DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings

오늘은 2022년 4월 NACCL 학회에 투고가 된 따끈따끈한 논문 리뷰를 준비해봤습니다.
제가 준비한 리뷰 순서도 논문의 구성 순서와 비슷하게 준비했습니다.
Introduction
먼저 최근에 자연어처리 연구에서 ‘Universal‘한 문장 표현이 중요한 연구 주제로 떠오르고 있습니다. 최근 연구들은 주로 PLM을 Fine-tuning할 때, contrastive learning을 적용하며 문장 embedding의 성능을 올리는 것이 시도되고 있습니다. Contrastive learning이란 밑에 보이는 그림과 같이 주로 Computer Vision에서 자주 쓰이는 개념인데, 동일한 이미지에 대해 augmentation을 적용한 객체들은 positive pair로써 가까이하고, 다른 이미지에 대해서는 negative pair로써 멀리하며 학습하는 개념입니다. 즉, contrastive learning은 대상들의 차이를 좀 더 명확하게 보여줄 수 있도록 학습하는 뜻입니다.

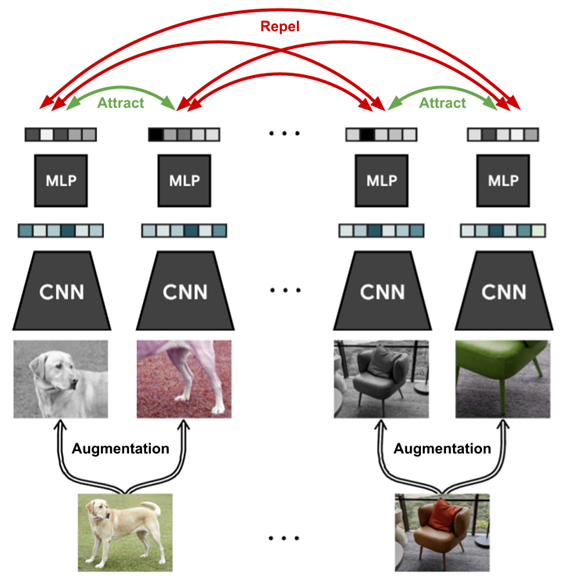
하지만 이와 같은 개념은 컴퓨터 비전뿐만 아니라, 2013년에 자연어처리 분야에서도 word2vec이 소개될 때 이미 나왔던 개념입니다. Word2vec에서는 contrastive learning의 워딩을 직접적으로 사용하지는 않았지만, word2vec에서 적용되는 negative sampling의 개념은 중심 단어와 멀리 있는 단어 (즉, 관련이 없는 단어에 대해서는 유사하지 않다는 방향으로 학습하며) contrastive learnin과 비슷한 개념을 가지고 있습니다. 아래 word2vec의 objective function을 확인해보시면 두 번째 항에서 negative sampling을 통해서 center word와 negative sample간의 유사도를 낮추는 식으로 명시되어 있는 것을 확인할 수 있습니다.
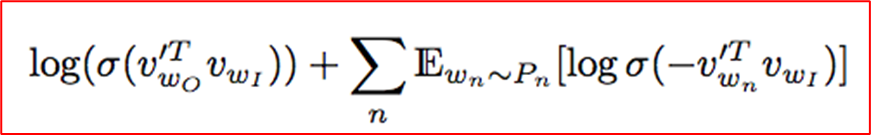
금일 제가 소개 드리는 논문에서도, contrastive learning을 활용한 비지도 학습 방식의 문장 표현을 학습하는 방법인 DiffCSE에 대해 설명드리겠습니다.

먼저, 문장 임베딩을 표현하는 방법 중 널리 알려져있는 방법을 소개 드리겠습니다. 트랜스포머 기반 모델을 활용하여 문장 임베딩을 표현할 때, 첫째로, 아래 좌측에 보이는 BERT는 주로 [CLS] 토큰 혹은 마지막 layer의 출력 벡터에 대해 average pooling값을 기준으로 문장을 표현합니다. 우측 하단에 보이는 SBERT는 BERT를 SNLI dataset에 대해 finetuning을 한 모델로 Siamese network와 triplet loss를 활용해 BERT를 개선한 모델입니다.
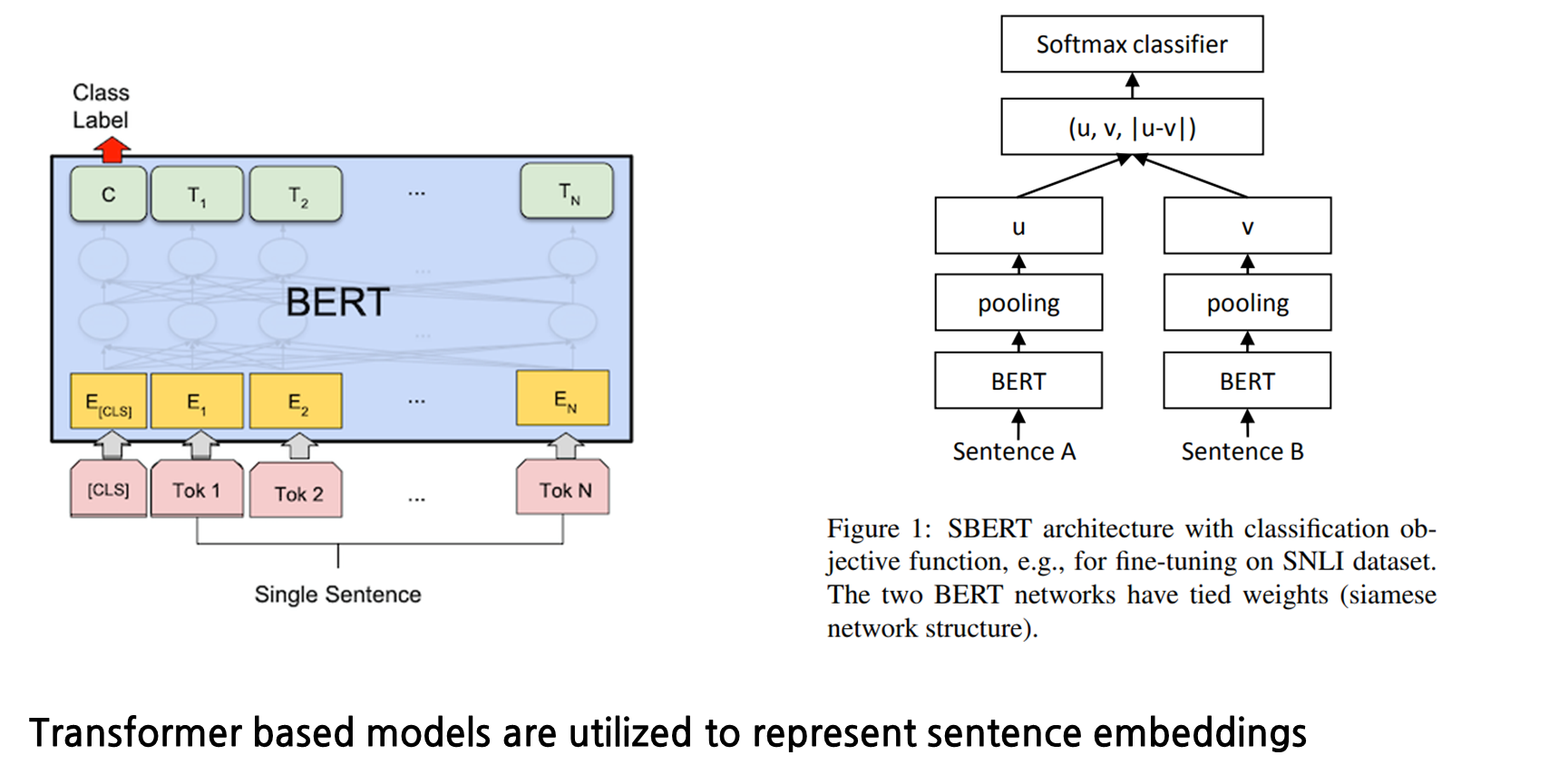
그러면 처음 설명한 contrastive learning 개념이 앞에 BERT/ SBERT와 같이 문장 임베딩을 표현하는 것에 있어 어떻게 적용이 될까요?

