다음날이 되고 정리를 시작한다. 어제 미니 프로젝트 했던거 블로그 쓰고 나니 12시여서 일단 피곤해서 자고 내일 하자 함. 막상 오늘 일어났는데 피곤해서 10시 전까지 쭉 자버림 ㅎㅎ
2일차 주제는 회귀분석과 선형회귀 점들 사이에서 숨겨진 관계를 찾아내는 방법이다.
자잘한거 없애고 진짜 기억하고 싶은 내용만 골라서 정리해보자. 아래 정리는 그대로 복붙해서 실행하면 결과가 도출되도록 할 예정
0. 일단 필요한 모듈들 import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
#sepal Length(꽃받침 길이) 👉 Petal Length(꽃잎 길이)
#목표 꽃받침 길이로 꽃잎 길이 예측하기1. 데이터 로드하기 + 데이터 범주 구하기
-
data해주는 이유는? (iris.data부분)
data해주는 이유는, 이 데이터 자료 근거로 target 값을 유추해야 하기 때문, 첫번째 열 전부를 데이터로 쓴다는 점. (sepal length, width 랑 petal length, width)네개 중 하나 쓴다는뜼 -
reshape(-1, 1) 뭔데?
-1은 알아서 채워라~ 라는 뜼 1은 1행으로 세워라,
두번째 거 3으로 놓으면 3열로 나옴
2.1 reshape(2, 3)하면 2행 3열로 채움 but 여기서는 총 데이터 갯수가 150개 이니 행과 열의 곱 즉 넓이 값이 데이터 크기와 같아야 함
2.2 아니면 에러 뜸 그러니 여기서는 reshape(a, b) a*b값이 150 정확히 맞아야 결과가 나옴.
👉 이렇게 계산하기 귀찮으니 -1 넣어주는것임!
2.3 reshape 하는 이유는 predict 함수는 2차원 데이터를 요구하기 때문 -
아래 데이터를 해석하면 꽃받침 길이와 꽃잎 길이 데이터를 가져옴(까지 완료)
# Iris 데이터 로드
iris = load_iris()
# X: Sepal Length (꽃받침 길이)
X = iris.data[:, 0].reshape(-1, 1)
# y: Petal Length (꽃잎 길이)
y = iris.data[:, 2]
print(f"데이터 개수: {len(X)}개")
print(f"X 범위: {X.min():.1f} ~ {X.max():.1f} cm")
print(f"y 범위: {y.min():.1f} ~ {y.max():.1f} cm")
#여기 두가지 데이터 범주 내에서 이제 target값을 유추유추2. 데이터 뽑은거 분포그림 확인 (scatter)
#scatter plot으로 데이터 확인
#sepal length랑 petal length 두 데이터 범주 비교
plt.figure(figsize=(10, 6))
