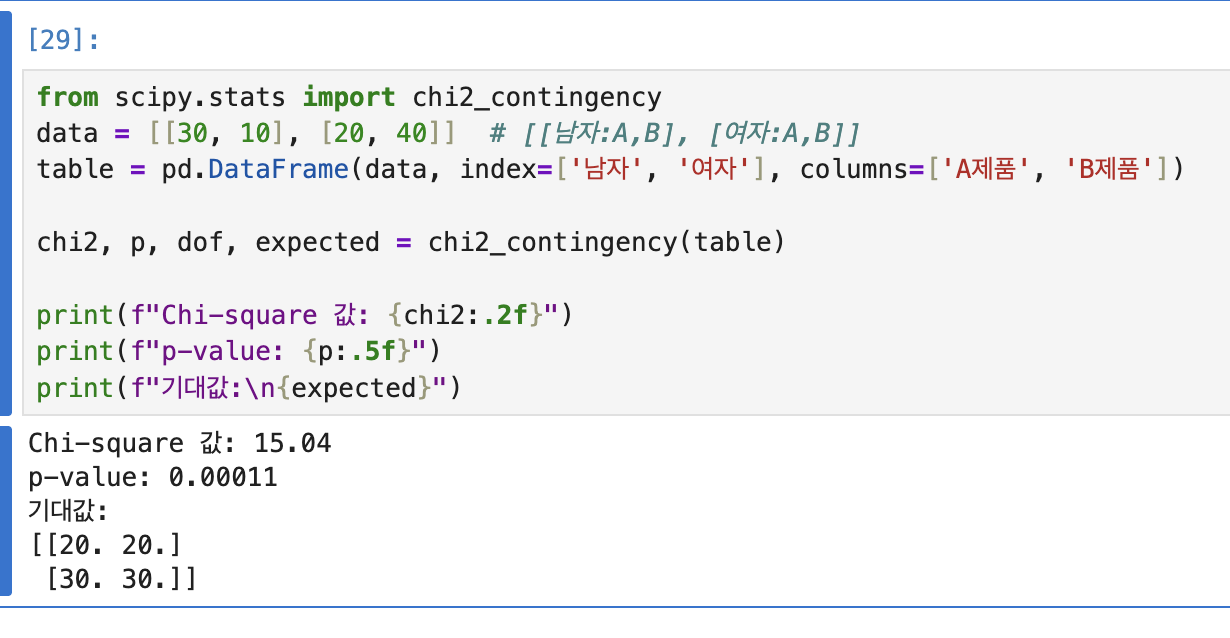
카이제곱 검정은 두 가지 범주형 데이터가 관련이 있는지 확인하는 방법. 값은 (실제-기대)^2 / 기대 값을 계산해서 나오는 값이 카이제곱 통계량 X^2. 데이터 넣을 때는 pandas표로 정리해서 넣어주면 됨. 아무래도 카이제곱 검정은 두 가지 범주형 데이터를 가지고 관련 유무를 판단하는 거다보니, 전체 행렬 데이터를 넣으면 에러뜸. 즉 두 가지 행렬을 지정 해서 클래스에 넣어주어야 한다
p-value는 정말로 관련이 없다고 가정했을 때, 지금처럼 차이가 우연히 나올 확률 값. 나오는 값이 0.05 이하면 우연치고 너무 드물다 👉 관련 있다고 판단! p가 크다는 뜻은 이 정도 차이는 우연히도 자주 나올 수 있다는 뜻!
scipy.stats모듈에서 chi2_contingency 클래스를 가지고 온다. 전에 데이터 유사도 관계 확인할 때 p-value 했었는데, 그때 나온 값. chi2_contingency 클래스 쓴 거는 요번이 처음인듯
F-statistics(ANOVA)
그룹 간 평균 차이 검정기술. F값이 크면 그룹 평균 차이가 크다는 뜻, 구별하기쉽다. F값이 작으면 그룹 평균 차이가 작다, 구별하기 어렵다.
쓸 때 sklearn.feature selection 모듈에서 SelectKBest 클래스와 f_classif 함수를 가져온다.
SelectKBest는 각 피쳐를 하나씩 평가해서 점수가 높은 상위 k개만 남김. f_classif는 각 피처가 클래스(타깃)를 얼마나 잘 구분하는지를 “F값”으로 점수 매겨 주는 함수. F값 = 그룹 간 분산 / 그룹 내 분산.
