BART: Denoising Sequence to Sequence Pre-training for Natural Language Generation, Translation, and Comprehension

이번에 소개할 논문인 BART은 2019년 10월에 Facebook에서 발표한 논문입니다.
논문 제목에서 명확하게 알 수 있다시피 BART는 Denoising 기법을 seq2seq에 적용시켜 자연어 생성, 번역 그리고 이해를 하는 모델입니다.
해당 내용은 논문에서 소개되는 순서로 진행을 할 예정입니다.
0. Abstract
BART는 pretraining objective는 Denoising task로 두며 seq2seq arachitecure를 기본으로 삼고 있습니다. BART는 text를 corrupting하여 임의의 noise를 주어 훼손시키고, 다시 original text로 복구하는 식으로 학습을 진행합니다. seq2seq의 Encoder는 BERT(with bidirectional encoder)의 AE 특성을 가지고 있고, Decoder는 GPT(with left-to-right decoder)의 AR 특성을 가지고 있어, BART는 BERT와 GPT의 특성을 합쳤다고 볼 수 있습니다. 논문에서는 다양한 방식으로 text에 noising을 주어서 실험을 진행합니다. BART는 fine-tuning을 진행하면 특히 text generation과 comprehension task에서도 성능이 잘 나옵니다.
1. Introduction
word2vec, ELMO, BERT, SpanBERT, XLNET, Roberta 등과 같은 Self-supervised 기반의 모델들은 다양한 NLP task에 있어 좋은 활약을 보여줬습니다. 이 중에서도 단연코 가장 성공적인 접근법은 autoencoder를 denoising하는 MLM (masked language model)의 변형들입니다. 하지만 금일 제가 발표하는 논문에 따르면, 기존에 소개되는 MLM 기반의 모델들은 특정 End task에만 집중을 하여 활용성이 떨어진다는 단점을 지적하며 BART를 소개했습니다. BART는 Abstract에서 소개드린 바와 같이, BERT와 GPT를 합친 즉, Bidirectional한 Transformer의 encoder 그리고 Auto-Regressive한 Transformer의 decoder를 합친 seq2seq 모델을 학습시킨 모델입니다. 구조를 이렇게 설계했기 때문에, 앞서 기존의 활용성이 떨어진다는 MLM 기반 모델의 한계점과 다르게, BART는 Noising Flexiblity에 대한 이점을 얻을 수 있습니다. Noising Flexiblity란 제가 이해한 바로는, Arbitrary Transformations이 원본 text에 적용되어서 토큰 혹은 text의 길이 등을 자유로이 변형 할 수 있다는 말입니다. 다른 말로는, 이는 원본 text에 noise를 어떤식으로든 유연하게 적용할 수 있다고 이해해주시면 될 것 같습니다. Arbitrary Transformations에는 5가지 기법이 소개되는데, 뒤에서 자세히 설명을 드리겠습니다.
2. Model
기존 seq2seq는 RNN계열의 GRU, LSTM, Simple RNN 등을 Encoder와 Decoder의 모델로 활용을 했지만, BART는 Transformer의 Encoder와 Decoder를 활용합니다. 여기 부분이 BART 모델이 BERT와 GPT 모델과 다르다고 볼 수 있는 핵심적인 부분입니다.
BART vs BERT
BART는 Denoising Task를 pretraining objective로 두어 학습을 하고, BERT도 MLM으로 Denoising Autoencoding Task를 pretraining objective로 두어 학습을 합니다. 즉, BART와 BERT의 pretraining objective는 동일한데 어떤 점들이 다를까요?
BERT

먼저 BERT는 아래 그림과 같이 Transformer의 Encoder로 구성이 되어있습니다. 다들 아시다시피, 이전 BERT 세미나를 복습하는 차원으로 보면 BERT는 pretraining objective로 NSP (Next Sentence Prediction)과 MLM (Masked Language Model)을 두어 학습을 합니다. NSP의 성능은 MLM에 비해 좋다는 평가를 받지 못하고, BART에서도 NSP와 직접적인 비교를 하지 않기에 설명을 하지는 않겠습니다.