Background
Learning Sentence Embeddings
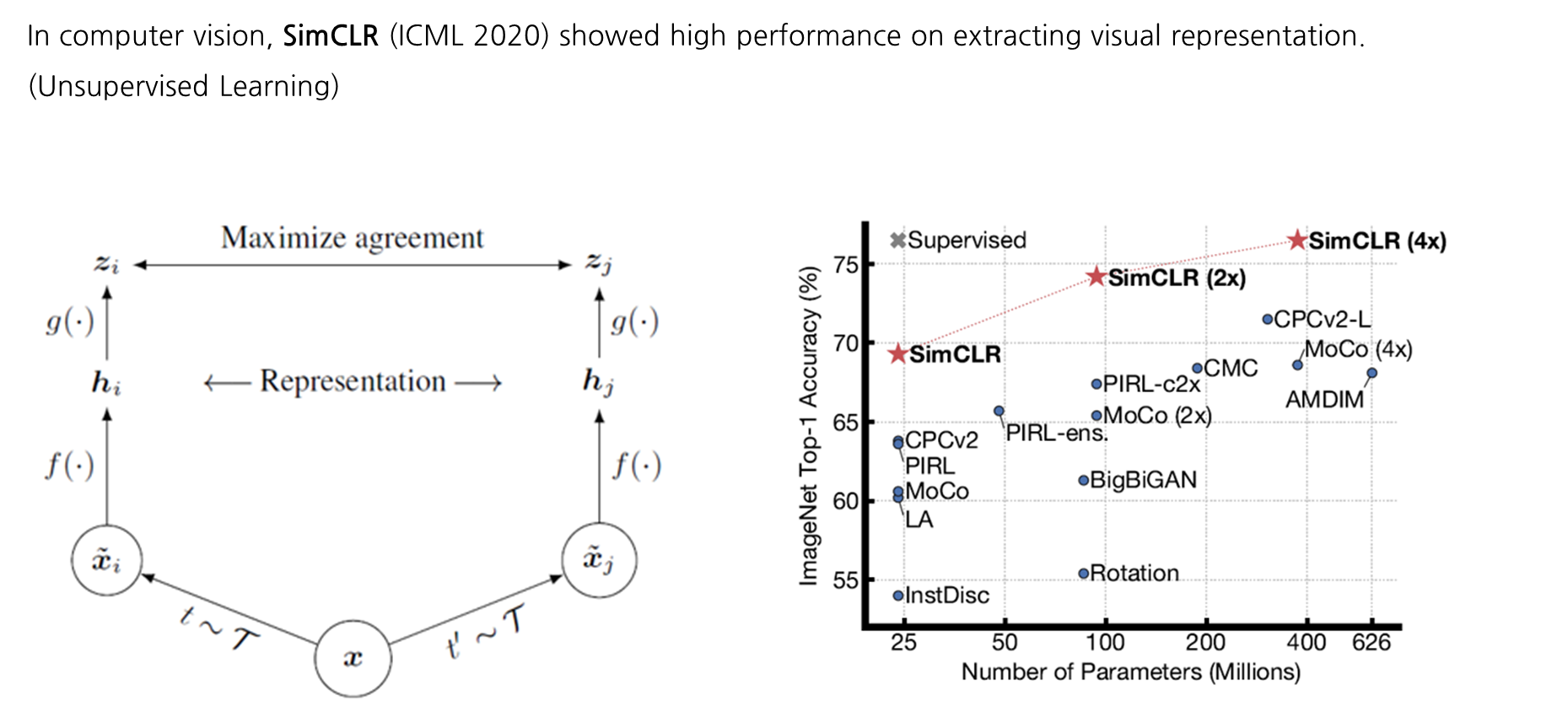
이는 2020년 ICML에 소개된 Computer Vision 분야인 SimCLR 논문을 먼저 알고 있으면 해당 내용을 이해하는데 있어 수월할 것입니다. 처음 장표에서 보여드린 강아지/의자 사진에서 동일 사진에 대한 객체는 positive pair로 묶고 다른 객체들은 negative pair로 처리하며 학습한 사진은 여기 SimCLR의 학습 방식을 나타낸 것입니다. 여기 좌측에 보이는 그림도 x라는 객체에 대해 각각의 augmentation을 취한 뒤 특정 함수를 통해 나온 벡터 값에 대한 유사성이 높다고 여기는 것이 positive pair로 묶이는 과정의 그림입니다. 이런 식으로 CV분야에서는 contrastive learning을 통해 이미지 표현에 있어 엄청난 성능 향상을 보였습니다.
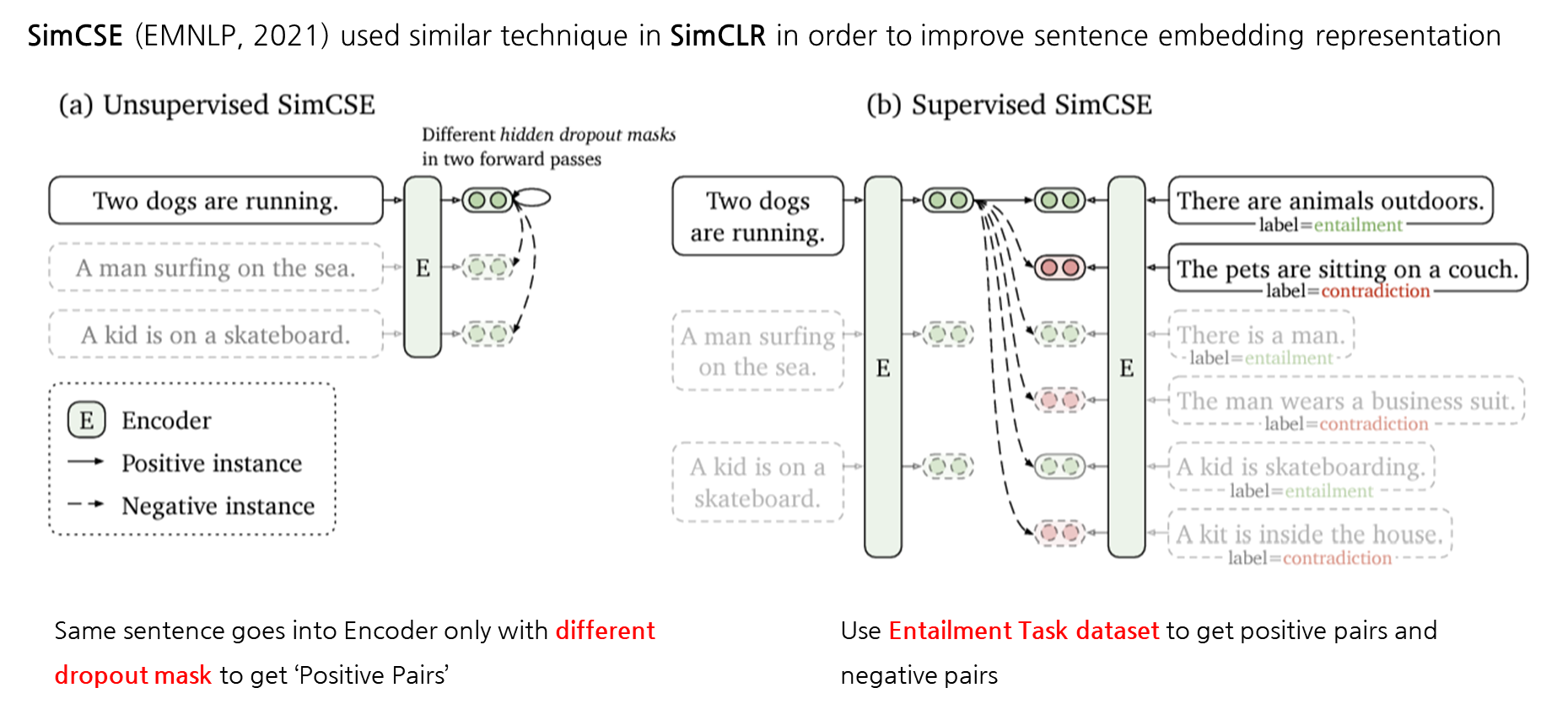
2021년 EMNLP에서 소개된 SimCSE도 SimCLR와 비슷한 방식으로 contrastive learning을 활용하며 문장 embedding 표현의 성능을 올렸습니다. SimCSE에는 크게 비지도학습/지도학습 방식 기반으로 두가지 방법이 소개가 됩니다. 여기서 동일 문장에 대한 augmentation은 저희가 주로 알고 있는 deletion, insertion, substitution 등을 활용하지 않고 Encoder에서 dropout mask를 다르게 적용시키며 positive pair를 만들었습니다. 여기서 negative pair로는 같은 batch size 내에 있는 다른 문장으로 가정하며 contrastive learning을 학습했습니다. 두번째로 소개되는 학습 방식은 지도학습 기반으로 학습되는 SimCSE인데, 이는 NLI dataset을 활용하며 모델을 학습시켰습니다. Dataset에서 premise 문장과 Entailment로 되어 있는 label은 positive pair, contradiction로 지정 되어있는 label은 negative pair로 가정하며 contrastive learning을 학습했습니다.