그러니 F값이 크다는 건 그룹 간 분산이 크다는 거니 비교 분석이 더 명백해진다는 뜻. k=2는 그중 상위 두개만 고른다는 뜻
# 1. F-statistic (ANOVA)
selector_f = SelectKBest(score_func=f_classif, k=2)
X_f = selector_f.fit_transform(X, y)
print("F-statistic scores:", selector_f.scores_)
print("선택된 피처:", selector_f.get_support())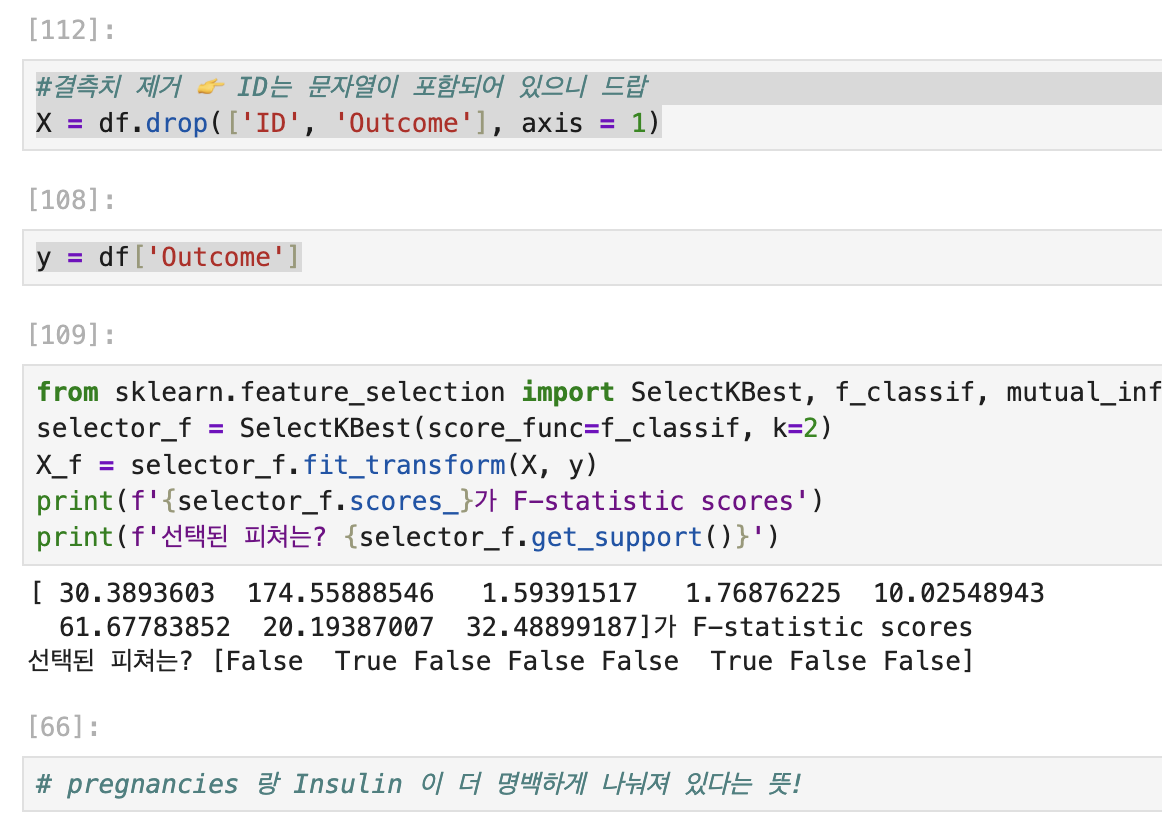
Mutual Information
feature X를 알게되면 Target Y에 대해서 얼마나 더 알게되나?
