⭐ 의사결정트리
의사결정트리는 입력 데이터에 따라 목표 변수의 값을 예측하는 실행 모델을 만들기 위해 사용한다.
✔️ 의사결정트리의 사용
의사결정트리 사용의 예로,
-
마케팅 분야
의사결정트리를 사용하여 고객을 유형별로 정의하고 어떤 종류의 제품을 구매할 것인지 예측함. -
의학 분야
진찰, 처치, 환자 데이터 등을 변수로 사용하여 혈액 감염을 진단하거나 가슴통증 환자의 심장 발작을 예측함. -
게임 분야
동작과 얼굴을 인식하는 데 다중의사결정트리 (multiple decision tree)가 사용됨. 사례로 마이크로소프트의 키넥트 플랫폼은 이미지 백만장과 훈련된 트리 세 가지를 사용하여 하루 동안 1000개의 코어로 구성된 클러스터를 사용하여 특정 신체 부위를 분류함
✔️ 의사결정트리의 장점
- 이해하기 쉽다
- 모델을 만든 다음 트리가 어떻게 작동되는지 다른 사람에게 보여주기 쉽다
- 숫자 정보와 범주 정보 모두 다룰 수 있다
- 데이터를 준비할 때 따로 할 게 없다
데이터 포맷만 있으면 실행 모델을 만들 수 있음 - 여러 테스트를 통해 유효성을 검증하기 쉽다
- 화이트박스 테스팅(white-box testing, 내부 동작을 관측할 수는 있지만 변경은 불가)을 사용할 수 있다
- 트리가 모델화될 때 각 단계를 볼 수 있다
- 컴퓨터의 성능이 뛰어나지 않아도 의사결정트리 학숩은 대용량 데이터로도 잘 수행된다.
✔️ 의사결정트리의 한계
- 훈련용 데이터에 따라 지나칠 정도로 복잡한 모델이 만들어질 수 있다 (과적합 이슈)
- 따라서 Training Data를 꼼꼼히 검토할 필요가 있음
- 개념이 어렵다
✔️ 의사결정트리 분석을 위한 알고리즘
| 알고리즘 | 설명 |
|---|---|
| ID3 | ✏️ 로스 퀸런이 개발함 ✏️ Data Set의 모든 속성에 대한 entropy를 계산한다 ✏️ 최소 entropy 기준으로 작은 Data Set으로 분류한다 ✏️ 데이터로부터 의사결정트리의 노드를 결정하고 남은 속성에 대해 같은 일을 반복한다 ✏️ ID3는 정보획득량 (Information Gain, 속성이 나눠지기 전후의 엔트로피 차이를 측정)을 사용하여 루트 노드 (Root Node, 최고의 정보량을 가진 노드)를 결정함 ✏️ ID3는 과적합 문제가 있어 규모가 작은 트리에 적합 |
| C4.5 | ✏️ 로스 퀸런이 ID3 이후에 개발함 ✏️ 정보획득량에 기반하여 분류에도 적용할 수 있다 ✏️ 웨카에서 C4.5 오픈 소스 자바 버전인 J48 알고리즘으로 사용할 수 있음 ✏️ ID3와 비교하였을 때 C4.5는 연속형 값을 갖는 속성을 다룰 수 있어 가지가 분리되는 한계점을 계산할 수 있다 ✏️ NA인 경우도 사용 가능 ✏️ C4.5로 만든 트리는 만들어진 후에 가지치기 되며 알고리즘은 노드를 순회하며, 노드가 트리의 결과에 영향을 주는지 알아낸다 ✏️ 영향을 주지 않는다면 노드는 leaf node 로 치환됨 |
| CHAID (Chi-squard Automatic Intersaction Detection) | ✏️ 1980년 고든 카스가 개발함 |
| MARS (Multivariate Adaptive Regression Splines) | ✏️ 숫자 데이터를 다룰 때 유용 |
✔️ 의사결정트리의 원리
-
노드 (node)
모든 트리는 노드로 구성되며 각 노드는 input 변수와 연관있음. -
간선(edge)
노드와 노드 사이의 연결선을 뜻함. -
리프 (leaf)
루트 노드에서 리프까지의 경로 중 입력 변수에 기반한 값을 의마함.