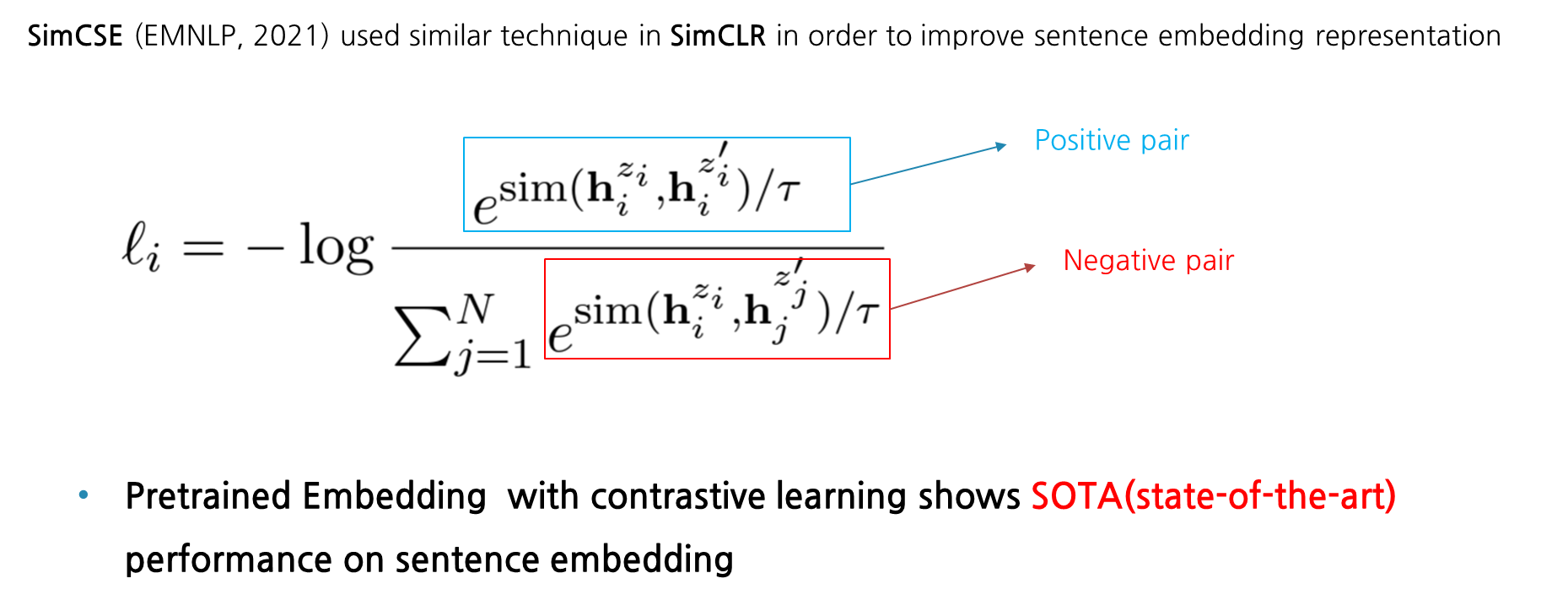
다음은 SimCSE의 loss function인데, 분자 term을 보시면 특정 문장의 hidden vector를 hi라고 볼 때, 이에 대한 문장표현을 hi의 zi라 보고 이에 대한 augmentation을 취한 것은 hi의 zi프라임으로 볼 수 있습니다. 그래서 해당 positive pair의 유사도는 maximize 방향으로 학습이 됩니다. 반대로 분모 term을 보면 N개의 batch중 다른 문장들에 대한 negative pair의 유사도는 낮추는 방식으로 학습이 되는 것을 볼 수 있습니다. 이렇게 간단한 아이디어를 통해서 SimCSE는 pretrained model에 contrastive learning 개념을 접목시켜 문장 임베딩 부문에서 SOTA 성적을 보였습니다.
Equivariant Contrastive Learning
SimCSE에서 dropout을 다르게 적용시킨 것과 비슷하게, contrastive learning에서 input의 transformation의 역할을 이해하는 것은 매우 중요합니다. Contrastive Learning은 이러한 transformation들로 부터 하여금 문장의 표현이 insensitive하게 되도록 만들어줍니다. 하지만 SiMCSE에 따르면, MLM과 같은 transformation은 STS-B task에서 모델의 성능을 떨어트렸기 때문에 다음과 같은 transformation을 contrastive learning에 적용하는 것은 적절하지 않다고 판단했습니다. 따라서 MLM과 같은 transformation은 contrastive pre-training에 사용하지 않았다고 언급했습니다. 하지만 DiffCSE는 MLM 기반의 transformation이 문장 표현에 sensitivie하게 적용이 되어도 해당 transformation을 학습하는데 있어 사용합니다. 이 점이 기존 문장 임베딩에서 SOTA 방법이었던 SimCSE와 DiffCSE가 다른 점입니다. 따라서, DiffCSE는 CV 분야에서 자주 사용되는 equivariant contrastive learning 방식의 학습 방법을 사용하며, 즉 transformation에 따라 표현이 insensitive 혹은 sensitive 하게 반응하는 것을 다 고려하며 학습하는 방법을 설계했습니다.
여기서 말하는 Equivariant Contrastive Learning가 무엇인지 구체적으로 설명을 드리겠습니다. 해당 수식에서 보이는 notation을 간단하게 설명을 드리면, T를 group G로부터 나오는 transformation이라고 보고, x라는 문장이 있을 때, T(x)는 x가 transformation을 거친 문장이라고 볼 수 있습니다. 그래서 여기서 알 수 있는 equivariance의 성질은 output feature에 대해서 동일한 값을 취해줄 수 있는 transformation인 T’이라고 볼 수 있습니다. 하지만 T’이 identity transformation이 되는 이러한 케이스는 contrastive learning에서 특수한 케이스라고 볼 수 있습니다. 여기서 T’이 identity transformation으로써, f라는 인코더는 T에 있어 invariant (불변하다는)하게 학습이 된다는 것은 많은 경우 중 하나라고 보는 것입니다. 이와 같은 상황 말고도 T’이 dropout과 같은 transformation에서 identity 성질을 갖고 MLM과 같은 transformation에 identity 성질을 갖지 않는 objective에도 확장을 시켜 적용할 수 있습니다. 이런 식으로 equivariant contrastive learning의 개념을 generalizing 함을 통해 CV에서 feature의 semantic한 quality를 향상시켰다는 것을 보였고, 이번에 소개하는 DiffCSE 모델도 이러한 개념을 NLP에서 처음으로 적용했습니다.
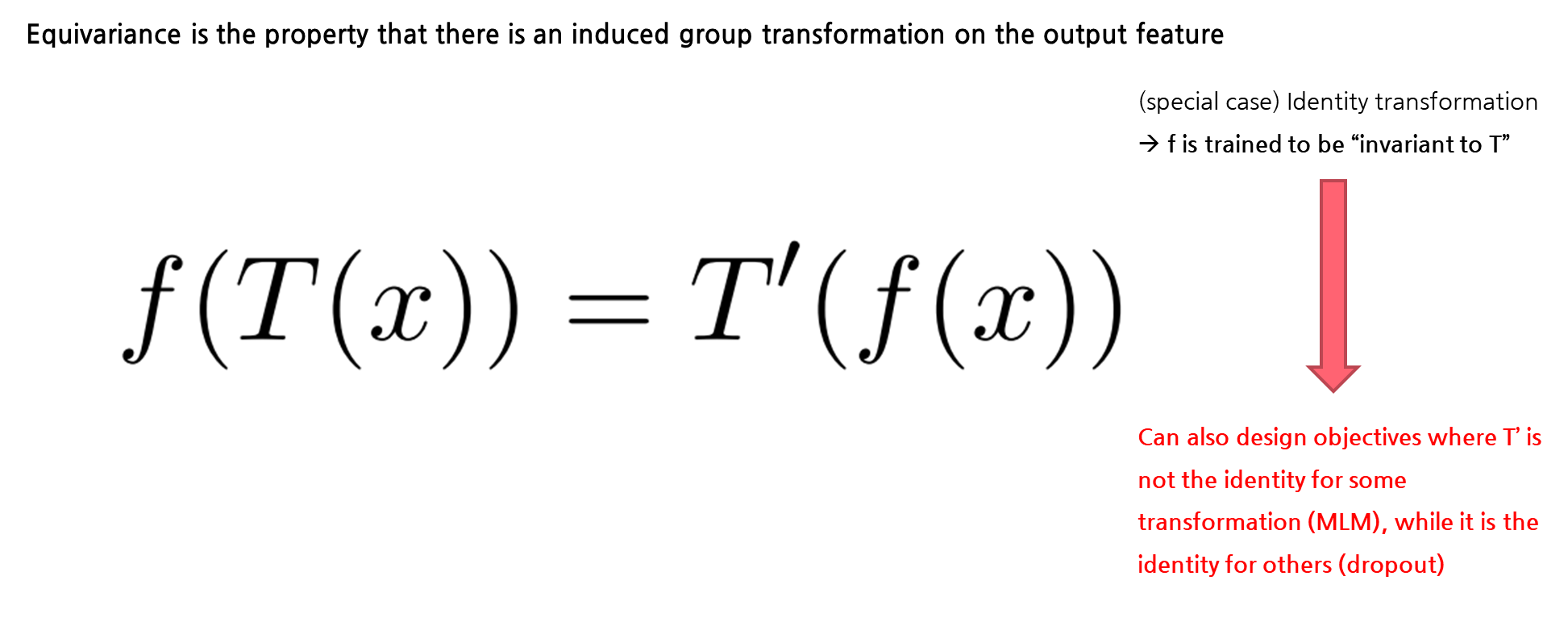
해당 equivariant contrastive learning이 어떻게 DiffCSE에 적용되었는지 설명을 드리겠습니다. 먼저 DiffCSE에서 사용되는 Encoder는 invariant하는 것이 아니고 MLM-based augmentation과 equivariant를 이뤄야합니다. 즉, 단순히 동일한 Encdoer를 사용하여 equivariant를 성립하게 하는 것이 아니라, 조금 더 general하게 Encoder를 사용해서 equivariant를 만족시켰다고 이해하시면 될 것 같습니다. 이와 같이 MLM 기반의 augmentation을 Encoder에 적용하기 위해서는, Conditional한 Discriminator를 활용하면 됩니다. 다들 아시다시피 ELECTRA는 Generator와 Discriminator로 이루어져있는데, 여기 본래 ELECTRA의 Discriminator를 conditional한 Discriminator로 살짝 변형시켜주면 MLM에 equivariant한 encoder를 학습할 수 있습니다. 여기서 설명드리는 condition이란 여기서 사용되는 Electra와 독립적으로 구축된 encoder로부터 나온 sentence embedding의 hidden vector를 discriminator의 입력으로 넣어주는 것이라고 이해하면 될 것 같습니다.
