
원하는 결과를 얻기 위해 검색을 하곤 한다.
이번 포스팅은 잘못된 검색에 대한 고찰을 짧게 적어본다 🔥
잘못된 검색
내가 구현한 '자막 수집 서비스'에 NLP 팀 한 분(팀장)이 새로운 기능을 구현했다.
검색을 통해 leet code number에 해당하는 영상들을 조회하는 기능이었다.
그런데 생각보다 관련 없는 영상들이 많이 조회되는 상황이 발생했다 😢
팀장님은 검색을 'leet code number + title'을 이용한 쿼리로 만들었다.

이때 이상한 점을 발견했는데...
일부 문제에서 실제 title과 다른 title로 검색이 되고 있었다.
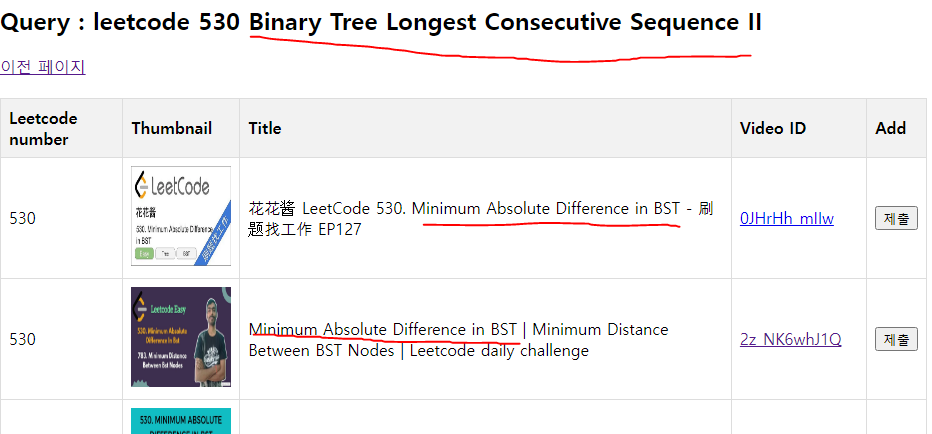
우리는 huggingface에 있는 데이터를 통해 leet code number와 title을 조회하고 있었고 그 데이터는 잘못된 데이터가 많았다 🤔
그래서 불순물 데이터가 많이 검색되었던 것이다.
검색 성능 개선
잘못된 검색어는 검색 성능을 떨어트릴 것이란 건 누구나 아는 사실이다.
그래도 이렇게 사용하는 데이터가 잘못되었음을 파악하는 것은 어렵다.
현재 데이터를 직접 수집하고 전처리하는 과정에서 올바른 데이터를 수집하는 것은 굉장히 어렵다는 것을 몸소 느끼기도 한다.
어쨌든 검색은 title을 제외하고 leet code number만으로 검색되게 쿼리를 수정했고
괜찮은 데이터를 조회할 수 있게 개선했다 👍

날씨의 아이 ☀️ Java Spring ☘️