[AIFFEL 대전 1기] 학습일지
1.0.2 환경설정 (아나콘다, NVIDIA GPU 드라이버 설치)
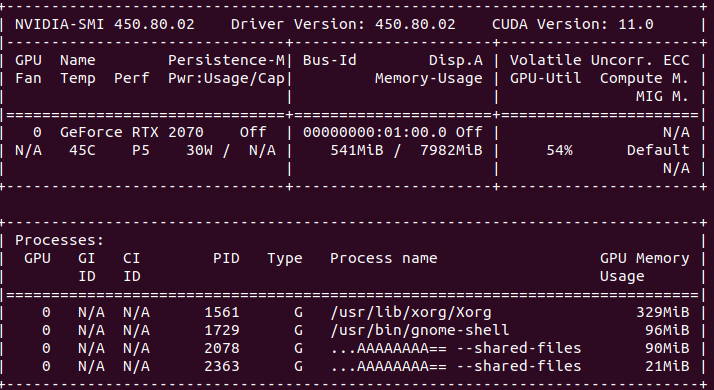
터미널을 연다(Ctrl+Alt+T). 다음의 명령어를 순서대로 친다. $ cd ~/Downloads $ wget https://repo.anaconda.com/archive/Anaconda3-2020.02-Linux-x86_64.sh $ bash Anacond
2.1.1 운영체제, 터미널, 패키지 관리
운영체제(OS)란 'Operating System'의 약자로 컴퓨터 하드웨어를 모르는 사람들도 효율적으로 사용하도록 관리해주고 데이터 처리를 해주는 시스템 소프트웨어이다. 운영체제의 종류에는 Windows, MacOS, Linux 등이 있다.
3.1.2 가상환경

가상환경(virtual environment)이란 프로젝트별 독립된 공간을 만들어주는 기능이다. 가상환경이 필요한 이유는 프로젝트를 여러 개 개발할 때 패키지 버전의 문제가 발생하기 때문이다.
4.[풀잎스쿨] CS231n L2 Image Classification
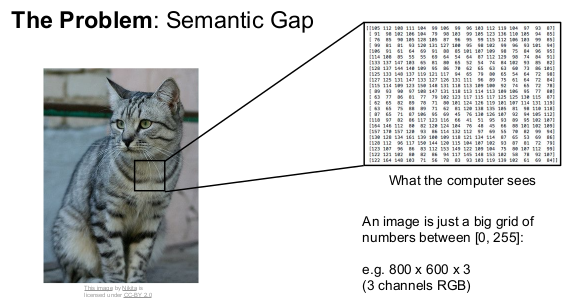
Linear
5.2.1 협업 툴
협업은 어디서든 중요하지만 개발자들에게는 반드시 필요한 능력이다. 그 이유는 협업을 통해 해결해야 하는 문제가 많기 때문이다.
6.2.2 Git, GitHub
GitHub은 개발자들이 서로 코드를 공유하고, 협업으로 개발을 진행할 때 소스 코드 버전들을 효과적으로 관리하기 위한 온라인 호스팅 사이트이다.
7.2.3 Jupyter Notebook

Jupyter Notebook Jupyter Notebook 은 데이터 분석을 편리하게 할 수 있게 하는 오픈소스 웹 어플리케이션 이다. Jupyter Jupyter Notebook은 "문서"작업과 "코드" 작업을 동시에 진행할 수 있으며, 셀 단위로 코드를 실행
8.2.4 마크다운(Markdown)

마크다운은 '코드만으로 문서 작업을 할 수 있도록 개발된 언어'이다. 코드를 치듯 문서를 작성한 후 md 확장자를 가진 마크다운 파일을 렌더링하면 큰 문자, 볼드체, 링크 등을 표현해 준다. -출처: WIKIMEDIA COMMONS 주피터 노트북에서 셀을 '마크다운
9.[풀잎스쿨] CS231n 3강(1) Loss Functions
스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition 본 포스팅은 CS231n 3강의 내용을 정리한 것이다.
10.[풀잎스쿨] CS231n 3강 (2) Optimization & Image Features

본 포스팅은 스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition CS231n 3강의 내용을 정리한 것이다.
