어제 프로젝트7을 하다가 잘 안 풀려서 블로그에 영어 관련 글을 썼다. 알려주신 것을 썼는데, 어디서 문제가 생겼는지 몇 시간째 자꾸 에러 메시지가 떠서 잠시 내버려 두기로 했던 것이 새벽까지 글을 쓰게 되었다.
2개의 글을 쓰면서 앞으로 내가 어느 쪽으로 가야 할 지 감이 잡혔다. 원래도 자연어 처리쪽으로 마음을 먹었지만, 자연어 처리가 가야할 길이라는 사인도 계속 있었다는 걸 깨달았다. 영어 교육을 전공한 것도, 뜬금없는 corpus 수업을 듣게 된 것도, 라이팅을 좋아하는 것도 자연어 처리를 하기 위한 누군가의 큰 그림이 아니었을까? 하는 생각이 든다. 너무 어려워서 잘 할 수 있을지 모르겠지만 최선을 다해봐야겠다.
덧: 2개의 글을 올린 후, 프로젝트7에서 막힌 부분은 어쩌다보니 해결했다.
Node
오늘의 노드의 주제는 데이터 전처리였다. 키워드는 결측치, 중복된 데이터, 이상치, 정규화, 원-핫 인코딩, 구간화(Binning).
이번 노드는 통계 시간에 이미 배웠던 것들이라 아주 낯설지는 않았다. 코드도 R과 비슷한 것들이 많아서 이해하는데 어렵지 않았다. 물론 혼자서 해보라고 하면 못 하겠지만.
프로젝트를 하면서 데이터 전처리가 중요하다는 것을 절실히 느낀다. 통계 시간에도 그런 이야기를 들었다. 데이터를 모으고 처리하는 것이 가장 어렵다는. 특히 좋은 데이터를 모으는 것은 데이터 과학자나 통계학자들의 최대 관심사가 아닌가 싶다. 그래서인지 요즘 핫한 '마이데이터' 사업에 일희일비하는 모습이 공감된다. (참고: 네이버와 카카오가 뛰어든 ‘마이데이터 사업’ 완벽정리)
올 초에는 앞으로 어떻게 데이터가 수집되고 사용돼야 하는지에 대한 가이드라인을 제시한 데이터 3법이 발표되었다. 앞으로 데이터를 어떻게 수집하는지, 그리고 좋은 데이터를 얼마나 가지고 있는지가 기업의 생존을 좌지우지할지도 모른다.(이미 그런 것 같다.) 채팅봇인 이루다 논란에서처럼 동의 없이 개인정보가 노된 경우 그동안 개발한 기술은 물론 스타트업의 생존 여부에도 영향이 미칠 것이다. 또한 어떤 데이터를 모으고 어떻게 처리하느냐에 따라 마케팅이나 사업 방향도 달라지고 있다.
하지만 말처럼 데이터 수집과 전처리가 쉬운 것은 아니다. 프로젝트를 하면서 느꼈지만, 데이터를 잘 수집하고, 잘 가공하는 것에 정말 많은 시간이 걸린다. 첫 프로젝트인 가위바위보 분류기에서 그 사실을 절실히 깨달았다. 데이터가 잘못되어있기도 했고(바위 폴더에 가위가 들어가 있는 파일이 있었다.) 데이터를 잘못 저장해 일부 데이터가 사라지기도 해서 처음부터 다시 데이터를 수집하는 불상사가 있었다. 그 당시를 생각하면 지금도 아찔하다.
몇 주 전 본 유튜브 영상에서 어떤 데이터 분석가분은 매일 데이터를 모은다고 하셨다. 매일의 날씨와 그날 입은 옷에 대한 데이터를 저장하고 분석하여 매일 입을 옷을 정한다고 한다. 어떤 분은 매일 점심 식사 식단을 모으신다고도 했다. 나도 그분들처럼 나만의 데이터를 모으면 어떨까 생각한다.
며칠 전부터 나의 입실과 퇴실 시간을 모으고 있다. 데이터를 모아 무엇을 할 것은 아니고, 지난주 금요일 퇴실 처리를 하지 않아 결석 처리가 된 후 트라우마가 생겨서 입실, 퇴실 시간을 적어놓기로 했다. 이런 식으로 모으는 데이터도 언젠가는 쓸 데가 있지 않을까?
오전
오전 중에 조원 중 한 명이 L1 norm에 대해 질문을 하셔서 그 문제로 한동안 이야기를 나누었다. 나는 조용히 설명을 들으면서 이해가 안 되는 부분을 찾아보고 다시 질문했다. 질문의 내용은 'L1 Loss가 0인 점에서 미분이 되지 않는다'의 의미였다. 이게 무슨 말인가 했더니 좌표의 하나가 0이면 미분이 되지 않는다는 뜻이었다.
