Exploration 6
오늘의 노드와 프로젝트는 GPT-2와 같은 문장 생성기를 만드는 것이었다. 노드에서는 셰익스피어 연극 대본으로, 프로젝트에서는 팝송 가사로 문장 생성기를 만들었다.
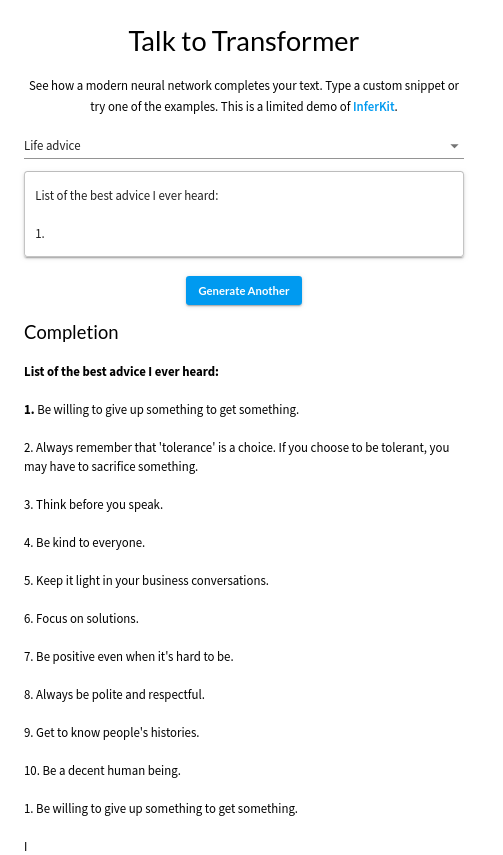
GPT-2는 문장의 첫 부분을 쓰면 나머지 부분을 작문해주는 2019년에 발표된 인공지능이다. 아래의 사진은 GPT-2로 생성한 인생의 조언인데, 예상보다 나쁘지 않다. (참고로 2020년 5월에 GPT-3이 발표되었다.)
이번 프로젝트는 어떻게 하는 건지 모르고 하다 보니 모델이 완성되고, 학습과 평가까지 금세 끝났다. 학습에서 조금 헤맬 뻔 했는데, 조금은 어이없이 해결되었다. 이번에는 이전까지 만들었던 모델과 달리 정답이 정해진 것이 아니라 그런지 정확도는 없이 손실만 구할 수 있었다. 그런데 이 부분을 그래프로 보고 싶어서 노드에 있는 그대로 그래프에 넣었더니 자꾸만 에러 메시지가 나오는 것이었다. 그래프를 그리기 위해 이전에 배웠던 것이나 이전 프로젝트를 보고 넣어보다 보니 학습 부분이 어느새 해결되어 있었다. 소 뒷걸음치다가 쥐 잡은 격이라는 속담이 생각나는 순간이었다.
이해는 못 했지만 프로젝트는 대강 완성하고, 손실을 줄이기 위해 embedding size와 hidden layer size에 다양한 파라미터를 넣어 보았다. 아무리 해도 2.22% 이하로 내려가지 않아서 고민하다가 오늘 수업은 끝났다.
출결방에서 오늘을 마무리하면서 사람들이 질문하는 것을 듣다 보니 궁금증이 생겼다. 노드에서는 데이터셋을 생성하면서 corpus텐서를 tf.data.Dataset 객체로 변환시켰는데, 프로젝트에서는 이 부분을 사용하지 않는 것이다. 내가 잘못한 것인 걸까? 그동안 했던 것이 다 쓸모없는 건가? 별생각이 다 들었다. 그럼에도 dataset 객체로 학습을 시키면 안 돌아간다. 아, 정말 어떻게 해야 하는 거지? 대체 뭐가 뭔지 잘 모르겠다.
게다가 사람들은 검증 데이터를 나누는 부분에서 노드에서 말한 대로 사이즈를 줄인 것 같았다. 나는 어떻게 하는지 감도 잘 안 잡힌다. 이 부분은 아마도 포기해야 할 것 같다.
우선 내 방식대로 하고, 사람들이 어떻게 하는지 두고 보려고 한다. 내일 기회가 되면 데이터셋 객체에 대한 부분은 질문해 봐야겠다.