11.[풀잎스쿨] CS231n 4강 (1) Backpropagation
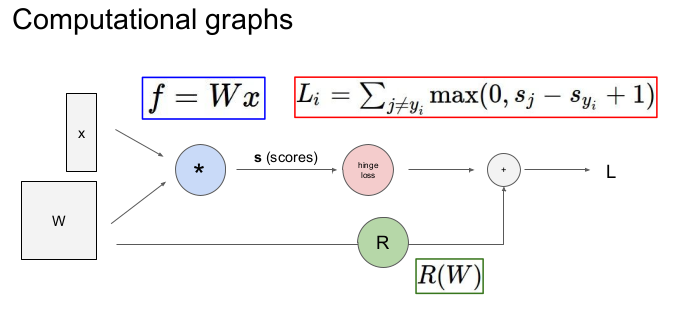
스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition 본 포스팅은 CS231n 3강의 내용을 정리한 것이다.
12.'<쫄지말자 딥러닝> 데이터의 관점에서 바라보는 인공지능' 후기
이 후기는 필기를 하지 못해 기억에 의존한 것으로 부정확한 용어나 설명이 포함될 수도 있습니다. 최대한 기억을 살리고, 부족한 정보는 검색을 통해 채우겠습니다. 1월 20일 저녁 7시 반부터 2시간 동안 김승일 연구소장님께서 인공지능에 대한 벙개 강연을 하셨다. 주제
13.텐서플로우가 GPU를 사용하지 못할 때 해결책
CNN 모델을 학습시킬 때(batch size=32, epochs=10) 학습 시간은 약 30분이 걸린다고 하였다. 그런데 나는 한 epoch당 25분이 걸리는 것이다.
14.'AIFFEL 선배팅 그 첫번째 이야기!' 후기
오늘은 AIFFEL 강남 1기 선배님께서 특강을 해 주셨다. 참여 대상은 'AIFFEL 학습의 꿀팁이 필요하신 분, AIFFEL 졸업 후의 진로에 대한 고민을 나누고 싶으신 분'이었다.
15.Git/GitHub의 add/commit과 branch
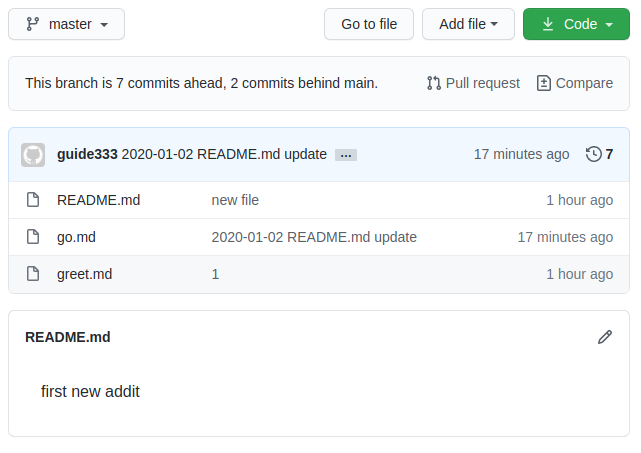
add/commit과 push 명령어를 실행했을 때 터미널에서는 분명히 잘 수행되었다고 나오지만 GitHub에서 반영이 안 되는 것처럼 보였다. 여러 번 시도해도 안 되어서 나만 이상한가 싶었는데, 알고보니 안 된 이유가 있었다.
16.Tuple의 사용법
List, Tuple, Dictionary를 비교하시오. 위의 문제는 AIFFEL대전 면접 문제 중 하나였다. 면접은 30분 동안 7명 정도의 지원자와 교장 선생님, 대전 담임 선생님, 그리고 한 분(말이 없으셔서 기억이 안 나네요. 죄송합니다.)이 함께 토론을 나누
17.[풀잎스쿨] CS231n 4강 (2) Neural Networks
스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition 본 포스팅은 CS231n 3강의 내용을 정리한 것이다.
18.[풀잎스쿨] CS231n 5강 Convolutional Neural Networks
스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition 본 포스팅은 CS231n의 내용을 정리한 것이다. 이곳에 출처가 따로 언급되지 않은 이미지들은 스탠퍼드 대학에서 제공하는 강의 슬라이드에서
19.[풀잎스쿨] CS231n 6강 Training Neural Networks Part 1 (1)
스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition 본 포스팅은 CS231n의 내용을 정리한 것이다.