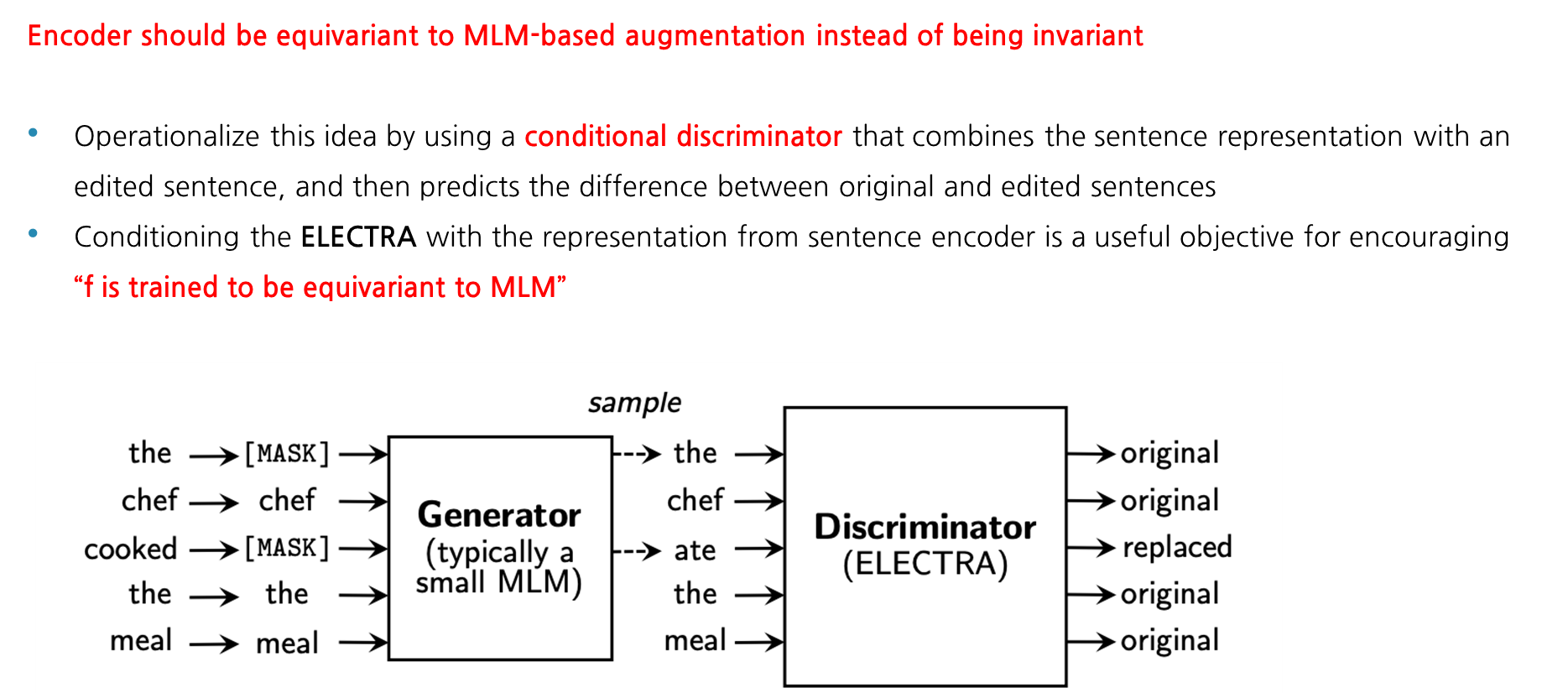
DiffCSE
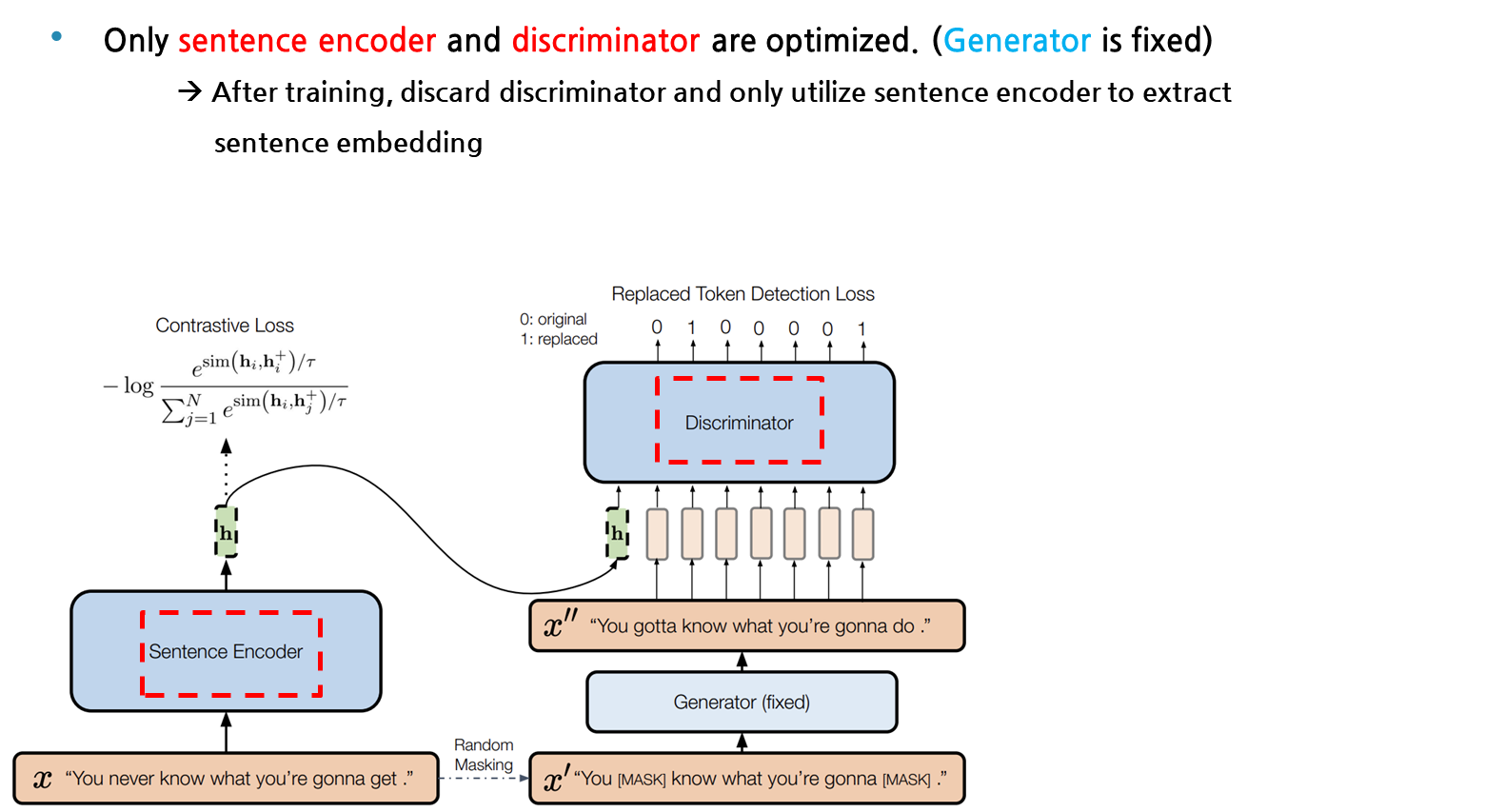
앞에 설명드린 DiffCSE의 특징들을 종합하여 모델의 구조를 설명드리겠습니다. 먼저 SimCSE와 동일하게 x라는 input sentence가 주어지면, 이를 sentence encode에 태워 contrastive learning을 목적함수로 두고 학습을 합니다. 앞에서 설명드린 바와 같이, x문장에 동일한 인코더에 dropout mask만 다르게 적용하여 나온 hidden vector를 positive pair로 두고, N크기만큼의 배치에서 다른 문장들간의 관계를 negative pair로 두며 학습을 하는 것입니다. 우측에 보이는 아키택쳐는 원래 Electra와 거의 동일하다고 보면 되는데, 여기서 SimCSE 구조에서 나온 hidden vector가 Discriminator의 condition으로 들어간다는 점만 다르다고 보시면 될 것 같습니다.
