- 이 포스팅은 스터디 준비하면서 만든 자료를 정리한 것입니다.
“garbage in, garbage out!”
Feature Engineering을 잘 표현한 문장이다. Feature Engineering은 데이터 분석에서 많은 지분을 차지하는 부분이다.
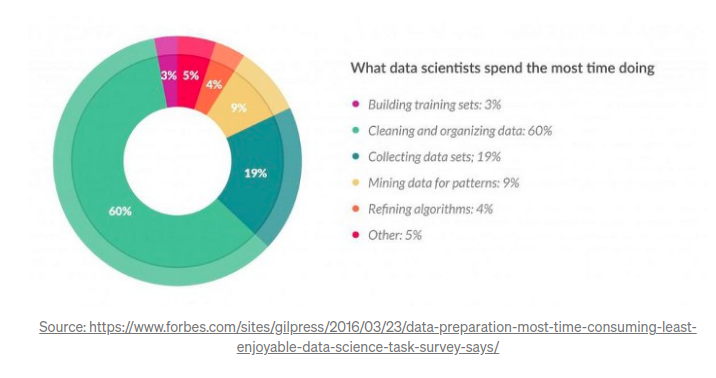
위의 그림에서 보듯 데이터 사이언티스트들은 데이터 준비에 약 80%의 시간을 투자한다. 그렇다면 Feature Engineering이란 무엇일까?
Feature Engineering의 정의
Feature Engineering은 모델 정확도를 높이기 위해서 주어진 데이터를 예측 모델의 문제를 잘 표현할 수 있는 features로 변형시키는 과정이다. '머신러닝 알고리즘을 작동하기 위해 데이터의 도메인 지식을 활용해 feature를 만드는 과정'이라고 할 수도 있다.
- Feature Engineering is a Representation Problem.
- Feature: An attribute useful for your modeling task
The goals of Feature Engineering
- 머신 러닝 알고리즘에 걸맞는 적당한 입력 데이터셋을 준비
- 머신 러닝 모델의 성능을 향상시키는 것
Importance of Feature Engineering
- Better features means flexibility.
: 덜 복잡한 모델을 써도 좋은 결과를 얻을 수 있다. - Better features means simpler models.
: 가장 최적화된 hyperparameter를 찾으려고 노력하지 않아도 된다. - Better features means better results.
Approaches of Feature Engineering
Feature Importance: An estimate of the usefulness of a feature
: Correlation coefficients and other univariate 사용할 수 있음 또는 복잡한 예측 모델의 경우 모델 생성하면서 같이 생성할 수도 있음. 아래의 그림은 랜덤포레스트를 사용한 후 얻은 Feature Importance이다.

Feature Extraction: The automatic construction of new features from raw data
: PCA, unsupervised clustering methods (차원 감소: 관측 데이터를 잘 설명할 수 있는 잠재 공간 찾기)
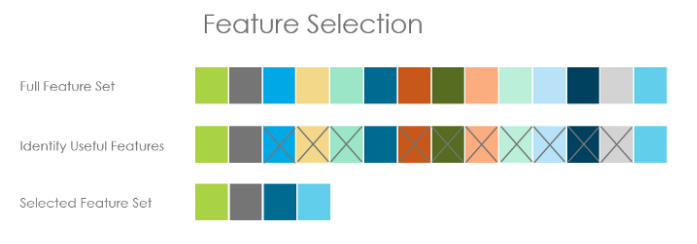
Feature Selection: From many features to a few that are useful
: correlation, feature importance, 모델 생성하면서 자동으로 제거되기도 함.
Feature Construction: The manual construction of new features from raw data
: 어렵고 시간이 많이 걸리지만 가장 큰 효과를 얻을 수 있다.
- 흔히 이 방법을 Feature Engineering이라고 부른다.
- 모델의 성능을 높이는 새로운 특성 만들기
- 데이터 합치기, 쪼개기 등의 작업
Feature Learning: The automatic identification and use of features in raw data
: autoencoders and restricted Boltzmann machines, a unsupervised/semi-supervised way

