LSA
DTM과 TF-IDF 행렬 같이 Bag of Words를 기반으로 한 표현 방법은 특정 단어가 포함된 문서를 찾아내는 것은 빠르게 할 수 있으나 단어의 의미를 벡터로 표현하지 못한다. 특정 단어(단어의 의미)와 관련된 문서 집합(문서의 주제)을 찾거나 문서의 의미와 주제를 알고 싶다면 LSA를 사용할 수 있다.
LSA(Latent Semantic Analysis, 잠재 의미 분석)은 전체 코퍼스에서 문서 속 단어들 사이의 관계를 찾아내는 자연어 처리 정보 검색 기술 이다. LSA를 사용하면 단어와 단어 사이, 문서와 문서 사이, 단어와 문서 사이의 의미적 유사성 점수 를 찾아낼 수 있으며 bag of words 기반 방법보다 효과적이다.
LSA와 Truncated SVD
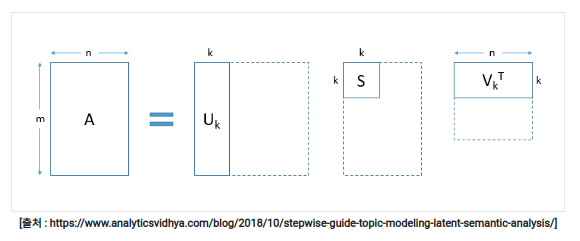
LSA는 DTM이나 TF-IDF 행렬 등에 Truncated SVD를 수행한다. 분해하여 얻은 행렬 3개()는 각각 '문서들과 관련된 의미들을 표현한 행렬', '각 의미의 중요도를 표현한 행렬', '단어들과 관련된 의미를 표현한 행렬' 이다.
그림설명(Truncated SVD, k: 하이퍼파라미터)
- m: 문서의 수, n: 단어의 수
- : m x k 의 크기의 행렬. 문서의 수 m의 크기는 줄어들지 않는다. 의 각 행은 각 문서를 표현하는 문서 벡터이다.
- : k x n의 크기를 가지는 행렬. 단어의 수 n은 줄어들지 않는다. 행렬의 각 열은 각 단어를 나타내는 m차원의 단어 벡터이다. 단어 벡터의 차원이 m(행렬 A)에서 k로 축소된다. (벡터의 차원을 저차원으로 축소하면서 잠재된 의미를 끌어내는 여러 방법은 '워드 임베딩'을 배울 때 자세히 배울 것)
DTM이나 TF-IDF 행렬에 Truncated SVD를 수행하고 얻은 행렬의 k열은 전체 코퍼스로부터 얻어낸 k개의 주요 주제 이다.
- 참고: DTM의 크기(shape)는 (문서의 수 × 단어 집합의 크기)
LSA의 장단점
- 장점: LSA는 쉽고 빠르게 구현이 가능하고 단어의 잠재적인 의미를 이끌어내 문서의 유사도 계산 등에서 좋은 성능을 보여준다.
- 단점: 새로운 정보에 대해 업데이트가 어렵다. (이미 계산된 LSA에 새로운 데이터를 추가하여 계산할 수 없음)
LDA(Latent Dirichlet Allocation)
LDA는 각 토픽의 단어 분포와 각 문서의 토픽 분포 를 추정한다.
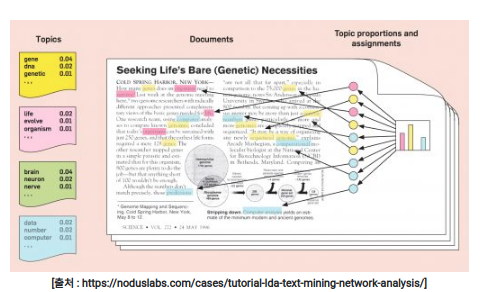
LDA는 각 토픽의 단어 분포, 즉 특정 토픽에 특정 단어가 나타날 확률을 추정한다. 위의 그림에서 "Topics"는 각 토픽에서 각 단어가 등장할 확률을 보여준다. 그림 중앙의 'Documents"에는 노란색, 분홍색, 하늘색의 3가지 토픽이 존재하며, 노란색이 가장 많다. 그림 오른쪽의 "Topic proportions and assignments"의 막대 그래프는 문서에 존재하는 토픽의 비율을 시각화한 그래프이다. 그래프에 따르면 이 문서는 노란색 토픽의 단어가 가장 많이 등장하므로 노란색 토픽을 가지고 있을 가능성이 높다. LDA는 단어의 분포로부터 해당 문서의 토픽 분포를 추정한다.
