- 이 포스팅은 AIFFEL 과정에서 배운 내용과 '딥러닝을 이용한 자연어 처리 입문'을 참고하여 정리하였습니다.
번역기와 챗봇
번역기를 만들 때 사용하는 대표적인 모델은 '인코더와 디코더'의 아키텍처로 구성되어 있다. 인코더에 입력 문장이 들어가고, 디코더는 이에 상응하는 출력 문장을 생성한다. 즉 입력문장과 출력 문장 2가지 병렬 구조로 구성된 데이터셋을 훈련하여 새로운 문장이 들어왔을 때 그에 상응하는 출력문장을 생성할 수 있다. 이와 같은 구조를 이용하여 챗봇도 만들 수 있다.
훈련 데이터셋의 구성(질문-답변)
- 입력문장: '1지망 학교 떨어졌어'
- 출력문장: '위로해 드립니다.'
병렬적으로 구성된 데이터셋이다. 질문에 대해서 대답을 하도록 구성된 데이터셋을 인코더와 디코더 구조로 학습하여 주어진 질문에 답할 수 있는 챗봇을 만들 수 있다.
트랜스포머의 주요 하이퍼파라미터
- : 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기, 임베딩 벡터의 차원. 이 차원은 여러 층의 인코더와 디코더로 값을 보낼 때도 계속 유지된다. 논문에서는 512이다.
- num_layers: 트랜스포머에서의 인코더와 디코더의 층의 개수, 논문에서는 6개의 층으로 구성되었다.
- num_heads: 병렬 어텐션의 개수, 논문에서는 8개이다.
- : 트랜스포머 내부에 존재하는 피드 포워드 신경망의 은닉층의 크기이며, 논문에서는 2048이다.
트랜스포머의 인코더와 디코더
트랜스포머 역시 인코더와 디코더의 구성을 가지기 때문에 입력 문장을 넣으면 출력 문장을 생성한다. 그러나 기존의 RNN을 사용한 모델과 달리 트랜스포머는 RNN을 없애고 Attention 기법만을 사용하고, 인코더와 디코더를 여러 개 쌓은 구조로 되어 있다.
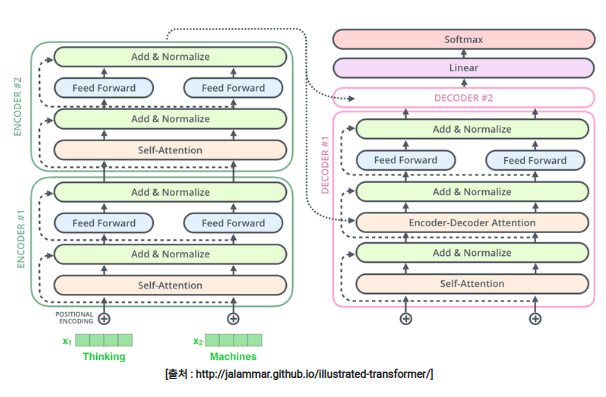
Positional Encoding
아래의 그림은 트랜스포머의 인코더와 디코더 구조를 간단히 그림으로 표현한 것이다. 그림의 Encoders와 Decoders는 6개의 인코더와 디코더를 의미한다. 먼저 단어를 원-핫 벡터로 만든 후, 차원을 줄이기 위해서 embedding layer를 지나간다. 여기까지는 RNN과 같은 방식이다. 그러나 인코더와 디코더에 단어 벡터를 넣기 전 Positional Encoding이라는 단계를 하나 더 거친다.
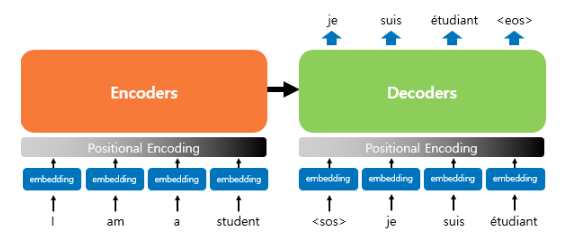
순차적으로 단어를 집어 넣는 RNN과 달리 트랜스포머는 한꺼번에 입력 문장을 넣기 때문에 단어의 위치 정보(어순)를 알려주기 위해서 Positional Encoding을 해주어야만 한다. 아래의 그림과 같이 positional encoding과 embedding vector를 각 엘레먼트 별로(element-wise) 더해준다.
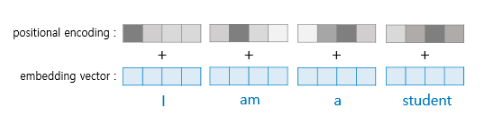
트랜스포머는 사인함수와 코사인함수의 값을 임베딩 벡터에 더해주어 단어의 순서 정보를 더해준다. 임베딩 벡터의 각 차원의 인덱스가 짝수인 경우에는 사인함수의 값을, 홀수인 경우에는 코사인 함수의 값을 사용한다.