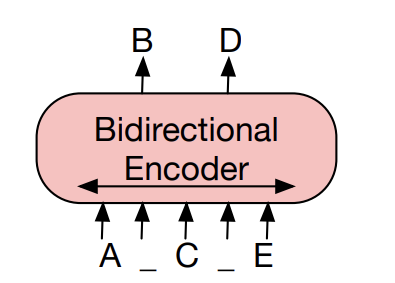
XLNet 논문에 따르면 BERT의 MLM을 식은 다음과 같이 표기할 수 있다고 합니다. 여기서 보이는 X bar는 original text를 의미하고, X hat은 corrupted text 그리고 m_t는 masked index를 의미한다고 합니다. 그래서 BERT는 corrupted text가 original text로 복구하는 확률에 대한 MLE로 학습을 한다고 생각할 수 있습니다. 특이한 점은 저 logp값은 우변 summation값과 근사한다고 물결 표시로 명시가 되어 있는데, 이는 BERT에서 Masked Token을 복구할 때, 각각의 mask token들이 독립적으로 구축이 되기 때문입니다.
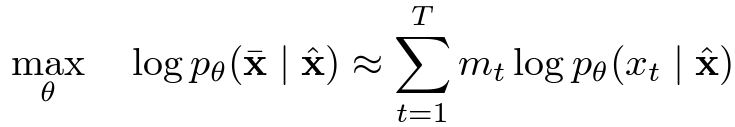
그리고 BERT는 pretrain을 할 때는, [MASK] token이 있지만, finetuning에는 [MASK] token이 없어서 두 가지 학습 방식 사이에 따른 discrependancy 문제가 있습니다.
BART

이번에는 BART에 대해서 한 번 살펴 보겠습니다. GPT에서는 활성 함수로 ReLU를 활용하였지만, BART에서는 BERT와 마찬가지로 ReLU의 변형인 GeLU를 활용하였고, parameter들의 초기 값을 평균이 0이고, 표준편차가 0.02인 정규분포로 두어 설정을 합니다. Base 모델로는 Encoder와 Decoder layer가 각각 6개씩 있는 반면, Large 모델에서는 12개씩 가지고 있습니다.
그리고 BART는 아래 보이는 seq2seq구조를 따르는데, BERT와 다르게 Autoregressive Decoder가 추가되었습니다. BART와 BERT는 동일한 pretrain objective를 갖지만, BART는 모델의 architecture를 개선함으로써 위에서 언급했던 BERT의 단점들을 보완할 수 있습니다.
1) Masked Token을 복구할 때, Autoregressive한 구조를 사용하기에 Mask Token들이 이전 시점의 Mask Token에 영향을 받으므로 독립적인 구축의 문제가 해결 되었습니다.
2) BART는 seq2seq 구조에서 sequential한 original text 자체를 복구하기에 pretrain과 finetuning 사이의 discrependancy가 해소되었습니다. (뇌피셜..)
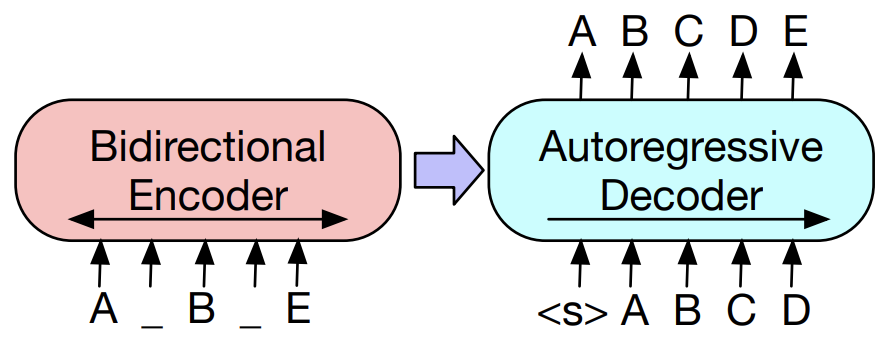
논문에서 언급하는 BART와 BERT의 차이점은 다음과 같습니다.