20.[풀잎스쿨] CS231n 6강 Training Neural Networks Part 1 (2)
스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition 본 포스팅은 CS231n의 내용을 정리한 것이다.
21.[풀잎스쿨] CS231n 7강 Training Neural Networks Part 2 (1)

스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition본 포스팅은 CS231n의 내용을 정리한 것이다.
22.[풀잎스쿨] CS231n 7강 Training Neural Networks Part 2 (2)
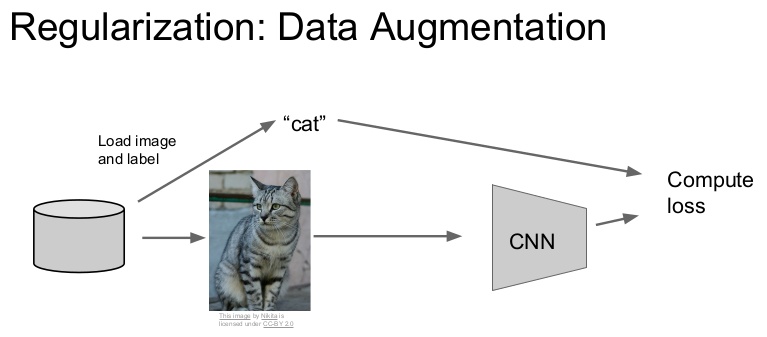
스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition 본 포스팅은 CS231n의 내용을 정리한 것이다. 이곳에 출처가 따로 언급되지 않은 이미지들은 스탠퍼드 대학에서 제공하는 강의 슬라이드에서 가지
23.[풀잎스쿨] CS231n 9강 CNN Architectures (1)
스탠퍼드 대학의 CS231n: Convolutional Neural Networks for Visual Recognition 본 포스팅은 CS231n의 내용을 정리한 것이다.
24.[E-15] Transformer
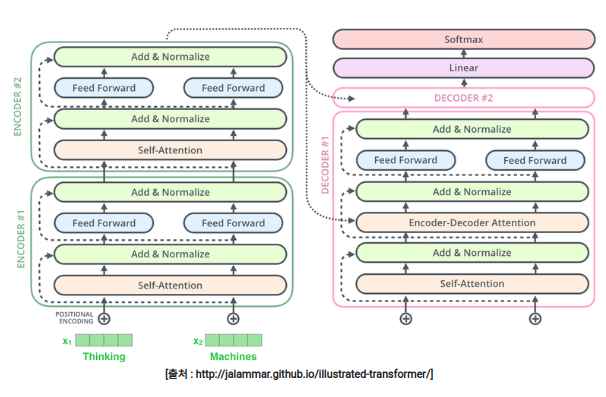
이 포스팅은 AIFFEL 과정에서 배운 내용과 '딥러닝을 이용한 자연어 처리 입문'을 참고하여 정리하였습니다. 번역기를 만들 때 사용하는 대표적인 모델은 '인코더와 디코더'의 아키텍처로 구성되어 있다.
25.tensorflow 버전 호환 문제(GPU 인식)
BERT에 대한 프로젝트를 하다가 모델 학습이 오래 걸리는 문제가 있었다.nvidia-smi위의 코드를 터미널에 쳐서 확인해 보았더니 GPU를 전혀 사용하지 못하고 있었다.
26.BPE, SentencePiece 간단 정리
Neural machine translation(NMT)은 고정된 크기의 사전만을 사용해 번역하지만 실제 번역은 새로운 단어 등도 번역해야 하는 an open vocabulary 문제이다.
27.[밑시딥 2권] 2.4 통계 기반 기법 개선하기
2.3에서는 단어의 동시발생 행렬을 만들어 단어를 벡터로 표현하였다. 그러나 동시발생 행렬에는 개선할 점이 있다.동시발생 행렬의 원소는 두 단어가 발생한 횟수를 나타내지만 고빈도 단어 측면에서 보면 좋은 특징이 아니다.
28.[GD1] 유사도 연관 알고리즘 정리
단어간 벡터 연산: 고양이 + 애교 = 강아지, 한국 - 서울 + 도쿄 = 일본이런 연산을 할 수 있는 이유는 각 단어 벡터가 단어간 유사도를 반영한 값을 가지고 있기 때문이다.
