
db 읽기/쓰기 용량
'자막 수집 서비스'를 만들고 데이터를 요청하니까 이런 에러가 발생했다 😢
Error retrieving posts from DynamoDB: An error occurred (ProvisionedThroughputExceededException) when calling the Scan operation (reached max retries: 9): The level of configured provisioned throughput for the table was exceeded. Consider increasing your provisioning level with the UpdateTable API.
짐작으로 해석해봤을 때 프로비저닝된 요청 수를 초과하여 에러가 발생했다는 의미로 봤다.
일정 트래픽을 소화하지 못한다는 의미인데...
당시 아쉬웠던게 큰 트래픽을 요청한게 아니었기 때문이다.
둘이서 동시에 그냥 데이터를 조회한 정도...?
예전에 MongoDB의 꽤 괜찮은 read 성능을 경험했던 이유도 있다.
다양하게 해결법을 생각해보다가 DynamoDB를 온디맨드로 만들어 보았다.
그랬더니.. 문제 바로 해결! 🤣
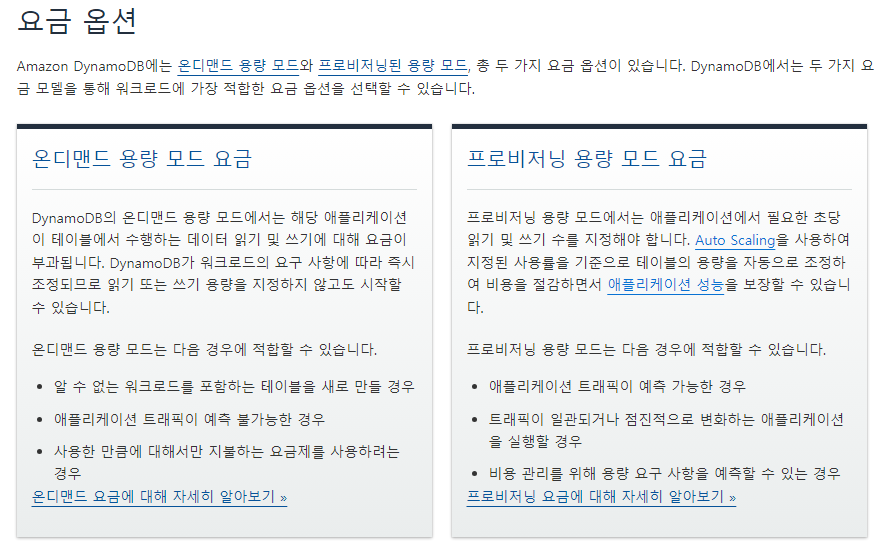
두 용량 모드의 차이점은 '트래픽을 정말 예측할 수 있냐,없냐'인 것 같다.
예측이 가능하면 프로비저닝 용량으로 만들어 직접 읽기/쓰기 용량을 정해주는게 핵심인 것 같다.
보조 인덱스
게시판이다 보니 검색 기능이 필요했다.
DynamoDB는 쿼리를 통한 검색이 가능하고 이때 파티션 키가 필요했다.
내 경우 video_id가 파티션 키였고 검색하고 싶었던 컬럼은 leetcode_number 였다.
그럼 어떻게 검색을 하냐?
보조 인덱스를 만들어야 한다 👍
검색 방법은 알아냈지만 python 코드로 작성하면서 에러가 발생해 애를 먹었다.
ValidationException: One or more parameter values were invalid: Condition parameter type does not match schema type
위와 같은 에러를 100번은 본 것 같고 결국 보조 인덱스 사용은 성공했다.
response = table_object.query(
TableName='Subtitle-Ondemand',
IndexName='leetcode_number-index', # 생성한 글로벌 보조 인덱스 이름
KeyConditionExpression='leetcode_number = :number',
ExpressionAttributeValues={
':number': int(search_query) # 이 부분에서 에러가 많이 발생했다.
}
)파이썬 코드 작성이 나에게는 생소한 영역이라 gpt를 통한 질의응답을 많이 사용했는데...
에러에 대한 탐색은 구글링을 하는 것이 최고인 것 같다.
찾아낸 해결법은 심지어 5년 전 답변이다 🤷♂️
gpt는 정말 그럴듯한 답변을 주는 멍청이인 것...
참고 문헌