1) BART는 seq2seq의 구조를 따르기에, BERT와 다르게 Encoder의 마지막 layer와 각각의 Decoder와 cross-attention을 수행합니다. (Transformer의 학습을 생각해 주세요)
2) BERT는 word prediction을 하기 직전에 FFNN을 추가로 삽입을 하지만, BART는 그렇지 않습니다.
3) 모델의 size가 동일하다고 가정하면, BART는 BERT보다 10% 정도 많은 parameters를 가지고 있습니다. (논문에서 모델이 size가 무엇인지 명확하게 언급x)
2.1 Pre-training BART
논문에서는 original text에 noising을 주는데 있어 MLM과 같은 기존의 방법과 새로운 다양한 방법들을 제시하고 있습니다. 여기서 사용되는 변형들 뿐만 아니라 다른 방법도 적용할 수 있다는 점을 말씀드리며 text corruption의 다양한 방법들을 설명 드리겠습니다. 그리고 BART는 original document에 corruption을 주어 입력으로 넣고 나온 Decoder의 ouput과 original document 사이의 Cross Entorpy Loss로 학습이 됩니다.
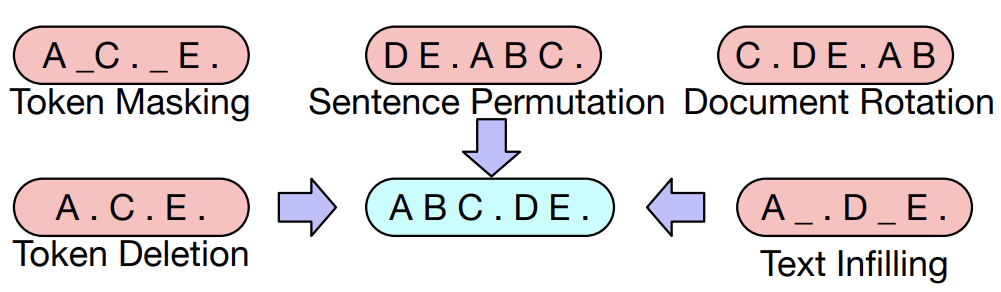
Token Masking
- BERT의 MLM과 동일한 방법으로 random tokens들이 추출되어 [MASK] token으로 대체되는 것입니다.
Token Deletion
- Input으로 들어가는 text에서 random tokens들이 삭제가 되는 것입니다. 위에 [MASK] token을 맞추는 Token Masking과 다르게 이 방법은 어느 위치에서 token이 삭제가 되었는지 맞추는 것이 목적입니다.
Text Infilling
- 먼저 Text Infilling task는 소개되는 5가지 text corruption 방법 중에서 성능이 제일 좋게 나왔고 중요했다고 논문에서 강조하고 있습니다. lambda가 3인 Poisson 분포에서 span length를 추출한 길이 만큼의 text spans을 샘플링하고, 이를 단일 [MASK] token으로 대체합니다. 위의 예시를 보시면 이해가 잘 되실텐데, ABC.DE.라는 두 문장을 보시면, 첫번째 문장은 2만큼의 길이의 span에서 'BC'라는 text span이 샘플링이 되어 단일 [MASK] token으로 대체 되었고, 두번째 문장은 '0'만큼의 길이의 span에서 'empty'라는 text span이 샘플링이 되어 [MASK] token으로 대체가 되었습니다.
여기서 언급하는 span이란 단순히 text의 토큰들을 의미한다고 생각하시면 되는데, 이 span은 labmda가 3인 Poisson 분포를 (평균=분산=lambda) 따르기에 0~6 사이의 span lenght가 뽑힐 확률이 큽니다
논문에서는 Text Infilling 방법은 모델로 하여금 span에서 얼마만큼의 tokens들이 없어졌는지 예측하는 것을 학습한다고 명시했습니다.
