- 이 글은 wikidocs에 있는 '딥러닝을 이용한 자연어 처리 입문'을 정리한 것입니다.
텍스트 전처리(Text preprocessing)
텍스트 전처리는 용도에 따라 텍스트를 미리 처리하는 작업이다. 텍스트를 제대로 전처리하지 않으면 자연어 처리 기법이 제대로 동작하지 않기 때문에 자연어 처리에서 텍스트 전처리는 매우 중요하다. 텍스트 전처리에는 아래와 같은 각종 기법이 있다.
- 토큰화
- 정제와 정규화
- 어간 추출과 표제어 추출
- 불용어
- 정규표현식
- 정수 인코딩
- 패딩
- 원-핫 인코딩
- 데이터의 분리
- 한국어 전처리 패키지
어간 추출과 표제어 추출
어간 추출과 표제어 추출은 정규화 기법 중 코퍼스에 있는 단어의 개수를 줄일 수 있는 기법이다. 이 두 기법을 통해 서로 다른 단어를 하나의 단어로 일반화시켜서 문서 내의 단어를 줄일 수 있다. 이 방법은 단어의 빈도수를 기반으로 문제를 푸는 BoW(Bag of Words) 표현을 사용하는 자연어 처리 문제에서 주로 사용된다.
표제어 추출과 어간 추출의 차이
표제어 추출은 문맥을 고려하기 때문에 수행 결과가 해당 단어의 품사 정보를 보존한다(를 보존한다). 반면 어간 추출은 품사 정보가 보존되지 않기 때문에(POS 태그를 보존하지 않음) 사전에 존재하지 않는 단어일 경우가 많다.
어간 추출과 표제어 추출의 결과 비교
Stemming
- am → am
- the going → the go
- having → hav
Lemmatization
- am → be
- the going → the going
- having → have
표제어 추출(Lemmatization)
'Lemma'란 '표제어' 또는 '기본 사전형 단어'로 해석할 수 있다. 표제어 추출은 단어가 다른 형태를 가져도 뿌리 단어를 찾아가 단어의 개수를 줄일 수 있는지 판단한다. 예를 들면 'am, are, is'는 다른 형태이지만 뿌리 단어는 'be'이므로 'am, are, is'의 표제어는 'be'이다.
표제어 추출을 하는 가장 섬세한 방법은 단어의 형태학적 파싱을 하는 것이다. 형태소란 '의미를 가진 가장 작은 단위'이며 가 존재한다. 어간이란 단어의 의미를 가지고 있는 단어의 핵심이고, 접사는 단어에 추가적인 의미를 주는 부분이다.
형태학적 파싱은 어간과 접사로 단어를 분리하는 작업이다. 예를 들어 'cats'를 형태학적 파싱을 하면 'cat + s'로 분리할 수 있다. 그러나 'cat'과 같이 독립적인 형태소일 경우는 분리할 수 없다.
표제어 추출 방법
NLTK(NLTK: 자연어 처리를 위한 파이썬 패키지)에서는 표제어 추출을 위한 도구인 WordNetLemmatizer 를 지원하므로 이를 통해 표제어 추출을 할 수 있다.
from nltk.stem import WordNetLemmatizer
n=WordNetLemmatizer()
words=['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print([n.lemmatize(w) for w in words])결과: ['policy', 'doing', 'organization', 'have', 'going', 'love', 'life', 'fly', 'dy', 'watched', 'ha', 'starting']
어간 추출과 달리 표제어 추출은 단어의 형태가 대부분 적절히 보존된다. 그러나 'dy, ha' 같이 의미를 알 수 있는 단어를 출력하기도 한다. 이는 표제어 추출기(lemmatizer)가 본래 단어의 품사 정보를 알아야 정확한 결과를 얻을 수 있기 때문이다. 따라서 해당 단어가 동사라는 것을 알려준다면 표제어 추출기는 품사의 정보를 보존하면서 정확한 Lemma를 출력할 수 있다.
n.lemmatize('dies', 'v') # 결과: 'die'
n.lemmatize('has', 'v') # 결과: 'have'어간 추출(stemming)
어간 추출은 어간을 추출하는 작업이며, 정해진 규칙만 보고 단어의 어미를 자르기 때문에 어간 추출 후 나오는 결과 단어는 사전에 존재하지 않는 단어일 수도 있다.
포터 알고리즘
어간 추출 알고리즘 중 하나인 포터 알고리즘(Porter Algorithm)에 아래의 Text를 입력으로 넣고 어간 추출을 한 결과를 살펴보자.
input : This was not the map we found in Billy Bones's chest, but an accurate copy, complete in all things--names and heights and soundings--with the single exception of the red crosses and the written notes.
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
s = PorterStemmer()
text="This was not the map we found in Billy Bones's chest, but an accurate copy, complete in all things--names and heights and soundings--with the single exception of the red crosses and the written notes."