plt.scatter(X, y, alpha=0.6, s=80,
edgecolors='black', linewidth=1)
plt.xlabel('Sepal Length (cm)', fontsize=12, fontweight='bold')
plt.ylabel('Petal Length (cm)', fontsize=12, fontweight='bold')
plt.title('Iris: Sepal Length vs Petal Length',
fontsize=14, fontweight='bold')
plt.grid(True, alpha=0.3)
plt.show()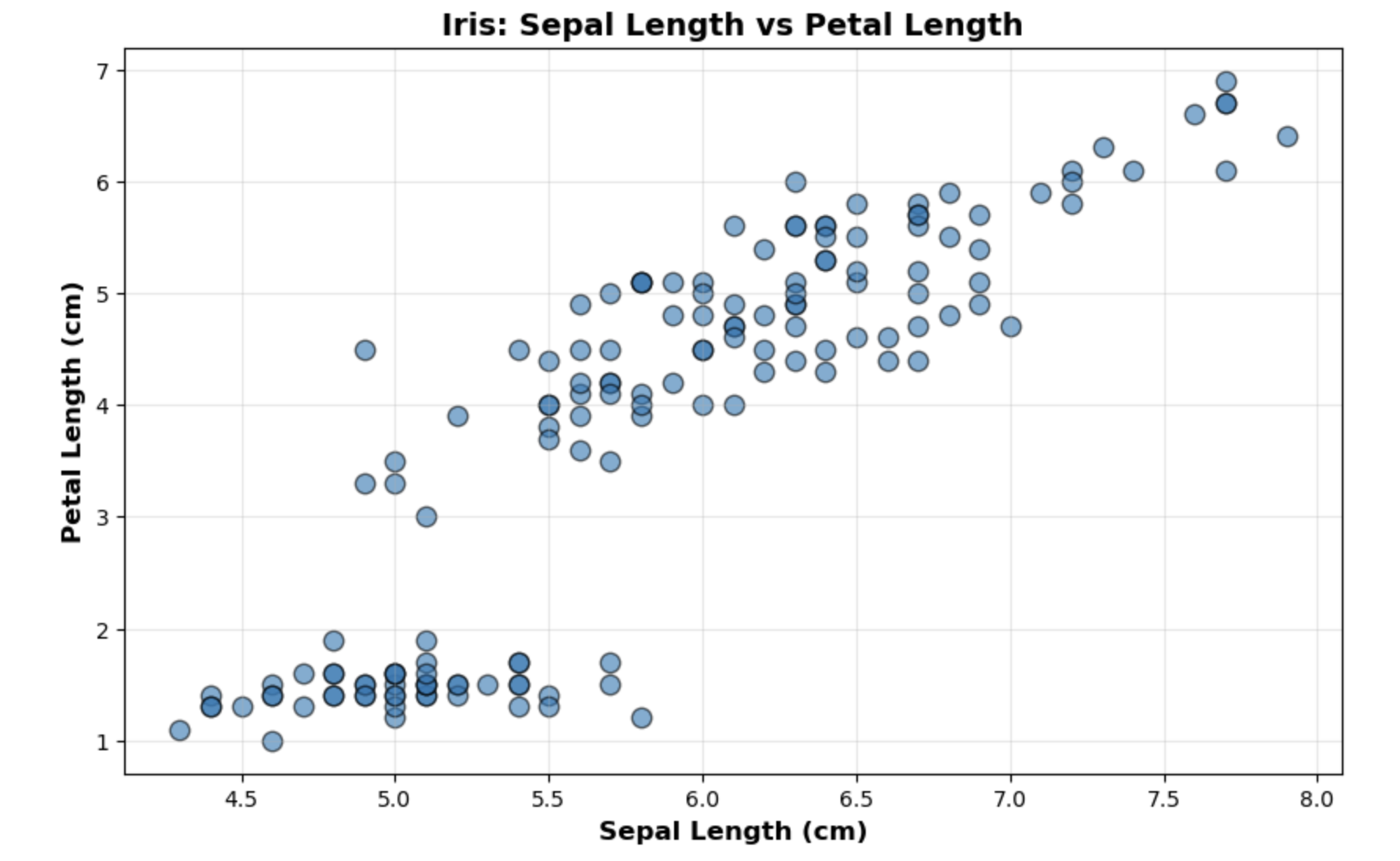
3. 데이터 분할
- 데이터 분할하는 이유는 train- 학습용, test -시험용. 비유를 들자면 train은 시험에 비슷하게 나오는 문제들이고 test는 진짜 시험문제
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state=42
)4. 모델 학습
- model = LinearRegression()을 한 이유는 나는 이 데이터들 가지고 직선 형태로 표현하고 싶어를 컴퓨터에 주문 내려놓는 과정. (y = wx + b 형태)
- model.fit(X_train, y_train)은 위에서 분할해놓은 것을통해 최적의 직선을 찾는 과정.
- w = model.coef_[0] 요거는 기울기를 의미, 0이 들어간 이유는 입력된 값이 1차원 함수의 기울기 하나이기 때문에 0. 만약 기울기 값이 여러개가 되면 0, 1, 2 --- 입력가능 각 순서에 맞는 기울기 도출
- model.intercept_ 는 y 절편값 도출
- w:3f에서 w는 위에 지정해놓은 기울기 값, :3f는 소수점 3자리까지 놓는거. 번외로 지수표기는 x:2e, 퍼센트 표기는 x:2% 하면 자동으로 확률로 표기
model = LinearRegression()
model.fit(X_train, y_train)
w = model.coef_[0]
b = model.intercept_
print(f" 학습 완료!")
print(f"가중치 w (기울기): {w:.3f}")
print(f"편향 b (절편): {b:.3f}")
print(f"찾은 식: y = {w:.3f}x + {b:.3f}")
5. 데이터 예측
- 이거 하면서 y_test값이 에러가 뜬다. 왜 뜰까 찾아보니 iloc는 numpy에 적용이 안된단다~. 찾아보니 iloc는 pandas 모듈에 심어져 있는 함수. 그렇기에 y_test 데이터를 pandas로 변경해준다.