추가로 skt에서 발표한 KoBART는 'Text Infilling'만을 사용했다고 알려져 있습니다.
Sentence Permutation
- 이 방법은 단순히 문장간의 순서를 바꾸는 식으로 original data에 noise를 줍니다. 위에 예시를 보시면, 'ABC.DE'라는 original text가 'DE.ABC.'로 바뀐 모습을 볼 수 있죠. 다만 논문에서 언급되기로는 이러한 문장 간의 구분을 단순히 'full stop(마침표)'를 기준으로 하여 구분한다고 명시되어 있던데, 저는 이러한 점이 의아했습니다.
A document is divided into sentences based on full stops, and these sentences are shuffled in a random order.
Document Rotation
- 이 방법은 token들의 나열로 이루어진 text에서 동일한 확률로 랜덤하게 하나의 token을 골라서, 이를 시작점으로 두고 배열하는 것입니다. 예시를 보시면, 'ABC.DE'라는 원본 문장에서, 랜덤하게 'C'라는 token을 임의로 뽑아 이를 시작 점에 배치해두고 'C'앞에 있던 token들은 자연스레 뒤로 가서 바뀐 문장은 'C.DE.AB'가 되겠죠. 논문에서는 이 방법으로 하여금 모델이 document의 시작점을 인지하는 능력을 학습시킨다고 명시했습니다.
3. Fine-tuning BART
3.1 Sequence Classifications Tasks
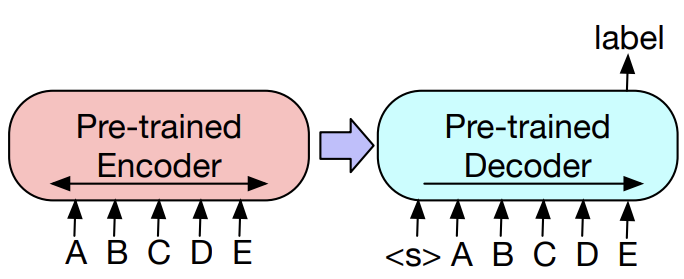
- Input으로 Encoder와 Decoder에 동일하게 완전한 문장이 입력이 되어서, final hidden state of final decoder token이 multi-class linear classifier로 들어가서 문장을 분류합니다. 이는 BERT에서의 special token 중 하나인 CLS token과 비슷하지만, BART는 Decoder의 완전한 input을 참조할 수 있는 문장 마지막에 additiaonl token을 삽입함으로써 (AR 구조이기에 가능) 작동을 합니다.
3.2 Token Classifications Tasks
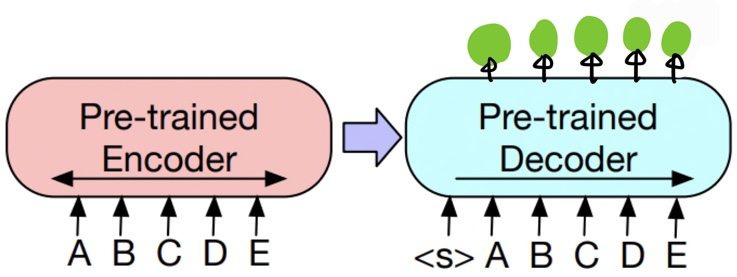
- Sequence Classification Tasks와 동일하게, Input으로 Encoder와 Decoder에 동일하게 완전한 문장이 입력이 되어서 Decoder의 상단의 hidden state가 token 각각의 representaiton이 됩니다. 이렇게 나온 representation이 token을 분류할 수 있습니다.