-
: 임베딩 벡터의 차원
-
pos: 입력 문장에서의 임베딩 벡터의 위치
-
i: 임베딩 벡터 내의 차원의 인덱스
Q. 최대 문장의 길이가 50, 워드 임베딩 차원을 512로 하는 포지셔널 인코딩 행렬의 모습은 어떻게 되는가? 또한 포지셔널 인코딩 레이어를 사용하여 표현해 보아라.
50x512, positional_encoding(50, 512)
Attention
트랜스포머에서 가장 핵심적인 개념은 Attention이며, 어텐션은 단어들 간 유사도를 구하는 매커니즘이다. (그래서 트랜스포머를 소개한 논문의 제목도 'Attention is All you need'이다.) 그리고 Attention에서 핵심적인 것은 Query, Key, Value이다. 우선 쿼리, 키, 밸류는 입력 문장의 모든 단어들의 벡터라는 사실을 잊지 말아야 한다.
쿼리는 말 그대로 질문을 하는 것이다. 즉 알아보고자 하는 단어가 쿼리이고 문장의 모든 단어가 키이다. 알고자 하는 단어(쿼리)가 문장의 모든 단어(키들)와 얼마만큼의 유사도를 가지고 있는지를 구한다. 여기서 구한 쿼리와 키와의 유사도를 키와 매핑(mapping)되어 있는 값(밸류)에 반영한다. 유사도가 반영된 값을 모두 하나로 더한 것이 어텐션 값(Attention Value)이다.

트랜스포머에서는 아래와 같은 3가지의 어텐션을 사용한다.
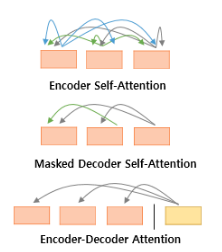
인코더 셀프 어텐션은 인코더에서, 디코더 셀프 어텐션과 인코더-디코더 어텐션은 디코더에서 이루어진다.
- 인코더 셀프 어텐션: 인코더의 입력으로 들어간 문장 내 단어들의 유사도를 구한다.
- 디코더 셀프 어텐션: 단어를 1개씩 생성하는 디코더가 이미 생성된 앞 단어와의 유사도를 구한다. (뒤의 단어와의 유사도를 알지 못하도록 마스크를 씌워준다.)
- 인코더-디코더 어텐션: 인코더에 입력된 단어들과 디코더의 단어 간의 유사도를 구한다.
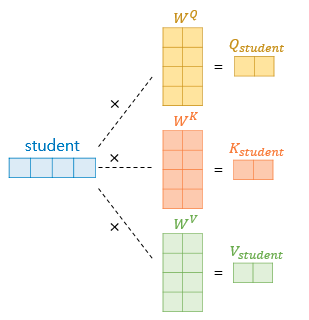
Q, K, V 구하기
Q, K, V는 아래의 그림과 같이 각 단어 벡터에 가중치 행렬을 곱해 구할 수 있다. 아래의 그림은 간략하게 그렸지만 논문에서는 차원을 가진 각 단어 벡터들이 64차원의 Q, K, V 벡터로 변환되었다. 여기서 64는 을 num_heads=8로 나눈 것이다. (num_heads는 뒤에서 나올 Multi Head Attention에서 나올 하이퍼파라미터이다.)
- Q, K, V의 차원: / num_heads
- 가중치 행렬의 크기: x /num_heads
(가중치 행렬은 훈련 과정 중 학습된다.)
Scaled Dot Product Attention
어텐션 값을 구하는 수식은 아래와 같다.
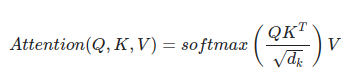
- Q, K, V는 단어 벡터를 행으로 하는 문장 행렬이다.
- 벡터의 내적(dot product)은 벡터의 유사도를 의미한다.
- 값의 크기를 조절하는 스케일링을 한다.
수식을 그림으로 표현하면 아래와 같다.
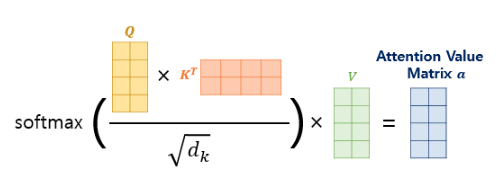
각 단어 벡터의 유사도가 모두 기록된 유사도 행렬()로부터 나온 유사도 값을 스케일링해주려고 행렬 전체를 특정 값()으로 나눠준다. (논문에서 /num_heads=64이므로 는 8이다.) 그 후 소프트맥스 함수를 사용하여 어텐션 분포를 구하고, 각 어텐션 분포에서 나온 값에 문장 행렬 V를 곱하면 어텐션 값이 나온다. (노드에서는 정규화를 해주려고 소프트맥스 함수를 사용한다고 나온다.)