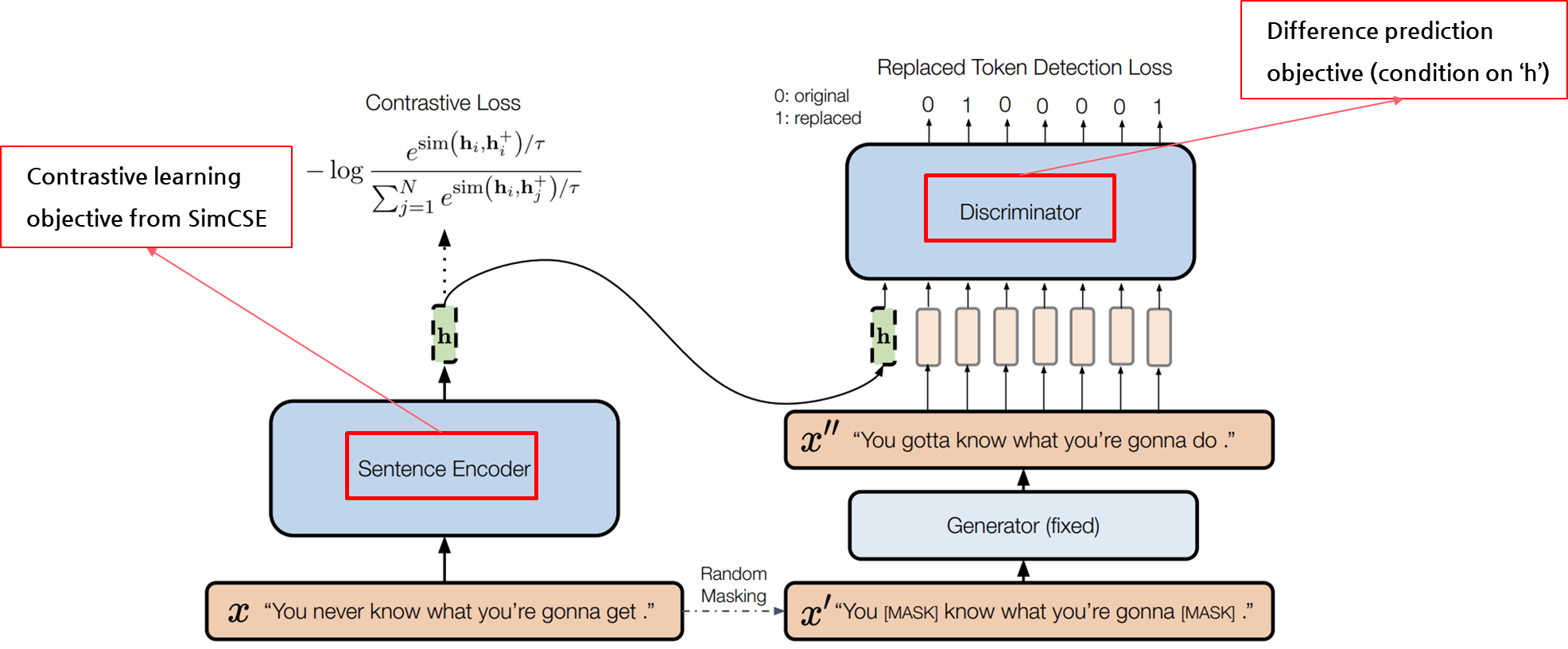
Discriminator 부분에 대해 좀 더 자세하게 설명을 드리겠습니다. Original Input x가 있을 때, 15% masking ratio로 토큰에 마스크처리를 해준 뒤에 Generator를 통과하여 마스킹 된 문장을 생성해줍니다. 이에 대한 결과를 SimCSE의 output hidden vector를 condition으로 걸어 Discriminator에 함께 입력으로 넣어주면, Discriminator는 Replaced Token Detection을 objective로 삼아 학습을 하게 됩니다. RTD는 단순히 cross-entropy loss를 갖고 학습을 시키고, DiffCSE는 본래의 ELECTRA와 다르게 generator는 freeze시키고 오직 discriminator만 학습을 시킵니다.
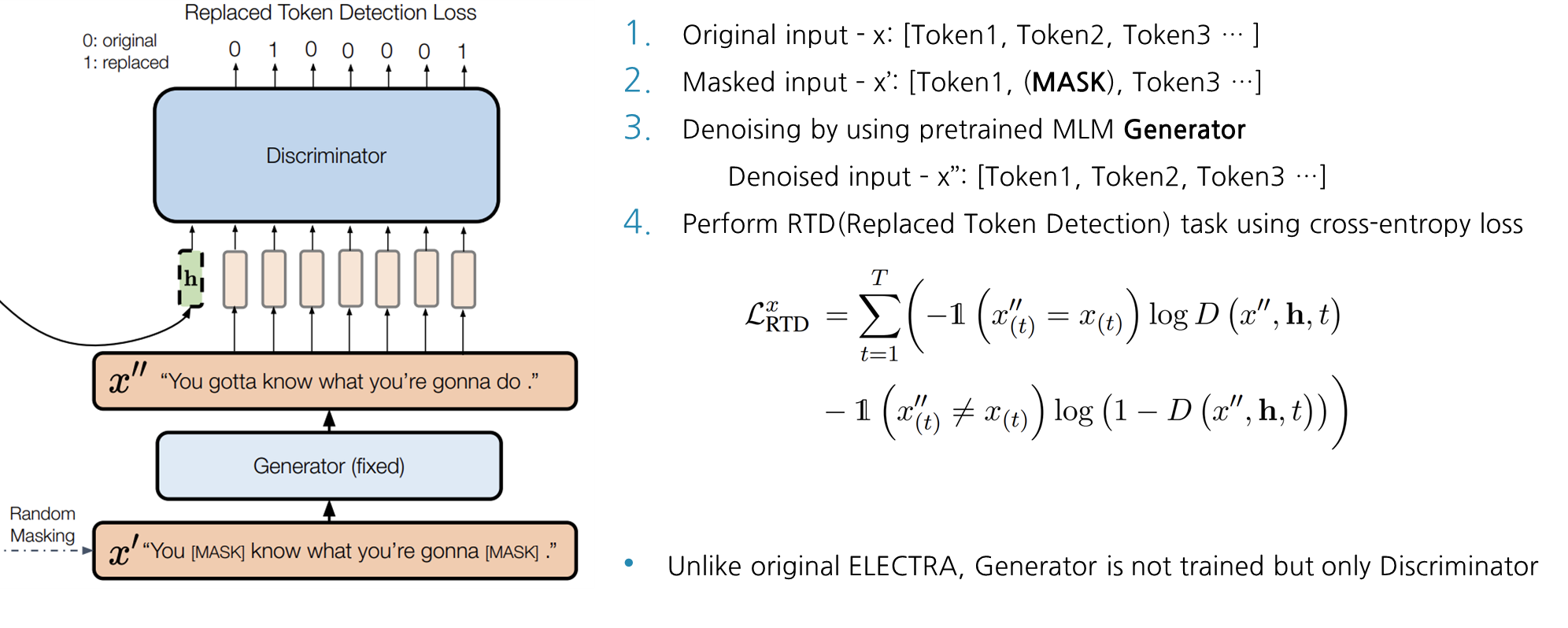
즉, 다시 말해 DiffCSE는 sentence encoder에서 나온 contrastive learning loss와 conditional한 Discriminator에서의 RTD loss 결합하여 total loss를 정의합니다.

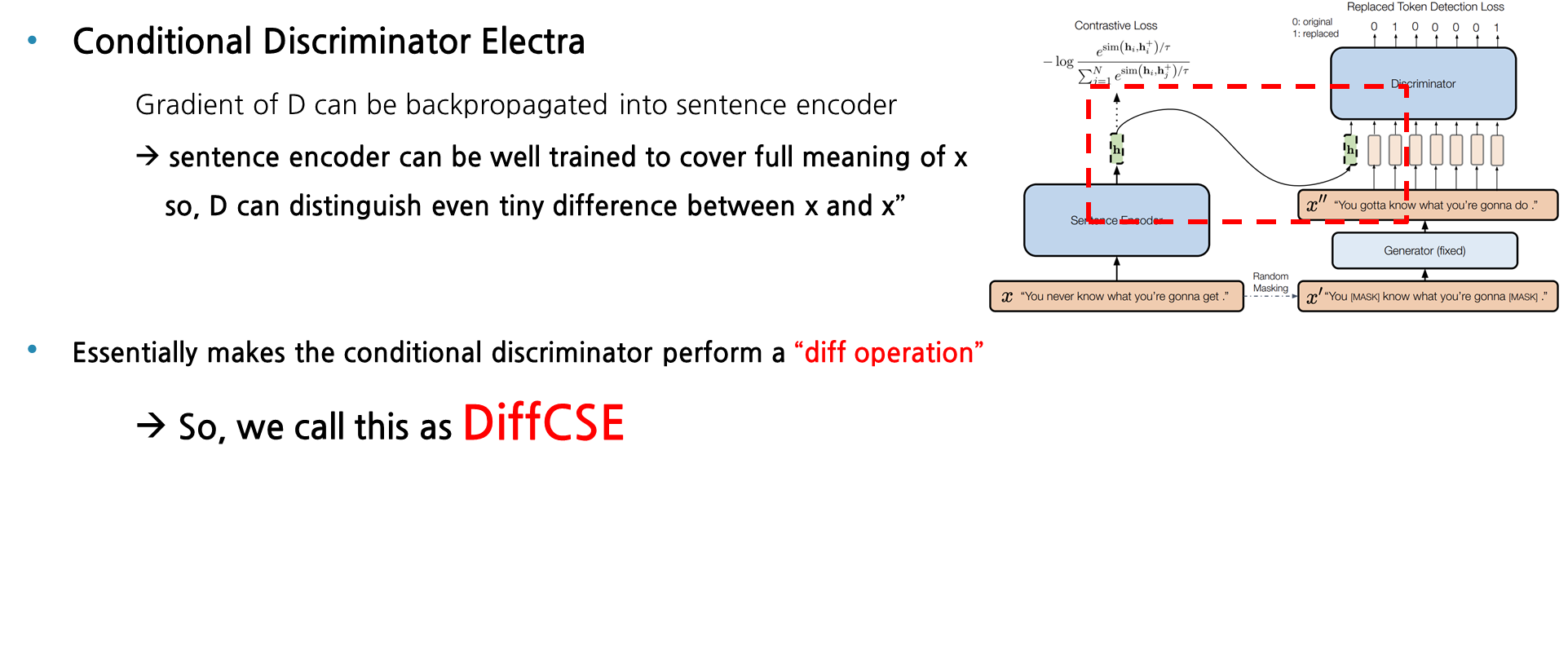
앞에 장표에서 말씀드린 대로 sentence encoder의 hidden vector도 discriminator의 입력으로 들어가기 때문에, 역전파 학습시에 Discriminator에서의 gradient도 sentence encoder로 흘러집니다. 그래서 sentence encoder는 x라는 본래 문장의 의미를 담는 방향으로 더욱 잘 학습을 할 수 있고, discriminator 역시 본래 문장 x와 generator에서 생성된 x’’의 사소한 차이도 구분할 수 있도록 학습이 됩니다. 그래서 이러한 conditional discriminator는 Diff operation을 수행한다고 볼 수 있어, 해당 모델의 이름 DiffCSE로 지어졌습니다.