여기서는 score_func로 mutual_info_classif를 적용한다. 피쳐가 얼마나 많은 정보를 주는지 측정하는 함수
# 2. Mutual Information
selector_mi = SelectKBest(score_func=mutual_info_classif, k=2)
X_mi = selector_mi.fit_transform(X, y)
print("MI scores:", selector_mi.scores_)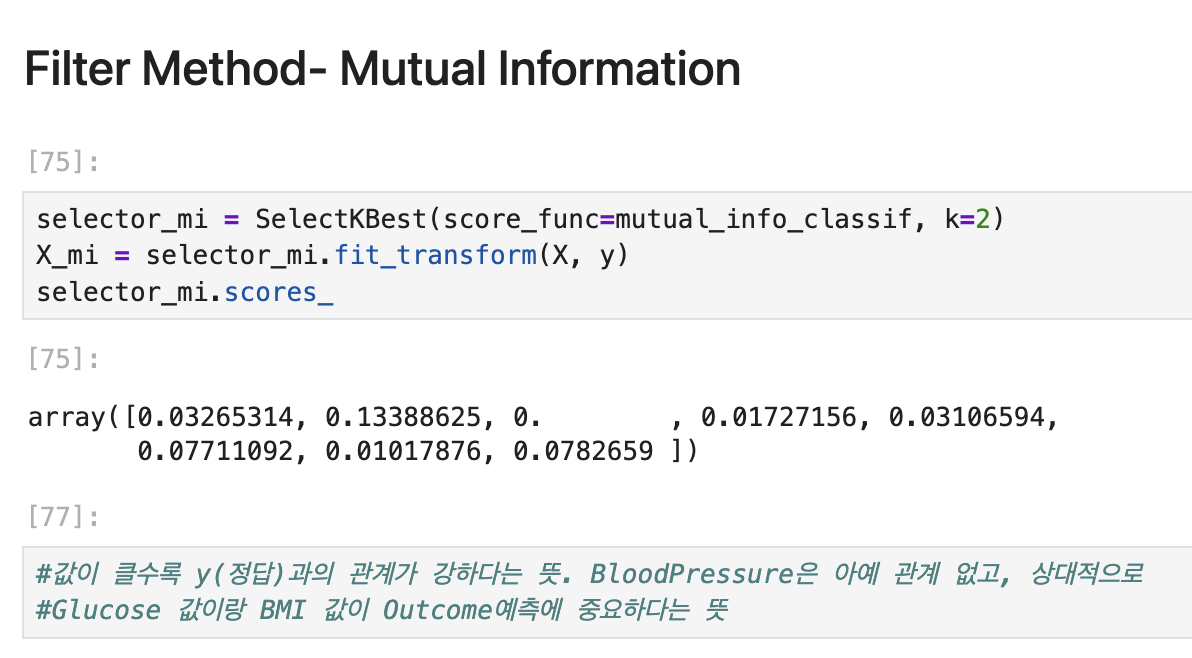
보통 출력하면 값이 이렇게 나오는데, 보면 Age행이 생존과 꽤 관련이 있다고, 다른 행들보다 상대적으로 값이 크다고 말해줌.
Variance Threshold(분산 임계값)
여기서는 VarianceThreshold 클래스를 가지고 온다. 이 클래스는 각 피쳐의 분산을 계산해서 분산이 0.2 이하인 열들을 제거하는 클래스. 코드 보면 VarianceThreshold(threshold=0.2)로 분산 한계점, 임계값을 어디로 했는지 지정해줌.
여기도 데이터를 한 다음 fit_transform(X)를 학습해주는 과정을 잊지말기
그러면 코드는 X_var은 분산이 0.2아래인 것들은 다 자르고 남은 array
from sklearn.feature_selection import VarianceThreshold
selector_var = VarianceThreshold(threshold=0.2)
X_var = selector_var.fit_transform(X)
print("Variance:", selector_var.variances_)
print("선택된 피처 수:", X_var.shape[1])
Wrapper Method
요거는 모델 성능으로 최적 조합 찾기.
Wrapper Method 는 Forward Selection(전진 제거), Backward Elimination(후진 제거), RFE(Recursive Feature Elimination) 요렇게 세개가 있다. 이를 하는 이유는 최적의 조합을 찾을 수 있는 반면에 이를 하기 위한 비용이 많이 든다는 점이 단점이다.
Forward Selection - 전진 선택
성능이 가장 많이 좋아지는 피쳐를 하나씩 추가해가면서 성능 확인, 성능이 향상될 때까지 계속 반복한다. 요리할 때 보면 맛있는 요리를 완성시키기 위해 재료를 하나씩 추가한다고 생각하면 될듯
Backward Elimination - 후진 제거
모든 피쳐에서 시작해서, 하나씩 제거. 요리를 만들었는데 맛이 없었다, 다음에 요리할 때는 재료를 하나씩 빼고 조리.