3.3 Sequence Generation Tasks
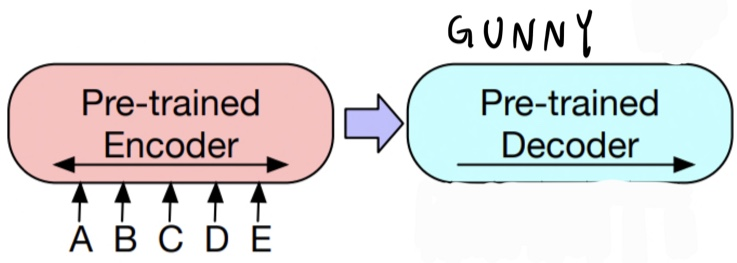
- BART는 sequential text를 생성할 수 있는 AR 특성의 Decoder가 있기에, 바로 abstractive question answering 혹은 abstractive summarization에 대한 fine-tuning을 할 수 있습니다. 여기서 Encoder에는 input sequence가 들어가게 되고, Decoder는 AR하게 output을 출력합니다.
3.4 Machine Tranlsation Tasks
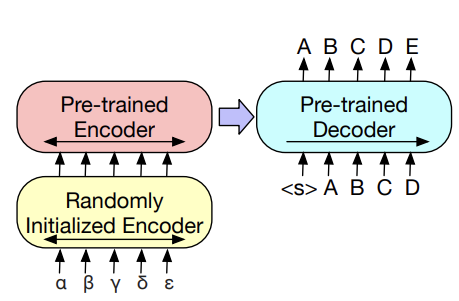
- 보통 (language1)과 (language2)간의 Translation은 noise를 주어 학습하는 경우에서는 학습이 안 된다고 합니다. 그래서 논문에서는 다음의 문제를 개선하기 위해 새로운 방법을 도입한 것인데, 그 점이 additional한 Encoder를 추가하는 것입니다. 왜냐하면 기존에 제가 설명 드렸던 BART 모델은 단일 언어에 대한 text로 학습을 하였기에, 다른 언어의 text가 들어오면 처리할 수가 없습니다. 그래서 새로운 Encoder를 추가해줌으로써 다른 언어의 text 정보를 학습된 언어의 text 정보로 넘겨주어 해결할 수 있습니다.
이해하기 쉽게 (한->영)번역에 대한 예시를 들어보겠습니다. BART라는 모델이 영어에만 학습된 모델이라고 할 때, 위에 그림과 같이 '가,나,다,라,마' 한글 text가 additional Encoder의 input으로 들어오고, 이 한글에 대한 정보를 영어로 바꿔주어 기존의 영어로 학습된 pre-trained Encoder에 넣어주게되고 이는 pre-trained된 Decoder로 넘어가서 영어에 대한 output을 출력할 수 있습니다.
이 additional Encoder를 학습 할 때는 두가지 단계로 학습이 진행됩니다.
1) BART의 대부분의 parameters를 freeze하고 randomly initialized한 additional Encoder의 parameters들을 학습합니다.
2) 적은 iteration 만큼의 횟수로 모델의 모든 parameter를 학습합니다.
4. Comparing pre-training objectives
Base-size model을 기준으로 여러 task에 대한 실험을 통해 pretraining objective를 비교해보겠습니다. Base-size model은 6개의 Encoder와 Decoder, 그리고 hidden state를 768차원으로 설정한 모델입니다. 이제 제가 비교할 Pretraining objective들은 다음과 같습니다.
4.1 Pre-training objectives
- Language Model
- GPT와 비슷한 left-to-right LM입니다. 이는 BART에서 cross-attention을 제거한 Decoder 부분이라고 생각하셔도 됩니다. - Permuted Language Model
- XLNet을 기반으로 1/6 tokens을 샘플링하고 AR방식으로 생성합니다. (다른 모델과 비교를 하기 위해 relative positional embedding이나 attention across segments는 적용하지 않았습니다.) - Masked Language Model
- BERT와 동일하게 15% tokens을 [MASK]로 바꿔 독립적으로 원래의 token을 예측하는 방식으로 학습합니다. - Multi Masked Language Model
- UniLM과 같이 MLM에 additional self-attention masks를 추가하며 학습을 합니다. - Masked Seq-to-Seq
- MASS와 같이 50%의 tokens을 masking하고 masked token을 맞추는 seq2seq모델을 학습합니다.