다들 눈치를 채셨겠지만, 학습시에는 DiffCSE는 sentence encoder와 discriminator만 optimizing을 하고 generator는 freeze를 시켜 학습을 하지 않습니다. 학습 후에 테스트하는 과정에서, discriminator 부분을 버리고 오직 문장 임베딩을 뽑는 용도로 학습된 sentence encoder만을 활용합니다.
Experiments
이번에는 해당 DiffCSE 모델을 실험에 어떻게 활용했는지에 대해 설명을 드리겠습니다. 이번 실험에서는 지도학습 방식이 아닌 비지도학습 방식으로 모델을 설계를 했고, sentence encoder의 weigh를 PLM BERT/RoBERTa의 checkpoint로 활용했습니다. 여기서 sentence encode의 CLS 토큰 위에 MLP layer를 쌓아주고, 나온 벡터 값을 hidden vector로 설정했음을 먼저 아시면 되겠습니다. 추가로 Discriminator 부분에서는 sentence encode와 동일한 encode를 사용하였고, generator는 이보다 더 작은 인코더로 설정했습니다.

Results
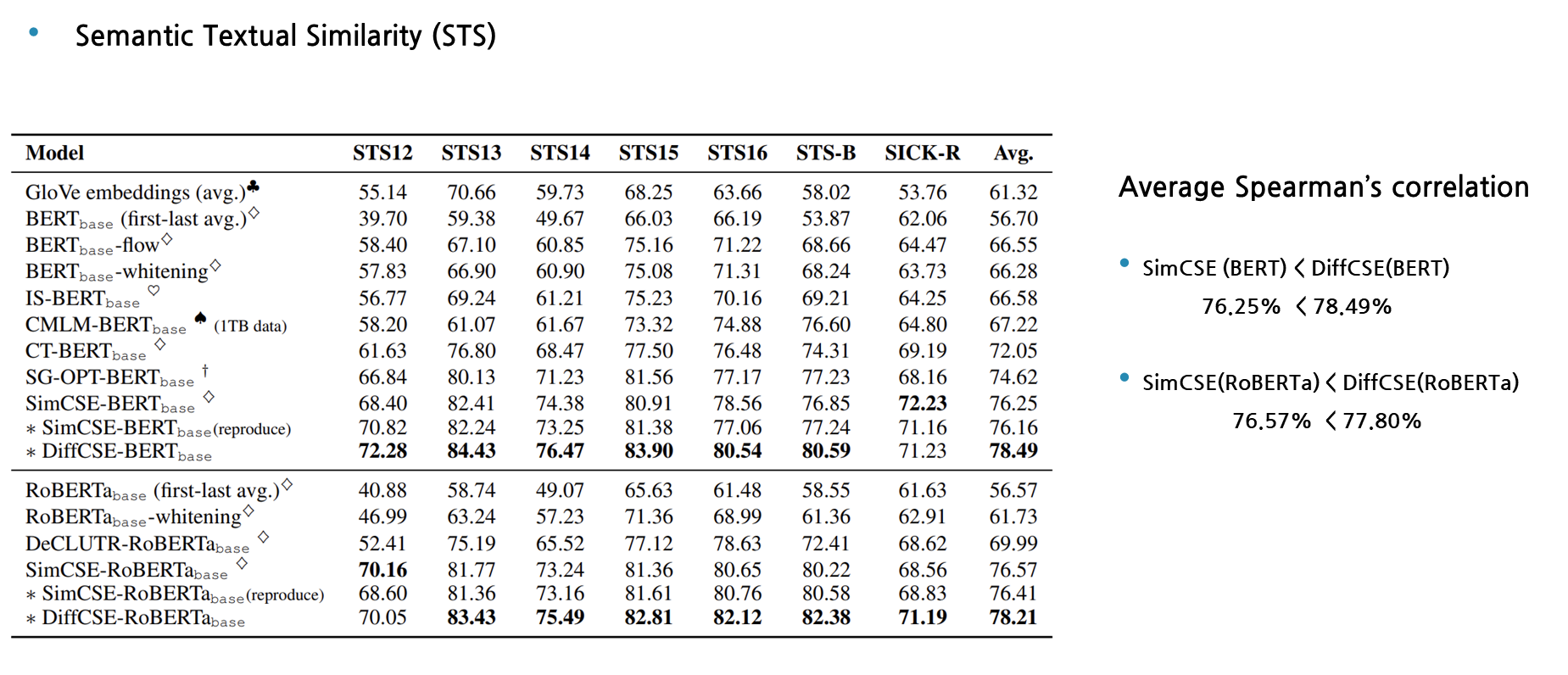
먼저 첫번째 실험 결과를 보겠습니다. Metric을 Spearman’s correlation 평균값으로 두고 봤을 때, Semantic Textual Similiarty task에서 DiffCSE가 기존의 SOTA였던 SimCSE보다 성능의 개선이 되었음을 확인할 수 있습니다.
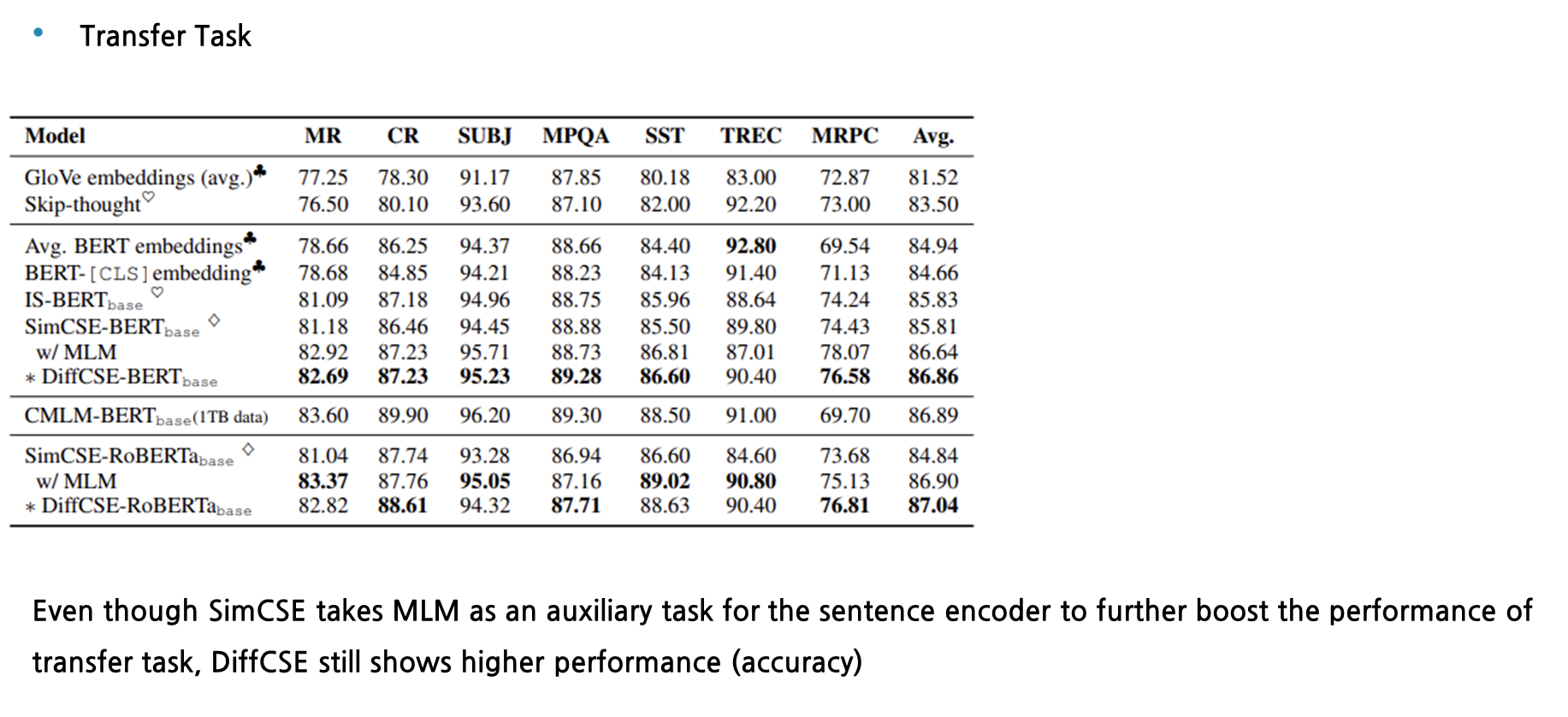
다음 실험은 transfer task에 대한 결과입니다. SimCSE가 MLM objective function을 auxiliary task로 추가하여 기존에 소개된 성능보다 향상이 되었음에도 불구하고, transfer task에서도 accuracy 기준으로 DiffCSE가 더 높은 성능을 보입니다.