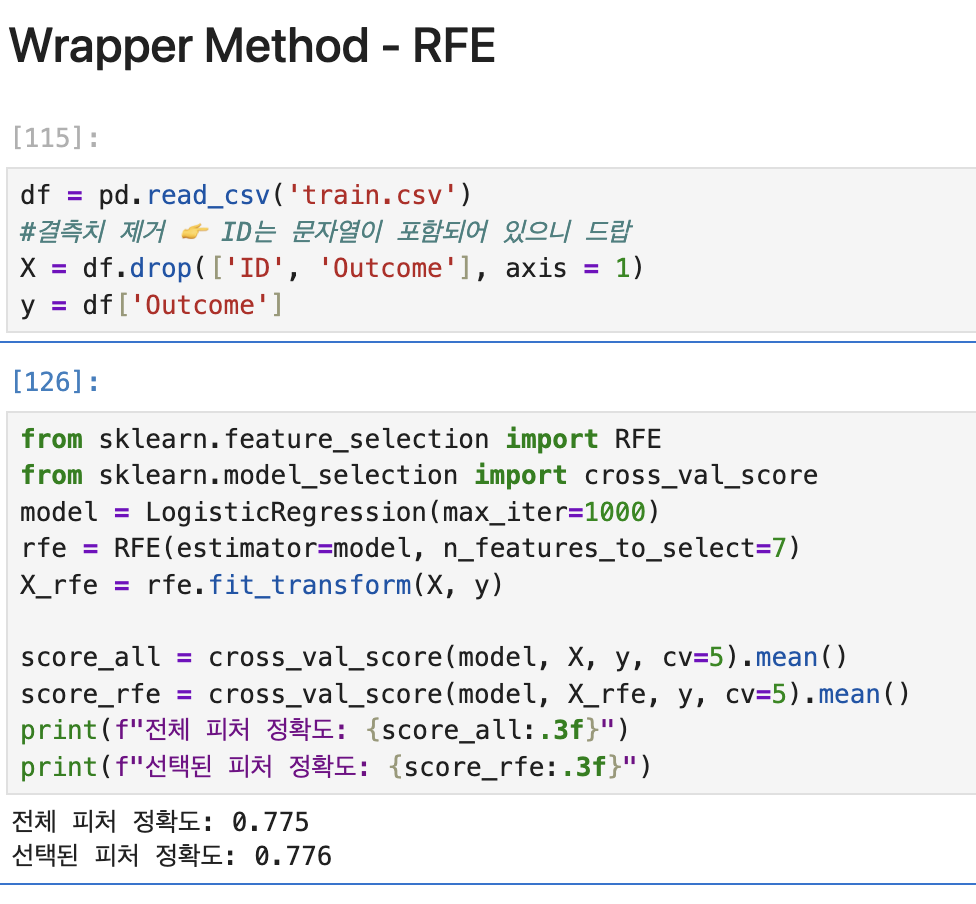
RFE
모델 기반으로 제귀적 제거, 중요도가 낮은 피쳐부터 제거. 요 부분이 코딩으로 가능해진다.
cancer 데이터 가져오기
cancer = load_breast_cancer()
X, y = cancer.data, cancer.targetRFE로 피처 선택 max_iter은 최적해를 찾는 최대 반복 횟수.
estimator은 위에서 로지스틱 회귀10000번 돌린 모델을 가지고 와서 학습시킴.
학습된 모델은 각 피쳐마다 중요도를 계산. 그 중 높은 점수 10개를 도출
중요도는 로지스틱 회귀계수를 이용해서 피쳐 중요도를 판단. 가가 피처마다 계수 w가 있는데 이 계수가 낮은 피쳐먼저 제거하기 시작한다.
model = LogisticRegression(max_iter=10000)
rfe = RFE(estimator=model, n_features_to_select=10)
X_rfe = rfe.fit_transform(X, y)
# 성능 비교
from sklearn.model_selection import cross_val_score
score_all = cross_val_score(model, X, y, cv=5).mean()
score_rfe = cross_val_score(model, X_rfe, y, cv=5).mean()
print(f"전체 피처 정확도: {score_all:.3f}")
print(f"선택된 피처 정확도: {score_rfe:.3f}")성능 비교는, sklearn.model_selection의 모듈에서 cross_val_score(model, X, y, cv = 5) - 교차 검증으로 모델의 성능을 평가하는 함수. model은 estimator, cv=5라고 하면 데이터를 5등분 해서 5번 평가. 80퍼센트가지고 학습하고 20퍼센트 가지고 테스트 한다는 뜻.