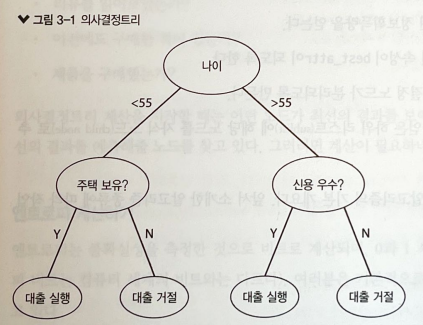
위 그림 (대출 심사를 분류하는 의사결정트리)을 해석해보면 루트 노드는 '나이'이며, 두 개의 가지(branch)가 나왔다. 이 가지는 고객 연령이 55세보다 많은지 적은지를 의미하며 고객의 연령에 따라 대출 심사의 기준이 달라지는 것을 확인할 수 있다. 55세보다 적다면 고객이 주택을 보유하고 있는지 알아봐야 하며, 55세보다 많다면 신용 등급을 확인하여 대출 여부를 결정한다.
이런 종류의 머신 러닝은 Supervised Learning을 사용하며 루트 노드로 시작하기에 가장 좋은 노드는 무엇인지.. 최적의 모델을 찾아낸다.
✔️ 의사결정트리 만들기
의사결정트리는 다음과 같은 과정을 통해 만들어진다.
- 기본 문제를 위한 모델을 확인
- 모든 속성 (attr)을 반복, 순회
- attr를 분리하여 정규화된 정보획득량을 얻음
- 최고의 정보획득량을 가진 속성이 best_attr이 되도록 함
- best_attr 속성에서 의사결정 노드가 분리되도록 함
- best_attr에서 분리하여 얻은 하위 리스트 (sublist)에 해당 노드를 자식 노드(child node)로 추가
✔️ 예제
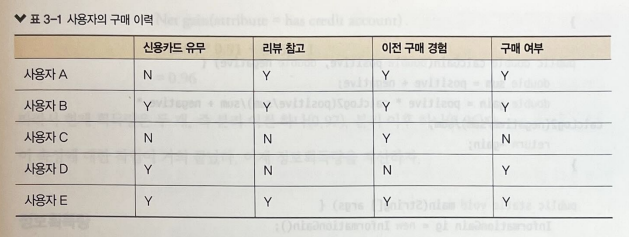
✏️ 어떤 노드를 루트 노드로 사용하는 것이 최선인지 파악 (각 노드의 순수도를 알아야 함)
표의 노드는 아래와 같음
- 신용카드가 있는가?
- 리뷰를 읽어보았는가?
- 이전에도 구매한 적이 있는가?
- 제품을 구매했는가?
✏️ 엔트로피 계산하기
엔트로피는 불확실성을 측정한 것을 뜻하며, 이진법 비트로 계산된다.
public class InformationGain {
private double calcLog2(double value) {
if(value <= 0.)
return 0.;
return Math.log10(value)/ Math.log10((2.));
}
public double calcGain(double positive, double negative) {
double sum = positive + negative;
double gain = positive * calcLog2(positive/sum)/sum +negative * calcLog2(negative/sum)/sum;
return -gain;
}
public static void main(String[] args) {
InformationGain informationGain = new InformationGain();
System.out.println(informationGain.calcGain(3,2));
}
}
- 신용카드가 있는 사람과 없는 사람의 순획득량
Gain(3,2) = (3/5)log2(3/5) + (2/5)log2(2/5) = 0.97
- 신용카드 유무 속성에 이은 리뷰 참고 속성
리뷰 참고 = [Y,Y,N]
리뷰 참고 x = [N,Y]
- 첫 속성에서 분리된 엔트로피 계산
Gain(2,1) = (2/3)log2(2/3) + (1/3)log2(1/3) = 0.91
Gain(1,1) = (1/2)log2(1//2) + (1/2)log2(1/2) = 1
- 순획득량 (net gain) 계산
Net gain(attribute = has credit account)
= (2/5) 0.91 + (3/5) 1
= 0.96
- 정보획득량 계산
Information Gain = Gain(before the split) - Gain(after the split)
= 0.97 - 0.96
= 0.01
➡️ '신용카드 유무' 속성의 정보획득량은 0.01
✏️ 다른 노드도 위외 같이 반복
| 속성 | 정보획득량 |
|---|---|
| 신용카드 유무 | 0.01 |
| 리뷰 참고 | 0.57 |
| 이전 구매 경험 | 0.234 |
'리뷰 참고' 속성의 정보획득량이 가장 높으므로 트리에서 루트 노드가 되며,
'이전 구먀 경험' 속성이 그 다음 노드가 된다.
의사결정 트리에서는 정보획득량이 높은 순서대로 노드를 둠.