4.2 Tasks
-
SQUAD
- wikipedia에서 extractive question answering task. Input으로 question과 answer를 concat하여 Encoder에 삽입하고 Decoder로 전달. -
MNLI
- fine-tuned model은 [EOS] token을 추가된 두개의 문장을 연결하고, BART encoder-decoder로 전달함. [EOS] token이 문장간의 관계를 구분하는데 사용됨. -
ELI5
- long-form abstractive question-answering dataset -
XSum
- Abstractive news summarization dataset -
ConvAI2
- context와 persona를 기반으로 Dialogue 응답 생성 task
persona: "개인이 사회생활 속에서 사람들로부터 비난받지 않기 위해 겉으로 드러내는, 자신의 본성과는 다른 태도나 성격. 사회의 규범과 관습을 내면화한 것임." -
CNN/DM
- News summarization dataset
4.3 Results
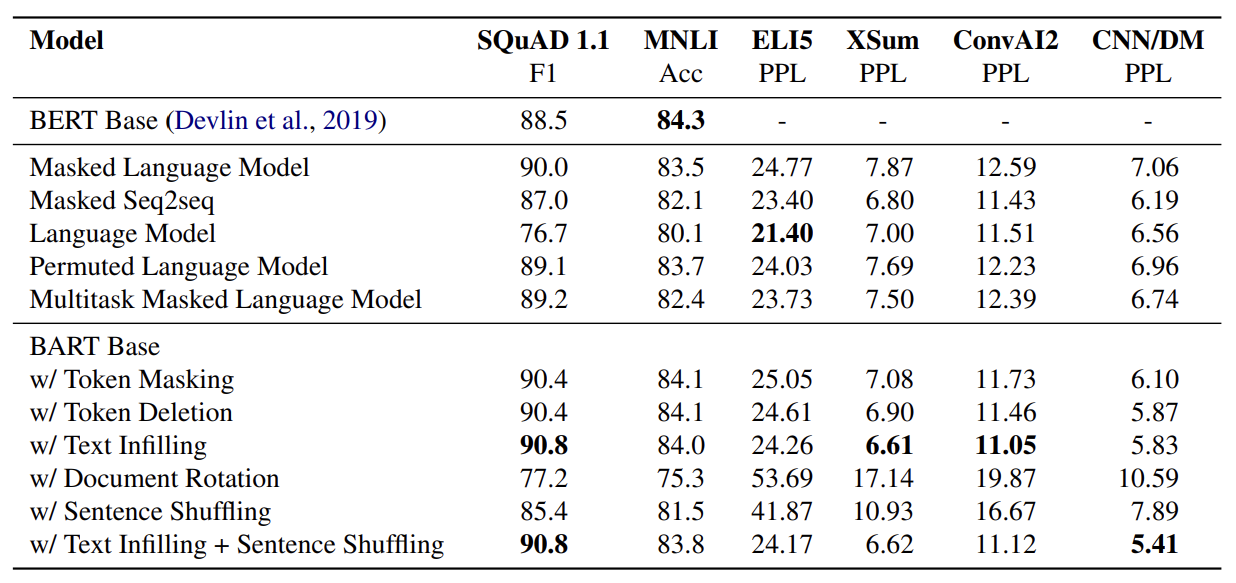
실험에 대한 결과는 다음과 같습니다. 모든 모델들은 1M steps 만큼 books과 Wikipedia dataset에 대해 학습이 되었습니다. 첫번째로 구분되는 칸은 BERT base 모델의 성능을 나타내고, 두번째 칸은 pre-trianed objective에 따른 모델의 성능을 보여주고, 마지막 칸은 BART 모델에서 document corruption을 앞서 설명드린 5가지 방법과 조합에 있어 성능을 보여줍니다. 보시면 아시다시피, BART with Text Infilling이 대체적으로 성능이 제일 좋은 것을 볼 수 있습니다.