# 토큰화
words=word_tokenize(text)
print(words)결과: ['This', 'was', 'not', 'the', 'map', 'we', 'found', 'in', 'Billy', 'Bones', "'s", 'chest', ',', 'but', 'an', 'accurate', 'copy', ',', 'complete', 'in', 'all', 'things', '--', 'names', 'and', 'heights', 'and', 'soundings', '--', 'with', 'the', 'single', 'exception', 'of', 'the', 'red', 'crosses', 'and', 'the', 'written', 'notes', '.']
# 어간추출
print([s.stem(w) for w in words])결과: ['thi', 'wa', 'not', 'the', 'map', 'we', 'found', 'in', 'billi', 'bone', "'s", 'chest', ',', 'but', 'an', 'accur', 'copi', ',', 'complet', 'in', 'all', 'thing', '--', 'name', 'and', 'height', 'and', 'sound', '--', 'with', 'the', 'singl', 'except', 'of', 'the', 'red', 'cross', 'and', 'the', 'written', 'note', '.']
포터 알고리즘의 어간 추출은 아래와 같은 규칙을 가진다.
- ALIZE -> AL (예: formalize -> formal)
- ANCE -> 제거 (예: allowance -> allow)
- ICAL -> IC (예: electricical -> electric)
words=['formalize', 'allowance', 'electricical']
print([s.stem(w) for w in words])결과: ['formal', 'allow', 'electric']
어간 추출 속도는 표제어 추출보다 일반적으로 빠르다. 또한 포터 어간 추출기는 정밀하게 설계되어 정확도가 높으므로 영어 자연어 처리에서 빠르고 정확한 어간 추출을 위해서 선택하면 좋다.
포터 스테머 vs 랭커스터 스테머(Lancaster Stemmer)
# 포터 스태머
from nltk.stem import PorterStemmer
s=PorterStemmer()
words=['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print([s.stem(w) for w in words])결과: ['polici', 'do', 'organ', 'have', 'go', 'love', 'live', 'fli', 'die', 'watch', 'ha', 'start']
# 랭커스터 스테머
from nltk.stem import LancasterStemmer
l=LancasterStemmer()
words=['policy', 'doing', 'organization', 'have', 'going', 'love', 'lives', 'fly', 'dies', 'watched', 'has', 'starting']
print([l.stem(w) for w in words])결과: ['policy', 'doing', 'org', 'hav', 'going', 'lov', 'liv', 'fly', 'die', 'watch', 'has', 'start']
동일한 단어를 넣었을 때 위의 두 스테머는 서로 다른 결과를 보여준다. 그 이유는 두 스테머가 서로 다른 알고리즘을 사용하기 때문이다. 따라서 알려진 알고리즘을 사용할 때는 사용하려는 코퍼스에 스테머를 적용해보고 어떤 스테머가 해당 코퍼스에 적합한지 판단한 후에 사용해야 한다.
어간추출 사용의 주의점