끊긴 점이나 뾰족한 점에서는 좌측 기울기와 우측 기울기가 다르기 때문에 미분할 수 없다. L1 distance 그래프의 (a, 0)과 (0, a)는 뾰족한 점이므로 미분을 할 수 없다. 이걸 'L1 Loss가 0인 점에서 미분이 되지 않는다'고 설명한 것이었다. 아, 불친절한 설명이여.
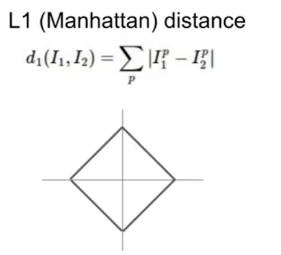
그 질문을 계기로 L1 distance가 sparse coding에 적합하다는 것을 알아냈다. sparse coding의 뜻은 위키피디아에 "Sparse coding is a representation learning method which aims at finding a sparse representation of the input data (also known as sparse coding) in the form of a linear combination of basic elements as well as those basic elements themselves. These elements are called atoms and they compose a dictionary."라고 쓰여 있다. 즉 '기본 원소들의 선형 조합으로 입력 데이터의 sparse한 표현을 찾기 위한 표현 학습 방법'이라고 해석할 수 있다. 잘 이해했는지는 모르겠지만 가중치를 최대한 0으로 많이 만들어서 새로운 데이터의 라벨을 예측한다고 한다. 왜곡된 데이터일 경우, 다른 방법보다 좋은 성과를 낸다고도 한다. (자세한 내용은 스파스 사전 학습을 참조.)
이런 것들을 찾아보고 생각하느라 노드는 시간 안에 다 끝내지 못해서 오후 글쓰기 시간까지 공부해야 했다.
글쓰기 시간
지금은 글쓰기 시간이다. 잠시 조원들과 퍼실님과 이야기를 나누다가 글을 쓰기 시작했다. 원래는 일기를 빨리 쓰고 CS231n을 정리하려고 했는데, 생각보다 일기를 쓰는 시간이 길어졌다. 얼른 마무리하고 나머지 시간에는 강의 정리를 해야겠다.
5주 차 후기
지난주에 너무 힘들었는데, 이번 주에는 우수 프로젝트 선정자가 되어서인지 기운을 차릴 수 있었다. 그동안 했던 고생들이 보상받는 느낌이랄까? 조원들과도 친해졌다. 처음에는 정말 어색했는데, 1달이 지나고 나니 익숙해져서 잡담도 예전보다 많이 하고, 질문할 때도 덜 민망하다.
노드와 프로젝트도 익숙해졌다. 노드는 가끔 시간 안에 끝내지 못할 때가 있고, 프로젝트에서는 꼭 한 두 군데서 막히는 부분이 있어서 힘들지만 아무것도 모르던 1달 전보다는 빨리 끝낼 수 있고, 코드의 내용도 살펴볼 여유가 생겼다.
CS231n 강의도 이제는 익숙해졌다. 아는 용어들이 나오니까 이전처럼 힘들지는 않다. 의자가 바뀐 것도 그중 한 이유이다. 편안한 의자는 필수인 것 같다.
그러나 문제는 코딩마스터이다. 알고리즘 문제 풀이가 제일 어렵다. 문제조차 이해가 잘 안 되어서 오래 생각해야 하고, 문제를 푸는 것도 만만치 않다. 풀었다고 생각했는데, 통과하지 못해 고생하기도 했다. 그러나 스터디까지 참가하기에는 체력이 안 따라줄 것 같다. 지금 하는 것도 허덕이기 때문에 스터디는 아직은 무리다. 그래서 Y님께서 스터디 시간에 한다고 하신 파이썬 300문제를 혼자서라도 풀기로 했다.
알고리즘 문제는 고등학교와 대학교 수학 시간에 문제를 푸는 것과 같은 기분이 든다. 문제조차 이해하지 못해 헤매는 기분? 아니면 토플 라이팅과 스피킹 문제를 푸는 느낌? 뭐부터 시작해야 할지 감이 안 잡히는 막막한 기분이다. 익숙해지면 나아질 거라는 말만 되새긴다. 파이썬 300문제는 반드시 다 풀고 만다!
그래도 매일 성장하는 것을 느낀다. 예전에는 이해되지 않았던 빅데이터나 AI 관련 기사나 동영상이 이해될 때도, 노드와 프로젝트를 할 때도. 앞으로의 5개월도 성장하는 시간이 되었으면 한다.