추가로 논문에서 설명하고 있는 결과에 대한 해석은
1) Performance of pre-training methods varies significantly across tasks
- LM 모델이 ELI5에서 best지만, SQuAD에서는 worst입니다. (두 번째 칸 3번째)
2) Token masking is crucial
- Rotating document와 permuting sentence는 성능이 낮습니다. (세 번째 칸 4,5번째)
3) Left-to-right pre-training improves generation
- MLM과 PLM 모델은 생성 task에서 성능이 낮음을 보입니다. (AR방식 사용x / 두 번째 칸 1,4번째)
4) Bidirectional encoders are crucial for SQuAD (두 번째 칸 3번째)
- 단순 left-to-right decoder는 SQuAD에서 성능이 낮지만, BART는 그렇지 않습니다.
5) The pre-training objective is not the only important factor (두 번째 칸 4번째)
- 논문에서 직접 만든 PLM은 실제 근간이 되었던, XLNet과 pre-training objective는 같지만 이 보다는 성능이 낮습니다. relative-position embedding이나 segment-level recurrence와 같은 추가적인 것을 고려하지 않았기 때문이죠.
6) Pure language models perform best on ELI5
- 유일하게 다른 pre-trained obejctive들의 성능이 BART 모델보다 좋습니다.
7) BART achieves the most consistently strong performance.
- ELI5 task를 제외하고는 BART의 모델이 제일 좋습니다. 특히, BART에 Text Infliing만 적용한 것이 제일 좋습니다.
5. Large-scale pre-training Experiments
여기 실험에서는, 12개의 Encoder와 Decoder를 사용하고 hidden state의 차원은 1024로 설정합니다. RoBERTa와 비슷하게 Batch size는 8000번 그리고 Training steps은 500000번으로 설정해둡니다. Tokenizing 방식은 BPE를 따르고, 사용한 document corruption 기법은 Text Infilling과 Sentence Shuffling 두가지 방식을 합친 것을 사용합니다. 위에 실험에서는 단순히 Text Infilling만을 사용한 것이 성능이 좋았지만, 본 논문에서는 large scale 단위로 가게 되면 sentence shuffling이 잘 학습할 수 있다는 가설을 두었기 때문입니다. 추가로 모델이 data에 잘 fitting이 될 수 있게끔, training step에서 마지막 10%는 dropout을 사용하지 않고 후반부 학습에서는 underfitting을 방지하고자 overfitting을 실현하고자 하는 모습이 보입니다.
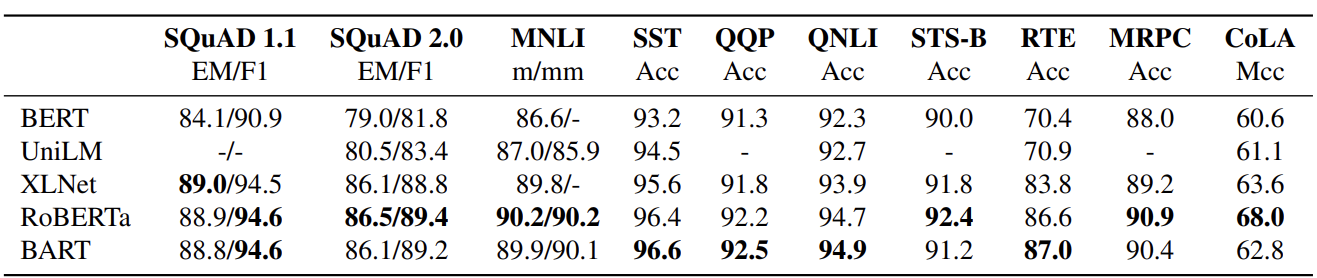
5.1 Discriminative Tasks
다음은 SQuAD와 GLUE tasks에 대한 실험 결과입니다. RoBERTa와 BART를 비교해보시면, 성능의 차이가 비슷하다는 것을 보여줍니다.