Ablation Studies
다음은 DiffCSE가 수행한 다양한 Ablation study에 대해 설명 드리겠습니다. 먼저 DiffCSE에서 Contrastive Loss 부분을 제거하면, STS와 transfer task 둘 다에서 성능 저하가 떨어지는 것으로 보아, Objective function으로 Contrastive Loss와 RTD loss가 둘 다 필요하다는 것을 알 수 있습니다. 당연한 얘기지만, 여기서 RTD loss를 제거하게되면 SimCSE의 구조와 완전히 동일하게 됩니다. 두번째 ablation 실험은, conditional discriminator에 same sentence hidden vector가 아닌 next sentence의 hidden vector를 condition으로 걸어주었을 때, 어떻게 되는지 확인해봤습니다. Next sentence로 조건을 걸어주게 되면, Discriminator가 수행하는 것은 diff operation을 수행하지 않는 것으로 볼 수 있어 필연적으로 equivariant contrastive learning도 못한다는 것을 알 수 있습니다. 오른쪽 table을 확인해보시면, Next sentence를 적용한 조합은 되려 성능이 떨어지는 것을 볼 수 있습니다. 다음 ablation은 pretraining task에 다른 조건을 걸어주는 것입니다. Discriminator에서 replaced/original 이진 분류 문제 말고 MLM 목적함수나 Corrective Language Modeling을 pretraining task로 설정했을 때의 성능을 파악해봤습니다. 이 역시도 모델의 성능 향상은 확인할 수 없었습니다.

다음은 generator에서 augmentation 방법을 MLM token replacement 말고 insertion / deletion / randomly replace로 적용했을 때의, 성능을 확인해봤습니다. 이 역시도 MLM 기반으로 Augmentation을 진행했을 때, 모든 task에서 가장 좋은 성능이 나왔습니다. 다음은 sentence encoder에서의 pooler choice를 다르게 함으로써 성능 비교를 해봤습니다. SimCSE는 단순히 BERT의 마지막 층에서 feature를 추출하여 contrastive loss를 계산했고, DiffCSE는 CV에서 자주 사용되는 방법으로 batch 정규화가 적용된 2개의 pooler를 추가하여 활용해봤는데, 다음 결과를 확인해보시면 BatchNormalization이 적용된 Diffcse가 모든 task에서 가장 좋은 성능을 보였습니다.

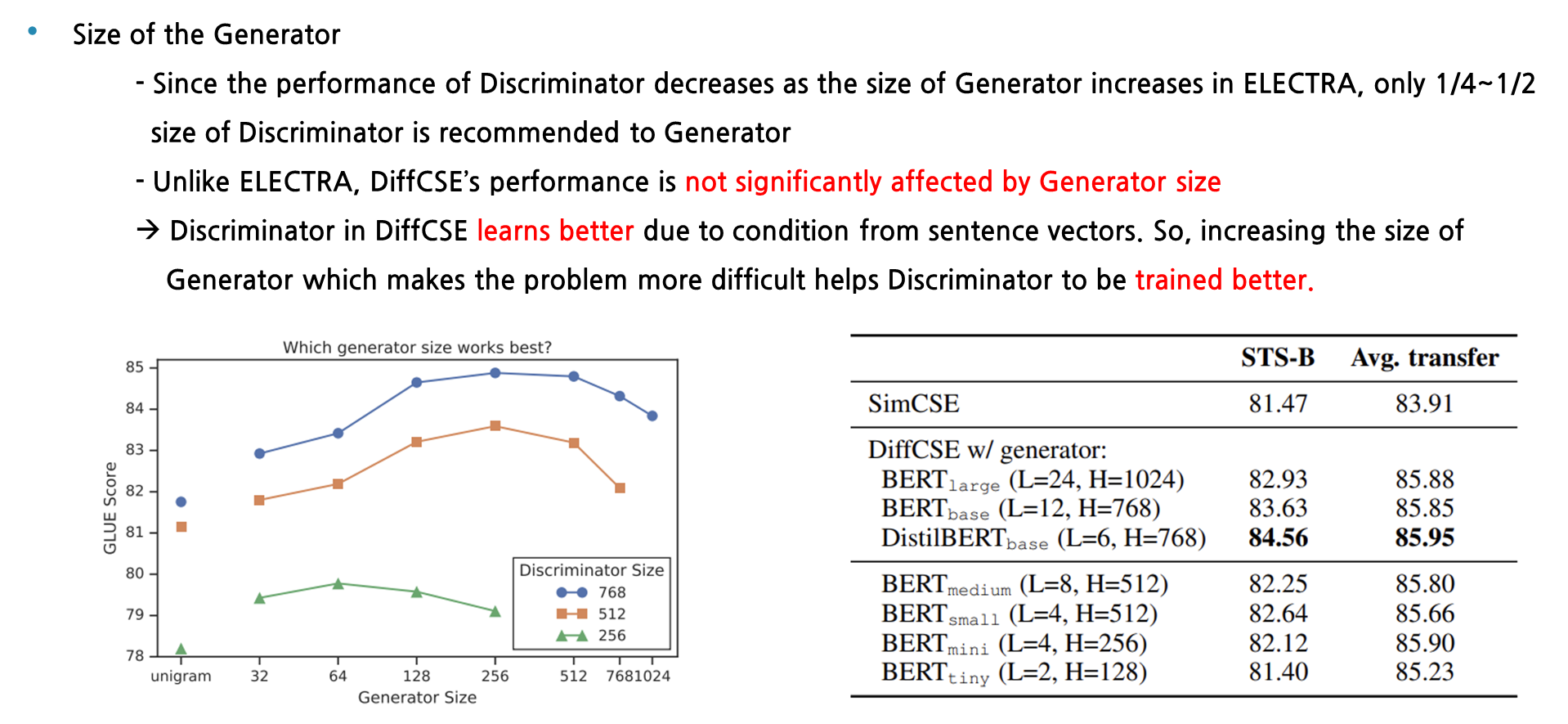
다음은 Generator의 크기에 따라 다양한 실험을 해본 것입니다. 원래 ELECTRA 논문에 따르면 좌측 하단에 보이는 그림과 같이 generator의 크기는 discriminator의 ¼~1/2가 적정한 크기로 보고 있습니다. 왜냐하면 generator의 크기가 커졌을 때, discriminator가 수행하게 되는 문제의 난이도가 너무 어려워져서 학습이 잘 안되기 때문입니다. 하지만 DiffCSE에서 사용되는 discriminator는 generator의 크기에 크게 영향을 받지 않는 것으로 설명이 되는데, 이는 DiffCSE가 sentence encoder로부터 hidden vector를 입력으로 받아 binary classification task를 더 잘 수행할 수 있는 능력을 갖췄기 때문입니다. 그래서 본래 Electra와는 반대로 Generator의 크기가 커져 문제를 어렵게 만들어줄수록 discriminator는 더욱 잘 학습을 할 수 있다고 볼 수 있습니다.
다음은 generator에서 masking을 거는 비율에 따른 성능입니다. Ratio마다 성능의 큰 차이는 없었지만, 30%로 정했을 때 가장 좋았다는 것을 확인할 수 있었습니다. 마지막 ablation study는 total loss에서 RTD loss에 적용되는 람다 값입니다. Contrastive learning이 RTD task보다 대체로 학습하기에 더욱 쉽기 때문에, 생성되는 loss의 크기는 차이가 많이 납니다. 그래서 이 둘의 loss의 균형을 맞추고자 람다 값을 작게 설정을 해야하고, 실험적으로 람다가 0.005일 때 성능이 제일 좋게 나왔습니다. 그리고 아까 앞에서 말씀 드린 바와 같이 람다가 0이면 RTD loss term은 사라지기에 total loss는 단순히 Contrastive loss와 동일하게 되어서, SimCSE와 같아집니다.

Analysis
다음은 DiffCSE와 SimCSE 간의 정성 평가에 대한 결과를 같이 확인해보겠습니다. 첫번째, 두번째 query에 대해서는 DiffCSE가 비슷한 문장을 잘 도출을 하였지만, SimCSE는 semantic한 관점으로 보았을 때 사뭇 다른 의미의 문장을 보였습니다. 하지만 세번째 query, “I think it’s a good idea” 문장에 대해서는 DiffCSE와 SimCSE 둘 다 반대되는 의미를 나타냈습니다. 이렇게 이중 부정이 적용된 문장에 대해서는 아직까지 sota 모델도 semantic한 의미를 뽑아내는 것에 있어서는 해결하지 못한 한계점이라고 생각을 합니다.

다음은 해당 정성평가와 같은 실험을 정량평가로 판단하기 위해 top -1개의 문장 5개의 문장 그리고 10개의 문장을 뽑았을 때의 recall값을 확인해봤습니다. 확실히 DiffCSE가 SimCSE보다 좋은 성능을 보인 것을 확인할 수 있습니다.