29.고유값과 고유벡터
머신러닝 - 19. 고유값(eigenvalue), 고유벡터(eigenvector), 고유값 분해(eigen decomposition)를 정리한 내용정방행렬 A를 선형 변환으로 봤을 때, 선형변환 A에 의한 변환 결과가 자기 자신의 상수배가 되는 0이 아닌 벡터를 고유
30.LDA 정리
31.SVD(특이값 분해)
특이값 분해
32.[GD-L2]단어 빈도 이용한 벡터화(BoW, DTM, TF-IDF)
텍스트를 숫자 벡터로 변환(전처리 과정 중 하나)벡터화의 방법 (1) 통계와 머신 러닝을 활용한 방법(오늘 배울 것)(2) 인공 신경망을 활용하는 방법벡터화 (Vectorization): 텍스트를 숫자 벡터로 변환(전처리 과정 중 하나)
33.[GD-L2]LSA, LDA, 비지도학습 토크나이저
LSA DTM과 TF-IDF 행렬 같이 Bag of Words를 기반으로 한 표현 방법은 특정 단어가 포함된 문서를 찾아내는 것은 빠르게 할 수 있으나 단어의 의미를 벡터로 표현하지 못한다.
34.[GD-P2] 나이브 베이즈 분류, F1-score
\[머신러닝] 나이브 베이즈(Naive Bayes) 분류 (2/2) - 베이즈 정리 (Bayes' Theorem) 쉽게 이해하기 정리조건 확률은 2가지 종류 존재두 사건이 독립적일 때(두 사건이 서로 영향을 끼치지 않음)$P(A \\cap B) = P(A) \* P(B
35.[GD-P2] 머신러닝 모델 정리
많은 샘플이 특정 클래스에 치우져 있을 경우에 사용. 가중치를 부여하여 나이브 베이즈 분류기를 보완했기 때문에 나이브 베이즈 분류기보다 성능이 좋다. 참고: 나이브 베이즈 분류기는 각 데이터가 조건부로 독립적이라는 가정을 한다.
36.피드 포워드 신경망 언어 모델(NNLM)
위키독스: 피드 포워드 신경망 언어 모델(NNLM)를 정리한 내용입니다.기존의 통계적 언어모델은 한 번도 보지 못한 데이터에 대한 확률을 0으로 부여하는 등 언어를 정확히 모델링할 수 없다는 희소 문제가 있었다.
37.Sequence-to-Sequence
위키독스: 시퀀스-투-시퀀스를 정리한 내용입니다. 시퀀스-투-시퀀스(Sequence-to-Sequence)는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에 사용되는 모델이다.
38.GRU 정리
RNN, LSTM, GRU의 구조를 비교해 보면 아래와 같다. GRU GRU는 LSTM의 장기 의존성 문제를 해결하면서 복잡한 LSTM의 구
39.Attention 정리
Attention Mechanism RNN에 기반한 seq2seq 모델에는 두 가지 문제점이 있다. 고정된 크기의 벡터(콘텍스트 벡터)에 모든 정보를 압축하기 때문에 정보 손실이 발생한다. (오래된 정보부터 손실이 일어난다.) RNN의 특성 때문에 기울기 소실 문제가
40.고유값과 고유벡터의 의미
n차 정사각형 행렬 을 A라고 할 때, $\\mathbf 0$이 아닌 벡터 $\\mathbf x \\in R^n$가 적당한 스칼라 $\\lambda$에 대해 아래의 식을 만족하면 $\\lambda$를 A의 고유값(eigenvalue)라 하고,
41.Pretrained BERT
10M 정도의 작은 파라미터 사이즈의 BERT 모델을 만들어, 수백MB 수준의 코퍼스 기반으로 pretrain을 진행한다. Tokenizer 준비데이터 전처리 (1) MASK 생성데이터 전처리 (2) NSP pair 생성데이터 전처리
42.logit, 확률, sigmoid, softmax
인공신경망에서 사용되었던 activation function(활성화 함수), hidden 노드 바로 뒤에 부착한다.$$sigmoid = \\frac {1}{1+e^{-x}} = \\frac {e^x}{e^x + 1}$$ 출처: 위키피디아인공신경망이 결과로 내놓은 K개의