- 자세한 내용은 여기 참조(길어서 따로 분리)
비지도 학습 토크나이저
텍스트의 분포를 이용해 토큰화를 수행하는 비지도 학습 토크나이저 를 알아보자.
형태소 분석기의 필요성
- 한국어의 특성
한국어는 교착어이다. 교착어란 하나의 낱말(엄밀히 하나의 어절)이 하나의 어근(root)(혹은 어간(stem))과 각각 단일한 기능을 가지는 하나 이상의 접사(affix)의 결합으로 이루어진 언이이다.
낱말(어절) = 어근(어간) + 1개 이상의 접사
이런 특성 때문에 조사나 접사가 존재하고 띄어쓰기 단위 토큰화가 제대로 동작하지 않는다.
단어 미등록 문제(OOV)
기존의 형태소 분석기는 등록된 단어를 기준으로 형태소를 분류해 새롭게 만든 단어를 인식하기 어렵다는 특징이 있다.
텍스트 데이터에서 특정 문자 시퀀스가 함께 자주 등장하는 빈도가 높고, 앞뒤로 조사 또는 완전히 다른 단어가 계속 함께 등장하면 해당 문자 시퀀스를 형태소라고 판단하는 형태소 분석기가 바로 soynlp이다.
soynlp
soynlp는 품사 태깅, 형태소 분석 등을 지원하는 한국어 형태소 분석기이다. 비지도 학습 으로 형태소 분석을 한다는 특징이 있고, 데이터에 자주 등장하는 단어를 형태소로 분석한다. soynlp 형태소 분석기는 내부적으로 단어 점수표 로 동작하며, 이 점수는 응집 확률(cohesion probability) 와 브랜칭 엔트로피(branching entropy) 를 활용한다.
soynlp는 비지도학습 형태소 분석기이므로 학습 과정을 거친다. 따라서 전체 코퍼스로부터 응집 확률과 브랜칭 엔트로피 단어 점수표를 만드는 과정이 필요하다. WordExtractor.extract()를 통해서 전체 코퍼스에 대해 단어 점수표를 계산한다.
soynlp의 응집 확률(cohesion probability)
- 응집확률
내부 문자열(substring)이 얼마나 응집하여 자주 등장하는지를 판단하는 척도.
문자열을 문자 단위로 분리해 내부 문자열을 만드는 과정에서 왼쪽부터 순서대로 문자를 추가하면서 각 문자열이 주어졌을 때 그 다음 문자가 나올 확률 을 계산해 누적곱을 한 값. 이 값이 높을수록 전체 코퍼스에서 이 문자열 시퀀스가 하나의 단어로 등장할 가능성이 높다.

- 길이 7인 문자 시퀀스 '반포한강공원에'의 각 내부 문자열의 스코어를 계산하는 과정

soynlp의 브랜칭 엔트로피(branching entropy)
- 브랜칭 엔트로피
확률 분포의 엔트로피값 사용. 주어진 문자열에서 다음 문자가 등장할 수 있는 가능성을 판단하는 척도. 주어진 문자 시퀀스에서 다음 문자 예측을 위해 혼동되는 정도.
브랜칭 엔트로피의 값은 하나의 완성된 단어에 가까워질수록 문맥으로 인해 정확히 예측할 수 있으므로 점차 줄어든다. 그러나 완성된 단어를 집어넣으면 갑자기 값이 급증하는데, 그 이유는 완성된 단어 다음에 조사나 다른 단어와 같은 다양한 경우가 나올 수 있기 때문이다. 하나의 단어가 끝나면 그 경계 부분부터 브랜칭 엔트로피 값이 증가한다.
soynlp 패키지는 이렇게 계산한 점수를 사용해 두 가지 문자열 토큰화 방법을 제공한다.
soynlp의 LTokenizer
L 토크나이저(LTokenizer)를 사용해 띄어쓰기 단위로 잘 나뉜 문장 을 얻을 수 있다.
한국어는 띄어쓰기 단위로 나눈 어절 토큰은 주로 L 토큰 + R 토큰의 형식을 가지는 경우가 많다.
- '공원에' = '공원 + 에'
- '공부하는' = '공부 + 하는'
L 토크나이저는 L 토큰 + R 토큰으로 나눌 때, 분리 기준 으로 점수가 가장 높은 L 토큰 을 찾아내는 원리를 가지고 있다.
최대 점수 토크나이저
최대 점수 토크나이저(MaxScoreTokenizer)는 띄어쓰기가 되어 있지 않은 문장 에서 점수가 높은 글자 시퀀스를 순차적으로 찾아내는 토크나이저 이다.
- 참고문헌
AIFFEL 대전 GD 노드
잠재 의미 분석(Latent Semantic Analysis, LSA)
위키독스: 잠재 디리클레 할당