규칙에 기반한 알고리즘은 때로 제대로 일반화하지 못할 때가 있으므로 주의해야 한다. 예를 들어 포터 스테머에서 'organization'(조직)을 어간 추출하면 그 결과는 'organ'이다. 하지만 'organ'(장기)을 어간 추출해도 그 결과는 'organ'이다. 서로 다른 두 단어의 어간 추출의 결과가 같게 나오므로 어간 추출의 목적에 맞지 않다.
POS tagging(part-of-speech tagging): 형태소 분석 결과 분류된 품사를 태깅하는 작업. 태깅시 품사에 대응하는 약속은 품사 태그(POS tag: part-of-speech tag)라고 하며 품사 태그의 모음을 품사 태그 셋이라고 한다.영어 품사 태그셋
한국어 품사 태그셋
참고: 품사와 품사 태그셋 소개
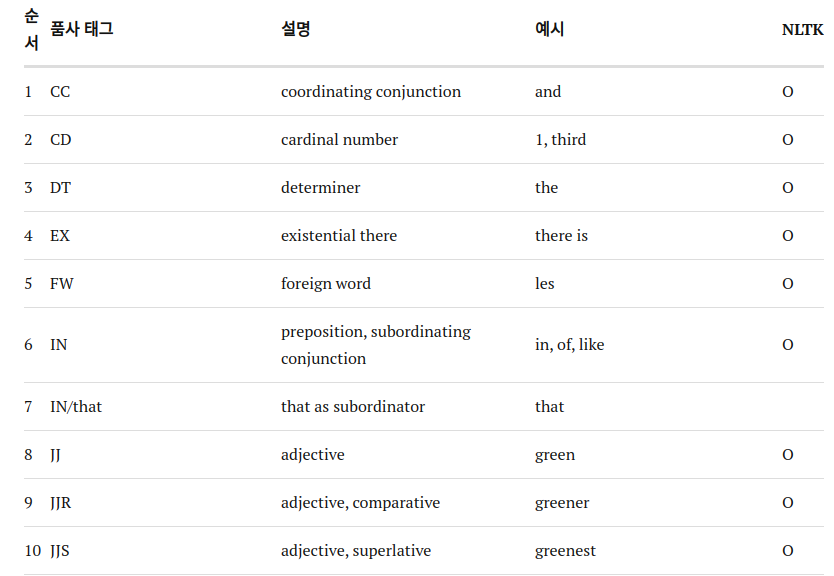
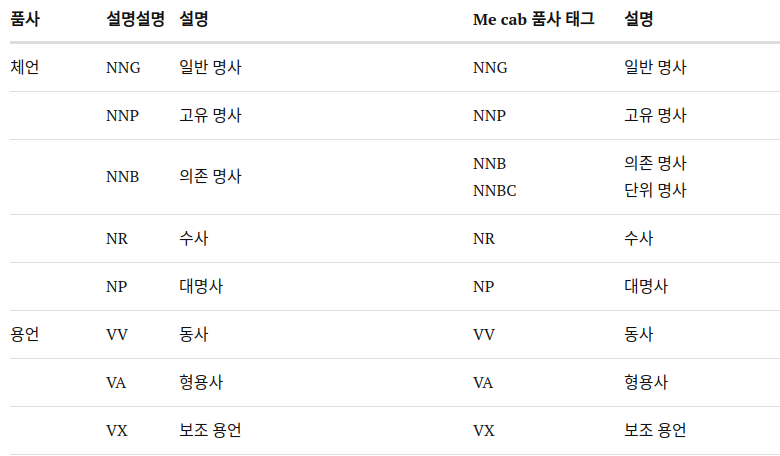
한국어어간과 어미
어간과 어미는 동사와 형용사에서만 쓰인다. 용어 활용시 변하지 않는 부분이 어간, 변하는 부분이 어미이다. 예를 들어 동사 '먹다, 먹고, 먹니, 먹으며, 먹어서'에서 '먹'은 어간, 어미 뒤에서 변하는 부분을 어미이다.어근과 접사
어근과 접사는 모든 단어에서 쓸 수 있다. 어근은 단어에서 실질적인 의미를 나타내는 부분이고 접사는 어근에 붙어 어근의 뜻을 제한하는 부분이다. 어근은 혼자 쓰이거나 어근끼리 모여 쓸 수 있지만 접사는 어근 없이 혼자 쓸 수 없다. 또한 접사는 어근 앞에 붙으면 접두사, 어근 뒤에 붙으면 접미사라고 부른다.
- 나무, 국어, 소금, 여름 (어근 1개인 단어)
- 햇 과일, 맨 손, 군 살, 치 솟다 (접두사 + 어근)
- 나무꾼 , 선생님 , 먹이다, 알리다 (어근 + 접미사)
어근과 어간
- 기저(base): 단어의 중심 역할을 하는 형태소
- 어근(root): 어미와 직접 결합할 수 없고 자립형식도 아닌 어기. 시원 하다, 급 하다, 학 교
- 어간(stem): 어미와 직접 결합할 수 있으나 자립형식은 아닌 어기. 뛰 어라, 먹 다 등
- 접사(affix): 어기와 겹합해야 출현할 수 있는 의존 형태소
- 어미(ending): 단어의 어미변화를 담당하는 굴절접사, 한국어의 모든 굴절접사는 접미사이다. '뛴다'의 '-ㄴ다', '뛰고'의 '-고' 등
영어
형태소
형태소란 의미를 가진 최소 단위이다. 형태소의 분류는 아래의 그림을 참조하면 된다.
어근은 단어의 핵심 의미를 가지고 있는 부분이고 접사는 단어 형성과 관련이 있다.
- permit: per + mit (두 개의 라틴어 어근의 결합)
- permission: per + mit + sion (두 개의 어근과 sion이라는 접사(정확히는 접미사))
더 자세한 내용은 여기를 참조하세요.
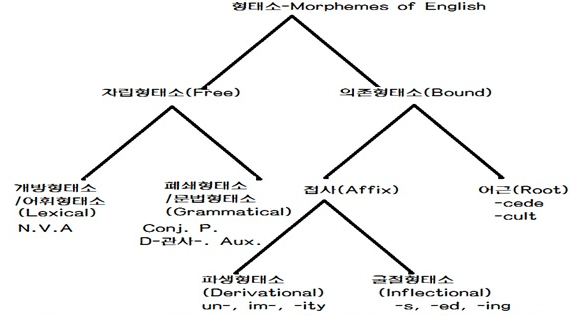
어근(root)과 어간(stem)
- 어근: 의존형태소가 붙을 수 있는 것, 더이상 나눌 수 없는 최소단위, 단어의 뜻의 핵심
- 어간: 어근이 의존형태소와 결합한 것. inflected(-s, -ed, -ing, -er, -est 등)되지 않은 형태소의 결합
- paint(어근) + er(의존형태소:접미사) = painter(단어/어간)
- painter(어간) + s(의존형태소:접미사) = painters(단어)
- desire(어근) + able(접미사) = desirable(단어/어간)
- undo의 어근은 'Do', 어간은 'Undo'이다.
참고: http://contents.kocw.or.kr/KOCW/document/2015/hanyang_erica/hwangjuhyeon1/12-2.pdf
https://m.blog.naver.com/PostView.nhn?blogId=o_-helloworld&logNo=221014185619&proxyReferer=https:%2F%2Fwww.google.com%2F