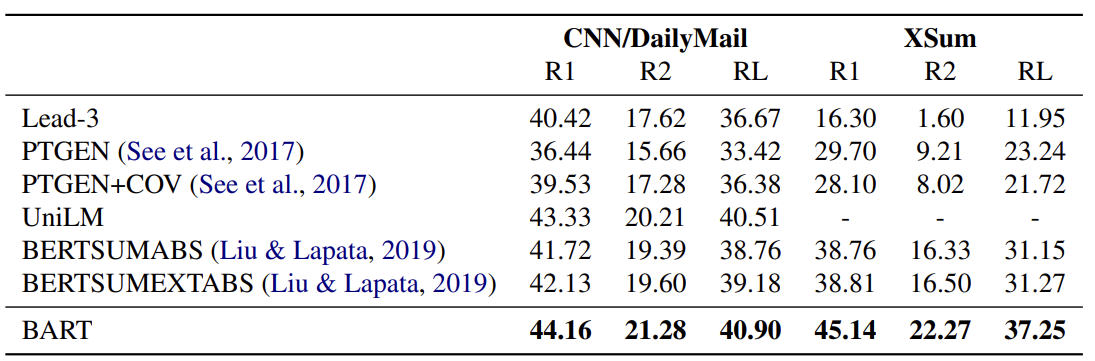
5.2 Generation Tasks
다음은 두개의 summarization dataset에 대한 요약 생성의 성능을 보여줍니다. CNN/DailyMail dataset같은 경우에는 easy problem으로 볼 수 있고, XSum dataset은 hard problem으로 볼 수 있습니다. 그래서 맨 앞에 3문장을 추출하는 Lead-3의 성능을 보시면, 전자의 task에서는 높은 성능을 보인 반면에 후자의 task에서는 성능이 매우 낮음을 보입니다. 그리고 본 논문에서 소개되는 BART는 모든 task에서 모든 평가지표 (rouge의 R1,R2,RL)에서 최고의 성능을 보이는 것을 확인 할 수 있습니다.
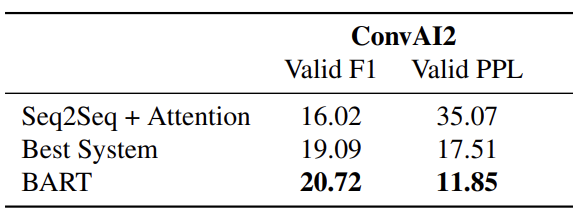
다음은 dialogue response generation에서 BART가 역시나도 높은 성능을 보이는 것을 확인할 수 있습니다.
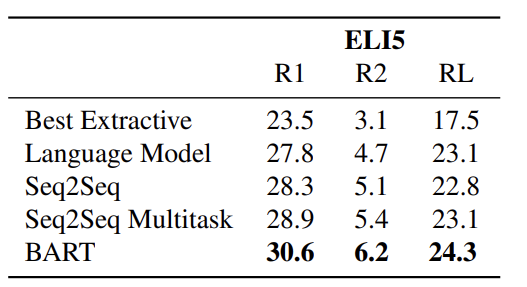
ELI5 dataset의 abstarctive AQ task에서도 역시 최고의 성능을 보이는 것은 BART입니다.
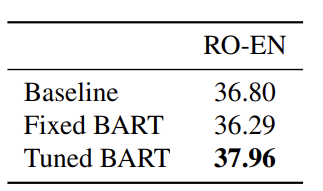
하지만 BART는 Machine Translation task에서는 괄목할 만한 성능의 향상을 볼 수 없음을 확인 할 수 있습니다. 이는 아마 MT task에서 fine-tuning시에 additional encoder를 학습 할 때, 문제가 있는 것 같습니다 (뇌피셜입니다...)
Conclusion
BART는 RoBERTa와 비슷한 수준의 성능을 discriminative tasks에서 보였을 뿐만 아니라, 수 많은 generation tasks에서 State-of-the-art를 달성한 것으로 보아 감히 혁신적인 모델이라고 생각합니다!
Reference
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension Mike Lewis, Yinhan Liu, Naman Goyal*, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer
https://www.youtube.com/watch?v=VmYMnpDLPEo