모델이 전체 데이터에서 얼마나 안정적으로 작동하는지 알 수 있음.
Embedded Method
엠베디드 방법은 이름 그대로 모델이 학습되는 과정(embedded)안에서 '어떤 피처가 중요한지'를 스스로 판단해서 골라주는 방법.
Lasso (Least Absolute Shrinkage and Selection Operator)
그대로 해석하면 계수드를 작게 줄이고, 덜 중요한 피쳐는 완전이 0으로 만들어버린다. 이걸 판단할 때 coef_ 상태를 써서 가중치를 판단하는데, 이게 - 이든 +이든 상관없이 가중치의 절댓값이 커서 해당 데이터에 영향을 주냐 안주냐만 판단하는 피쳐 선택 방법임!
Lasso는 모델이 예측을 하면서 동시에 '덜 중요한 변수'의 계수를 0으로 줄여버림. 즉, 학습 중에 '너는 별로 쓸모없네' 하고 자동으로 버린다는 뜻.
예를들면, 수능 공부하는데 대학교에서 수학, 영어 점수 비중이 더 높다. 그러면 상대적으로 비중이 낮은 한국사, 사회, 베트남어 같은거는 공부시간을 0으로 줄여버리는 느낌스
데이터 로드
from sklearn.linear_model import Lasso, Ridge
from sklearn.tree import DecisionTreeClassifier
import numpy as np
from sklearn.datasets import load_breast_cancer
X, y = load_breast_cancer(return_X_y=True)요거는 파이썬에서 cancer 데이터 불러오는데, 데이터 표에 피쳐들 이름 다 붙여넣는 코딩, 부를 때 pd.DataFrame 에다가 cancer.data, columns = cancer.feature_names 해서 가지고 온다.
# Load the dataset from scikit-learn.
cancer = load_breast_cancer()
# cancer.keys() # to see all the attributes
cancer_df = pd.DataFrame(cancer.data, columns = cancer.feature_names)
cancer_df['target'] = cancer.target
cancer_df.head()라쏘 코드 설명