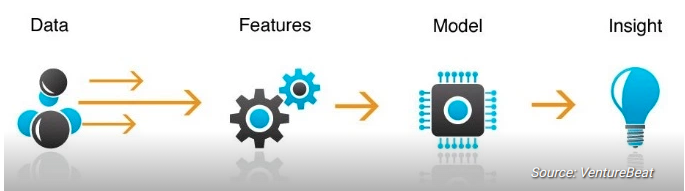
Process of Machine Learning
- A problem definition
- Data selection: integrate data, de-normalize data into a dataset, collect data
- Preprocess Data: format, clean, sample data
- Transform Data: Feature Engineer
- Model Data: create models, evaluate, and tune them.
Iterative Process of Feature Engineering
- Brainstorm features: 문제확인, 많은 데이터 보기, 다른 문제들에서 어떻게 feature engineering 했는지 보고 필요한 것을 가져옴.
- Devise features: 문제에 따라 automatic feature extraction, manual feature construction, 또는 두 개를 섞은 방법을 사용하여 features를 변형시킨다.
- Select features: feature importance scorings, feature selection 사용.
- Evaluate models: 선택한 features가 적용된 새 데이터(unseen)에 대한 모델 정확도를 추정한다.
- Revise features: 필요한 경우 feature 개선
- 위의 과정을 반복한다!
The techniques of Feature Engineering
아래의 방법을 다양한 데이터셋에 사용해보고 모델 성능이 어떻게 되는지 관찰할 것!
- Imputation
- 결측치: 머신러닝 모델 성능에 영향을 준다.
- 70% 이상의 결측치가 있는 행과 열은 지워주는 것도 좋다.
- Numerical Imputation: 결측치를 0이나 중앙값으로 대체
- Categorical Imputation: 열의 가장 많이 발생한 값으로 결측치를 대체, 만약 많이 발생한 값이 없다면 'Other’로 대체
- Random sample imputation: 데이터셋에서 임의로 뽑은 값으로 결측치 대체
- End of Distribution Imputation: 결측치를 mean+3*std로 대체
- Outliers

- outliers는 시각적으로 볼 것!