위의 수식은 내적을 통해 단어 벡터 같 유사도를 구한 후 특정 값을 분모로 나눠주는 방식으로 Q와 K의 유사도를 구하였다고 해서 스케일드 닷 프로덕트 어텐션이라고 한다.
- 행렬의 크기
- : Q, K 벡터의 크기 -> Q, K 행렬의 크기: (seq_len, ), V 행렬의 크기: (seq_len, )
- 의 크기: (), 의 크기: ()(문장행렬과 Q, K, V행렬의 크기로부터 추정)
- /num_heads이므로 어텐션 값 행렬 a의 크기는 (seq_len, )이다.
Multi-Head Attention
어텐션을 병렬로 수행하는 것을 멀티 헤드 어텐션이라고 한다. 트랜스포머는 입력된 문장 행렬을 num_heads의 수만큼 쪼개 어텐션을 수행하고 어텐션의 값 행렬 num_heads개를 하나로 연결(concatenate)한다. 연결된 어텐션 헤드 행렬의 크기는 (seq_len, )이다.
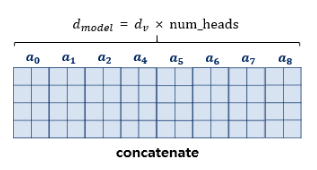
병렬로 수행되는 어텐션은 서로 다른 시각에서의 셀프 어텐션 결과를 얻기 때문에 각각 다른 관점에서의 정보를 얻을 수 있어서 효과가 더 좋다.
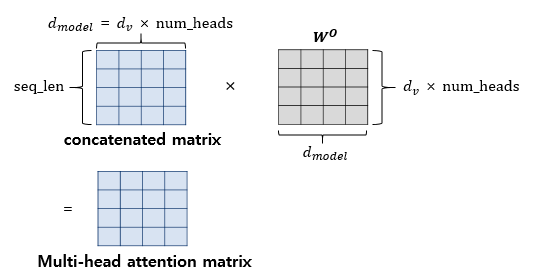
어텐션 헤드를 모두 연결한 행렬에 가중치 행렬 를 곱해 나온 결과 행렬이 멀티 헤드 어텐션의 결과물이며, 이 행렬의 크기는 (seq_len, )이다.
여기서 가중치 행렬을 곱하는 것을 구현 상에서는 입력을 밀집층(Dense layer)를 지나게 하여 구현한다.
Masking
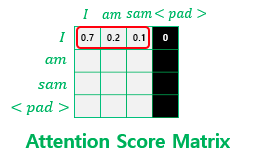
1. Padding Masking
패딩토큰을 이용한 마스킹을 패딩 마스킹이라고 한다. 자연어 처리에서 정해준 길이보다 짧은 문장에 숫자 0을 채워서 문장의 길이를 맞춰주는 전처리 작업을 한다. 여기서 숫자 0은 실제 의미가 있는 단어가 아니므로 어텐션 등과 같은 연산에서 제외하기 위해 패딩 마스킹을 한다. 아래는 패딩 마스킹을 구현하는 함수이다.
그러나 scaled_dot_product_attention() 함수에서 logits += (mask * -1e9)이 패딩 마스킹의 역할을 한다. 즉 어텐션 스코어 행렬의 마스킹 위치에 매우 작은 음수값을 넣어준다. 소프트맥스 함수를 지나면 해당 위치의 값은 0에 가까운 값이 되어 패딩 토큰이 단어 간 유사도를 구하는데 반영되지 않는다.
2. Look-ahead masking(다음 단어 가리기)
룩어헤드 마스킹은 디코더의 셀프 어텐션에서 사용된다. 인코더와 달리 디코더에서는 뒤의 단어를 미리 알게 되면 다음 단어를 예측하는 훈련을 할 수 없기 때문에 자신보다 다음에 나올 단어를 참고하지 않도록 가려준다. 즉 쿼리 단어 뒤에 나오는 키 단어들에 대해서 마스킹하여 이전 단어들과의 유사도만 구하게 한다. 아래의 그림에서 빨간색 부분이 마스킹한 부분이다.