y_test = pd.Series(y_test)
2. 위에서 model.fit(X_train, y_train)을 통해 모델 학습시켰던거 기억날거다. fit은 기울기라고도 언급함. 그러면 predict는 model.predict(X_test) 처럼 X 테스트 데이터를 넣어서 실제 어떻게 값이 도출되는지 예측하는 것
3. 그렇기에 y_pred는 학습된 모델에다가 X_test값을 넣어서 실제로 어떻게 값이 도출되는지 예측된 값
y_pred = model.predict(X_test)
y_test = pd.Series(y_test)
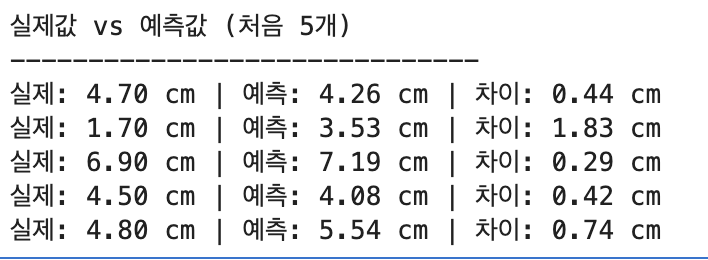
print("실제값 vs 예측값 (처음 5개)")
print("-" * 30)
for i in range(5):
print(f"실제: {y_test.iloc[i]:.2f} cm | "
f"예측: {y_pred[i]:.2f} cm | "
f"차이: {abs(y_test.iloc[i] - y_pred[i]):.2f} cm")여기서 for 문을 써서 처음 5개만 골라본다
요거는 그냥 내가 고쳐야 할 점인데. 항상 내가 pd.Series(y_test)를 하든 뭘 하든 입력해야 하는 값을 이렇게만 두고 그 다음으로 넘어가지 않는다.
pd.Series(y_test)
#항상 이렇게만 해서 왜 에러나는지 찾아봄
y_test = pd.Series(y_test)
#이렇게 해야 pd.Series값이 y_test에 적용된 체로 저장됨6. 성능평가
성능 평가하는 방법은 여러가지가 있지만, 이번에는 mse활용하는것만 다뤄보자
1. mse는 mean_squared_error: 평균 제곱 오차
2. r2_score 함수는 y_test 값과, y_pred 값이 얼마나 일치하는지 확인하는 함수. 이를 점수로 매김
mse = mean_squared_error(y_test, y_pred)
#1로 갈수록 더 커진다
r2 = r2_score(y_test, y_pred)
print("=" * 40)
print(" 모델 성능 평가")
print("=" * 40)
print(f"MSE (평균 제곱 오차): {mse:.3f}")
print(f"RMSE (평균 오차): {np.sqrt(mse):.3f} cm")
print(f"R² Score (결정계수): {r2:.3f}")
print("=" * 40)- 함수는 요렇게 나오고 데이터를 분석해보면, mse랑 rmse는 말그대로 실제 데이터와 평균 오차값 그 값을 루트 씌운 값이고, R^2 score결정 계수는 1로 갈수록 좋은 데이터라는 것