- 표준편차를 이용한 이상치 탐지
: ‘값과 평균까지의 거리 > x*표준편차'(x: 2-4 사이의 값)라면 이상치 - 벡분위수(percentile)를 이용한 이상치 탐지
: 데이터의 분포에 따라 특정 %(예: 95%) 바깥에 있는 값이 이상치 - 이상치를 가지고 갈지, 제거할 지 결정해야 함.
- Binning
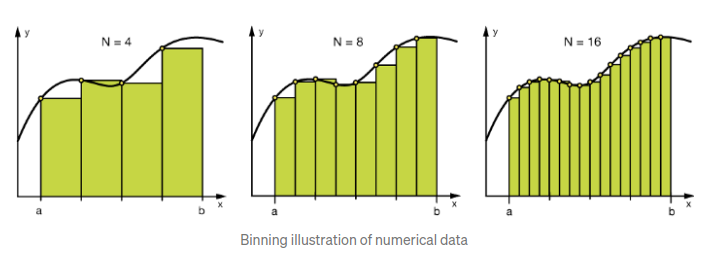
- Binning은 categorical / numerical data에 모두 적용 가능
- Binning을 하는 이유는 모델을 더 robust하게 만들고 오버피팅을 방지하기 위해서
- 그러나 비용이 비싸다. (the trade-off b/w performance and overfitting)
- 숫자로 이루어진 열의 경우에는 별 필요가 없지만 범주형 열에는 필요할 수 있다.
- 예: 100,000개의 열로 구성된 데이터셋의 경우, 100개 이하로 구성된 카테고리들은 하나로 합치는 것이 나을 수도 있다.
- Log Transform
- 로그 변환은 한 쪽으로 편향된(skewed) 데이터를 분포가 정규 분포에 가깝게 만들어 준다.
- 15세와 20세/65세와 70세의 차이는 같지 않음. 이 경우 로그 변환이 그 차이를 정규화해준다.
- 이상치의 영향을 줄여주고 모델이 보다 robust하게 만들어준다.
- 주의: 데이터가 양수로 이루어져야 한다. 때로 1을 더해줄 수도 있다. log(x+1)
- One-hot encoding
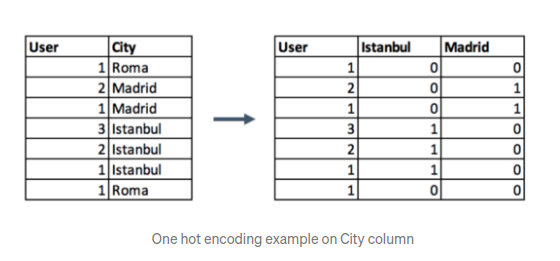
원-핫 인코딩은 범주형 자료를 수치형 자료로 바꿔주어서 정보 손실 없이 범주형 자료를 그룹화할 수 있게 한다.
- Grouping Operations
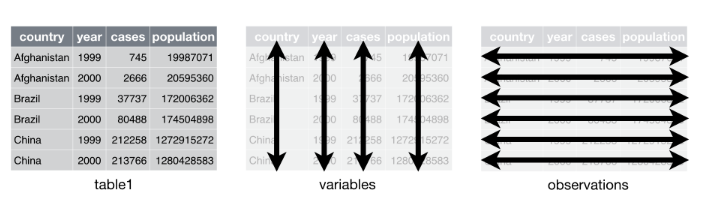
- Tidy: 데이터셋의 변수가 열, 관측값이 행으로 이루어진 데이터. 조작, 모델링, 시각화가 쉬움.
- 일반적으로 데이터는 변수가 행으로 이루어져 있으므로 변수에 의해 데이터를 그룹화하여 한 행으로 변수가 표현되게 만든다. (Tidy 데이터로 만듬)
- 그룹화할 때 features의 병합 함수를 사용해야 한다. 예: 숫자로 이루어진 features는 평균과 합으로 그룹화.
- 범주형 데이터의 경우는 피봇 테이블을 이용하거나 원-핫 인코딩을 한다. (자세한 내용은 참고문헌 참고! )
- Feature Split
- 유용한 방법. 여러 가지 방법이 존재함.
- 예: 이름과 성을 따로 분리.
- 'Toy Story (1995)'라면 ‘Toy Story’ 와 '1995'를 분리.
- Scaling
- 대부분의 데이터가 range가 다르기 때문에 scaling을 해주어야 함.
- Normazliation(min-max normalization): 데이터를 0과 1사이의 값으로 변환. 이상치의 영향력이 커지므로 정규화 후 이상치를 다룰 것!
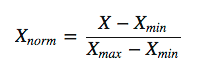
- Standaridization(z-score normalization): 데이터마다 range가 다름. 이상치의 영향력이 줄어듬.
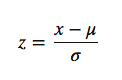
- Extracting Data
- 날짜를 다른 행으로 분리: 년도, 월, 요일 등
- 특정 날짜에 대한 feature를 뽑아냄: 주간의 이름(1주, 2주, 등) 주말인지 아닌지, 공휴일인지 아닌지.
General Examples of Feature Engineering
- Decompose Categorical Attributes
예: color(feature) - Red, Blue, Unknown -> 3개의 feature로 나눌 수 있음 - Decompose a Date-Time
예: Part_Of_Day - Morning, Midday, Afternoon, Night - Reframe Numerical Quantities
예: a weight(6289gram) -> Item_Weigh(6)
Item_Above_4kg(4kg이 넘으면 높은 세율이 적용되는 경우)
Feature Engineering Tools

Featuretools
The Best Feature Engineering Tools
참고문헌
https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
https://towardsdatascience.com/feature-engineering-for-machine-learning-3a5e293a5114
https://www.youtube.com/watch?v=9eP4bMqJYX4
- 아래의 문헌에서 이미지를 가져왔다.
feature importance
feature selection
feature extraction
feature learning
Tidy