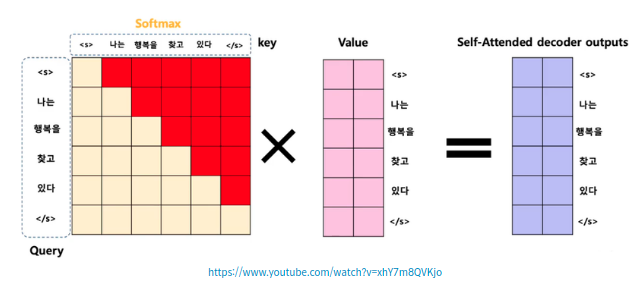
룩어헤드 마스크에는 패딩 마스크를 포함하도록 구현한다.
Position-wise FFNN 포지션-와이즈 피드 포워드 신경망
포지션 와이즈 FFNN(Fully-connected FFNN)의 수식과 식을 그림으로 표현한 것은 아래와 같다.

- x: 멀티 헤드 어텐션의 결과로 나온 (seq_len, )의 크기를 가지는 행렬
- 가중치 행렬 : ()의 크기를 가진다.
- 가중치 행렬 : ()의 크기를 가진다. (는 은닉층의 크기)
매개변수 은 하나의 인코더 층에서는 동일하나 인코더 층마다는 다른 값을 가진다.
Residual connection 잔차 연결, Layer Normalization 층 정규화
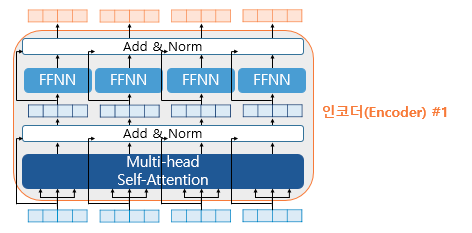
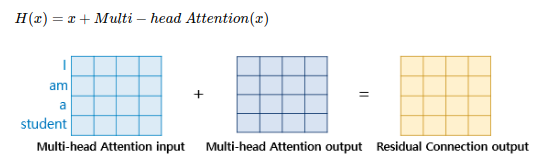
1. 잔차 연결

함수 는 트랜스포머에서의 서브층을 의미한다. 잔차연결은 서브층의 입력과 출력을 더하는 것이다. 만약 서브층이 멀티 헤드 어텐션이면 잔차 연결 연산은 아래와 같다.
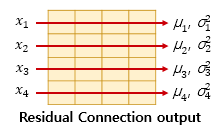
2. 층 정규화
층 정규화는 텐서의 마지막 차원 에 대해 평균과 분산을 구한 값으로 정규화하여 학습을 돕는다. 텐서의 마지막 차원은 차원이며, 아래 그림은 차원의 방향을 화살표로 표현하였다. 출력의 크기는 (seq_len, )이다. 화살표 방향으로 평균과 분산을 구하고, 정규화를 해준다. 층 정규화를 한 후에 벡터 는 라는 벡터로 정규화된다.
층 정규화는 2가지 과정으로 이루어진다.
-
평균과 분산을 통해 벡터 를 정규화한다.
(여기서 은 분모가 0이 되는 것을 방지하는 값) -
감마와 베타라는 벡터를 준비해 아래와 같이 정규화를 해준다. (감마와 베타의 초기값은 각각 1과 0이다.)
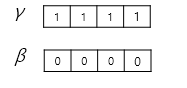
(는 학습 가능한 파라미터)
디코더에서의 어텐션
디코더에는 두 개의 멀티 헤드 어텐션이 들어간다. 첫번째 서브층은 mask의 인자값으로 look_ahead_mask가 들어가고, 두번째 서브층은 mask의 인자값으로 padding_mask가 들어간다.
트랜스포머 구현
인코더와 디코더를 각각 구현하고, 인코더와 디코더를 각각 원하는 개수만큼 쌓아준다. 인코더를 먼저 쌓고 마지막 인코더에서의 출력값을 디코더로 전달해준다. 디코더를 쌓은 후 마지막에 다중 클래스 분류 문제를 풀 수 있도록 vocab_size만큼의 뉴련을 가지는 신경망을 추가한다.
트랜스포머 하이퍼파라미터
- 단어 집합의 크기 vocab_size
- 룩업 테이블을 수행할 임베딩 테이블과 포지셔널 인코딩의 행렬의 행의 크기 num_layers
- 포지션 와이즈 피드 포워드 신경망의 은닉층
- 인코더와 디코더의 입/출력 차원
- 멀티-헤드 어텐션의 헤드 수 num_heads
손실함수
다중 클래스 분류 문제이므로 크로스 엔트로피 함수를 손실함수로 사용한다.
학습률 learning rate
학습 경과에 따라 학습률이 변하도록 설계하였다. 아래는 공식이며 warmup_step은 4,000이다.