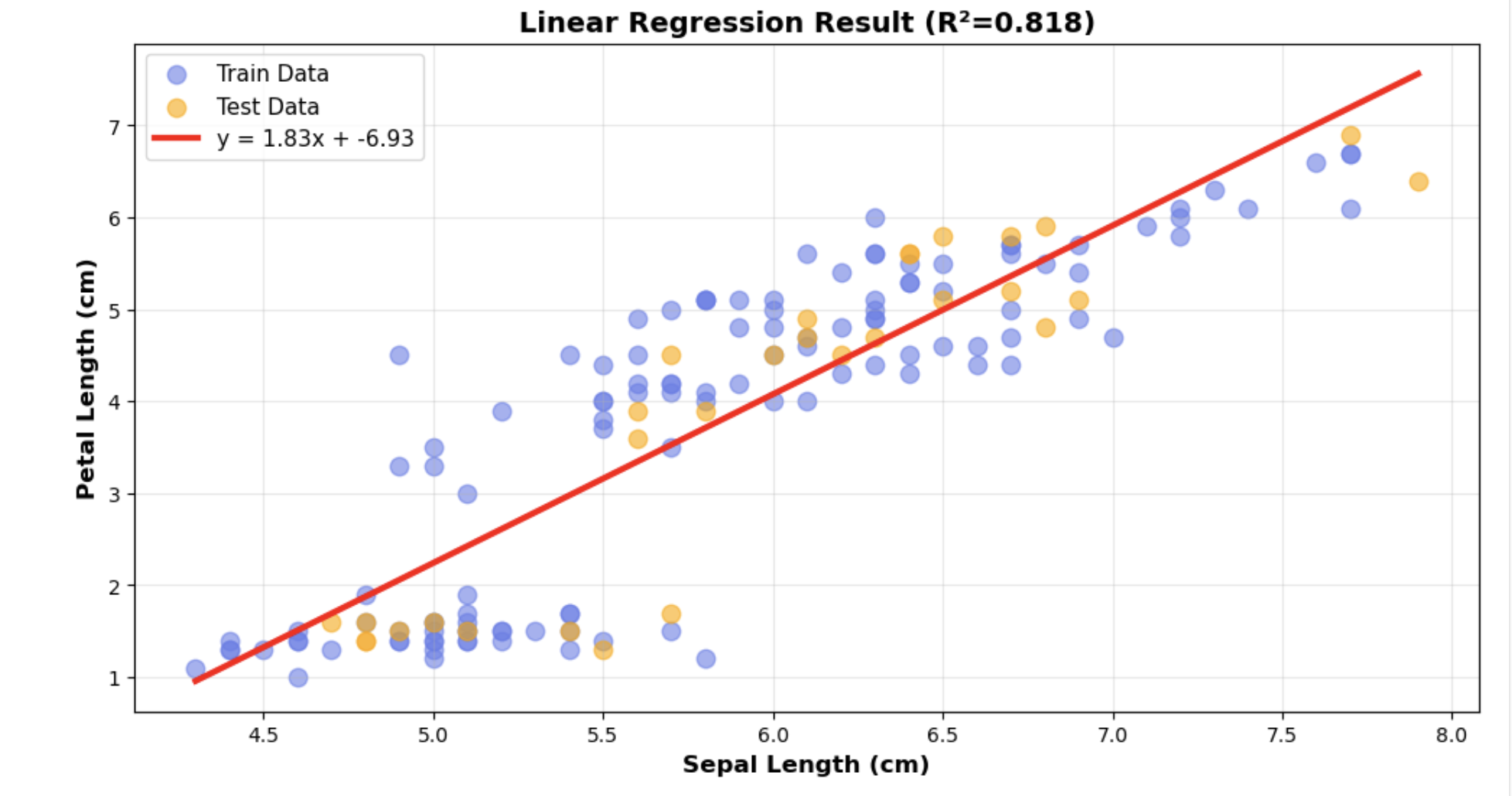
7. 결과 시각화
- np.linespace(a, b, 100) a와 b사이에 100개를 같은 구간으로 나누어서고른다는 뜻
- reshape(-1, 1) n행 1열 짜리 데이터로 만든다는 뜻. 보면 알겠지만 predict 함수는 2차원 배열을 넣어주어야 함. 그렇기에 shape을 통해 데이터 타입 변경 해주어야 함
- scikit-learn 함수는 모델을 배우고 예측하고 평가하는 도구 상자. 예시함수 train_test_split(), LinearRegression(), precit(). 요렇게 쓰는 이유는 머신러닝을 구현하기 위한 함수를 만드는 거는 너무 어렵기 때문에 똑똑한 분들이 만들어 놓은거 가져다가 써야함
.fit() #기울기 계산
.predict() #예측
mean_squared_error() #성능평가
plt.figure(figsize=(12, 6))
# Train 데이터
plt.scatter(X_train, y_train, alpha=0.6, s=80,
color='#667eea', label='Train Data')
# Test 데이터
plt.scatter(X_test, y_test, alpha=0.6, s=80,
color='orange', label='Test Data')
#선형 회귀 그래프 그리기
X = iris.data[:, 0].reshape(-1, 1) #꽃받힘 데이터
X_line = np.linspace(X.min(), X.max(), 100).reshape(-1, 1)
y_line = model.predict(X_line)
plt.plot(X_line, y_line, 'r-', linewidth=3,
label=f'y = {w:.2f}x + {b:.2f}')
plt.xlabel('Sepal Length (cm)', fontsize=12, fontweight='bold')
plt.ylabel('Petal Length (cm)', fontsize=12, fontweight='bold')
plt.title(f'Linear Regression Result (R²={r2:.3f})',
fontsize=14, fontweight='bold')
plt.legend(fontsize=11)
plt.grid(True, alpha=0.3)
plt.show()데이터를 보면, (X_train, y_train)값 + (X_test, y_test)값을 통해 scatter 함수를 그렸고, 학습 시켰던 값들 가지고 선형회귀 함수를 빨간색 그래프로 그렸다.
너무 길어서 한번 끊고 다음 다중 선형 회귀로 이어가자