여기 코드보면 alpha 값으로 0.01을 지정해주는데, 얼마나 강하게 피처들의 계수를 0으로 줄일까의 조절 레버를 지정해주는 것. 0.00001이면 거의 버리지 않겠다는 거고, 0.01 이면 적당히 버리겠다는 거고, 1이면은 그냥 완전 100퍼센트 똑같지 않은이상 절대 남기지 않겠다는 뜻!
# 1. Lasso
lasso = Lasso(alpha=0.01)
lasso.fit(X, y)
lasso_coef = np.abs(lasso.coef_)
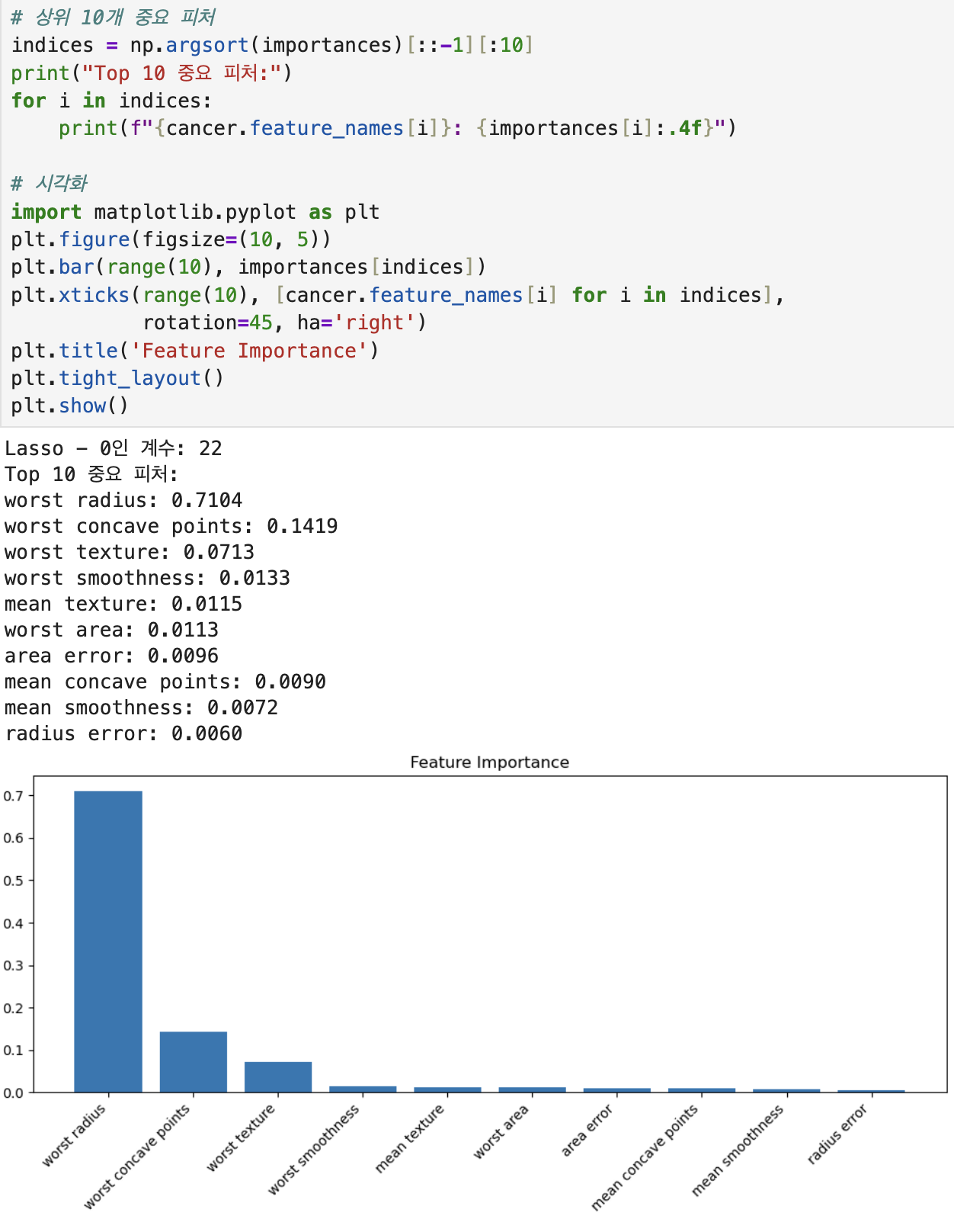
print("Lasso - 0인 계수:", np.sum(lasso_coef == 0))
rf = DecisionTreeClassifier(max_depth=5, random_state=42)
rf.fit(X, y)
importances = rf.feature_importances_의사 결정 나무 확인. DecisionTreeClassfier은 분류용 결정나무를 만든다는 뜻이고 max_depth = 5는 나무의 최대 깊이를 5로 제한한다는 뜻. 즉 나무의 가지가 얼마나 깊게 자랄 수 있는지 설정해주는 거다. (질문 5개만 하라는 뜻)
featureimportances 상태는 피처가 얼마나 중요한지 점수로 알려주는 과정. 값이 클수록 결과에 큰 영향을 준다는 뜻이다.
rf = DecisionTreeClassifier(max_depth=5, random_state=42)
rf.fit(X, y)
importances = rf.feature_importances_시각화 해보면 요렇게 나온다. 위에서 featureimportances를 써서 중요도를 구했고, 그 중 중요한거 10개를 골라서 막대그래프 시각화 한 것임. np.argsort(importances)는 작은 큰 순으로 인덱스 정렬하고 [:: -1]은 순서를 뒤집어서 내림차순으로 인덱스 정렬, [:10]은 앞에서 10개만 중요한거 top 10개만 가지고 온다는 뜻. 그래서 indices에는 top10개 피쳐들만 들어있는 상태다.
이렇게 feature engineering - feature selection 부분이 끝. 이상치 정리부분도 블로그 적어야 하는데, 내용이 너무 많다 ㅋㅋ 뭔지 모르겠지만 일단 끝까지 버텨보자