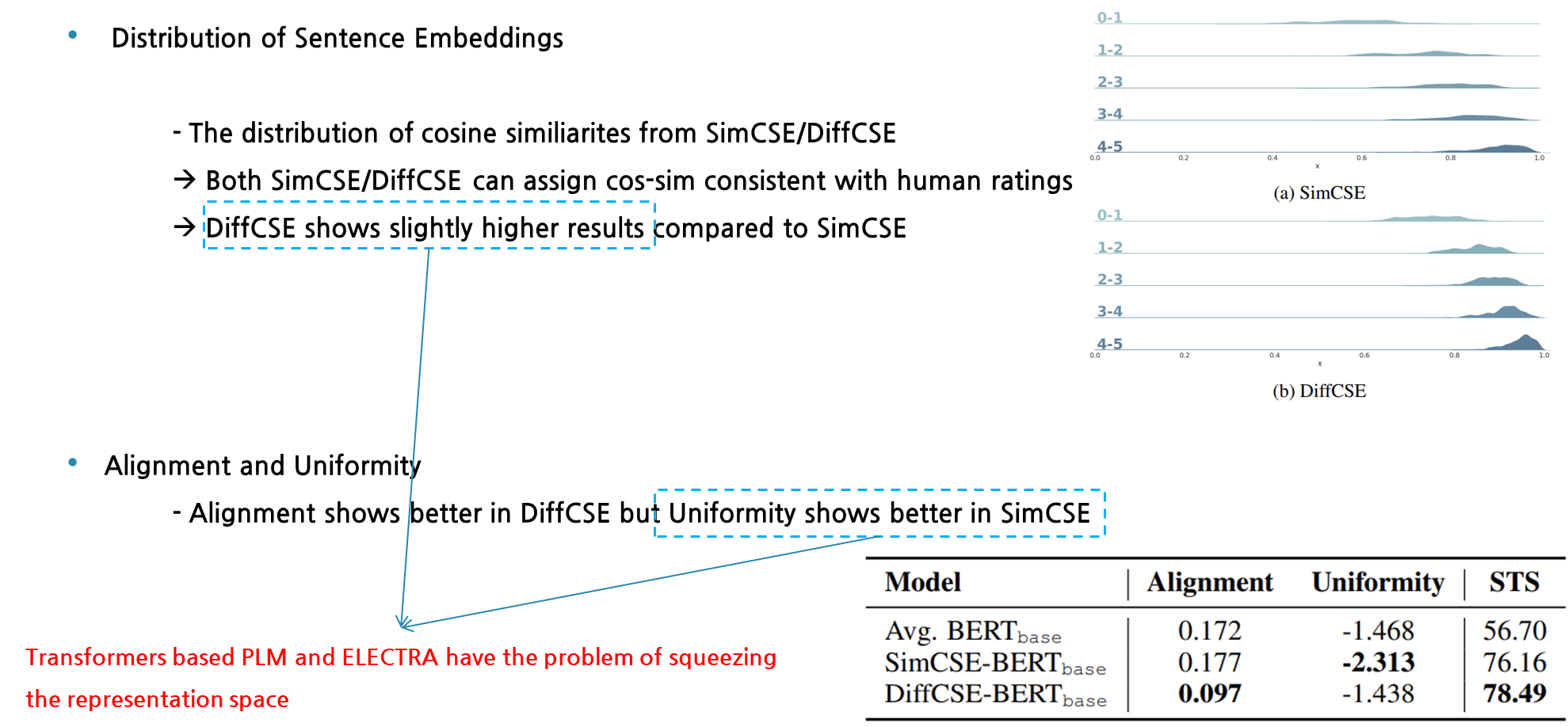
다음은 문장 임베딩에 대한 분포를 알아보는 실험을 진행해봤습니다. SimCSE와 DiffCSE는 둘 다 사람의 평가와 비슷한 코사인 similarity 분포를 갖는데, DiffCSE가 SimCSE보다 전반적으로 높은 값을 취하는 것을 확인할 수 있습니다. 또한, 두 모델 간의 alignment와 uniformity의 비교실험도 진행해봤습니다. DiffCSE는 alignment가 더 낮은 값을 보이며 우수한 것을 보이는 반면에 Uniformity 척도에서는 SimCSE가 좋은 성능을 보였습니다. 위 두 실험에서 DiffCSE가 SimCSE보다 높은 cos-sim 값을 보인 점과 SimCSE보다 uniformity 성능이 낮게 측정된 이유는, SimCSE는 transformer 기반의 encode로 나온 벡터가 discriminator로 입력으로 들어가 representation이 squeezing되었기 때문이라고 추측할 수 있습니다. 이렇게 transformer 계열의 모델들의 한계점은 representation이 squeezing 됨에 따라 uniformity가 낮아지는 것이 이전 연구들에 의해 밝혀졌었습니다. Contextualized Representation이 transformer 계열 모델에서 low layer에서는 isotropic한 성질을 갖는 반면에 higher layer로 갈수록 anisotropic한 성질을 갖는 현상이 있다는 것을 생각하시면 될 것 같습니다. 따라서, DiffCSE도 이러한 모델들을 base로 깔고 있기에 위와 같은 결과가 필연적으로 나온 것으로 보여집니다.
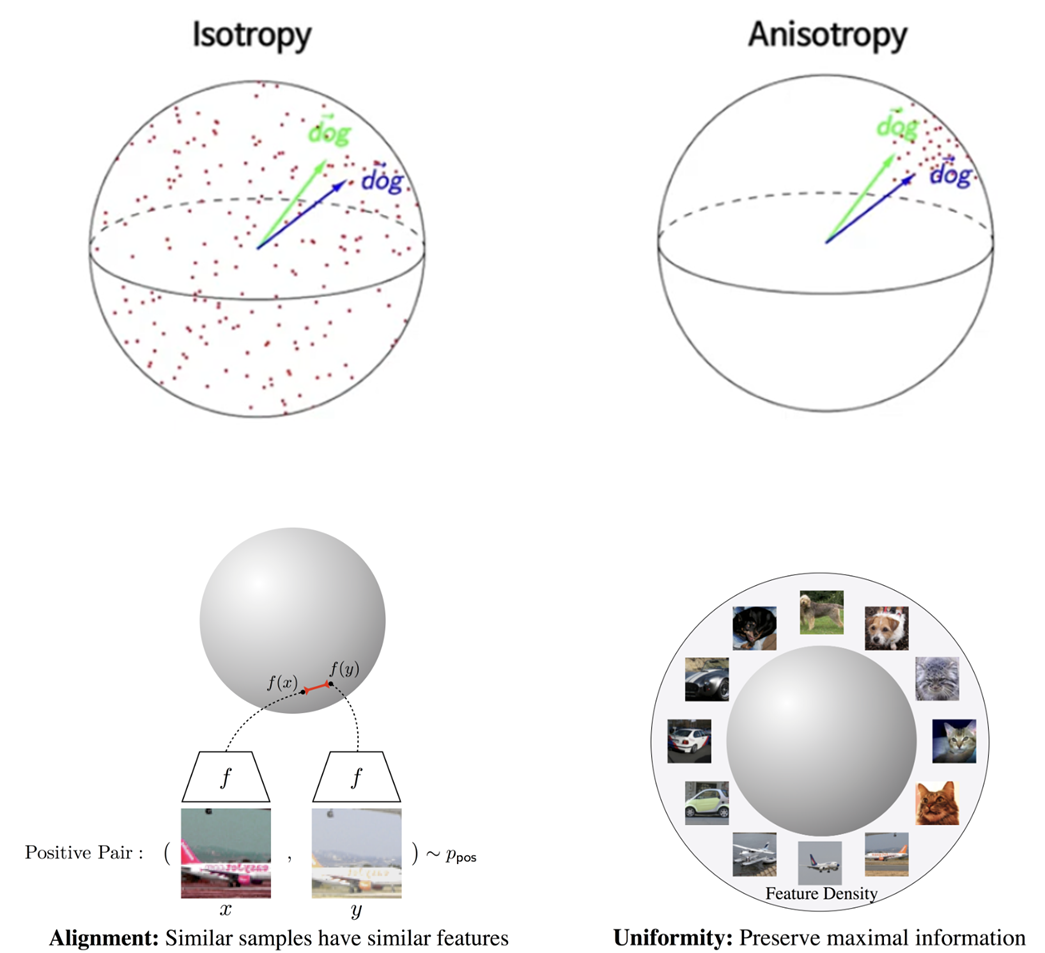
마지막에 Alignment와 uniformity의 척도를 기준으로 모델을 평가했는데, 이 둘의 개념에 대해 간략하게 설명드리겠습니다. 이 역시 주로 CV분야에서 활용된 개념이며, 먼저 alignment는 비슷한 특징을 갖고 있는 표본들은 구와 같은 모형을 갖는 가설 공간에서 비슷한 위치에 존재한다는 의미이고, uniformity는 feature가 서로 다른 표본들은 균일하게 분포 된것을 의미합니다. 따라서 alignment가 낮을수록 비슷한 표본들이 모여있기에 좋은 성능을 의미하고, uniformity가 낮을 수록 표본들이 균일하게 존재하기에 좋은 성능을 의미한다고 볼 수 있습니다.
Conclusion
해당 논문은 비지도학습 기반 문장 임베딩 framework인 DiffCSE를 소개했습니다. 이 framework는 STS와 transfer task에서 다른 방법론과 비교하여 SOTA 성적을 기록을 하였습니다. 하지만 이 논문에서는 SimCSE와 같이 NLI dataset을 활용하며 지도학습 기반 방식의 실험을 진행하지는 않았기에 추후 다른 연구원들이 시도해볼만한 과제로 남겨진 것 같습니다. 마지막으로 이 framework는 NLP에서 새로운 data augmentation을 소개했다고 볼 수 있어 유의미한 contribution을 남겼다고 볼 수 있습니다. 이 연구는 다양한 실험과 ablation study를 통해 해당 framework의 의의를 밝힌 훌륭한 논문이라고 생각이 들었습니다.

Reference

